Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 升级数据库,怎么样能做到既安全又高效?TiDB 升级策略和实战指南!
Author: Li Wenjie, TiDB Community Moderator, TiDB Community South China Organizer
Recommendation:
When facing the critical and sensitive operation of database upgrades, this article provides comprehensive strategies and steps to ensure the upgrade process is both safe and efficient.
Whether choosing an in-place upgrade or a full migration upgrade, the article details the pros and cons and applicable scenarios of each, helping readers make the best decision based on their needs. Especially for high-demand, non-downtime financial-grade scenarios, the article introduces a bidirectional synchronization gray migration upgrade solution to ensure a smooth upgrade process and data consistency.
With these carefully designed strategies, readers can confidently tackle the challenges of database upgrades, ensuring business continuity and stability.
Recommended for all professionals needing to perform database upgrades to ensure your system upgrades are both safe and efficient.

I. Introduction
As the core storage layer of application systems, any slight disturbance in the database can affect the online customer experience. Upgrade operations inevitably involve heavy operations such as starting and stopping, making it a very sensitive and dangerous operation for the entire upstream and downstream systems.
In addition, a lot of time and effort is required to evaluate the benefits of the upgrade before proceeding, such as fixing database bugs or security vulnerabilities, using new features, etc. The business side also needs to conduct extensive compatibility and performance verification work in advance. For the entire team, upgrading the database is not considered unless absolutely necessary. However, there will always be situations where an upgrade is unavoidable, and for these scenarios, we have different upgrade strategies.
II. TiDB Upgrade Strategies

When upgrading a TiDB cluster, we generally have the following upgrade strategies:
- In-place upgrade
- Migration upgrade
For in-place online upgrades and in-place offline upgrades, the official website provides detailed instructions, which can be directly referenced at 使用 TiUP 升级 TiDB | PingCAP 文档中心.
III. Full Migration Upgrade
To perform a full migration upgrade, we need to replicate and deploy a new cluster that is not inferior to the cluster to be upgraded.
What does “not inferior to” mean? It mainly involves two aspects:
- One aspect is that the capacity space can accommodate the data.
- The other is that the access performance can meet business requirements.
This solution allows for rollback operations in very sensitive and error-free scenarios. It also does not require the topologies of the front and back clusters to be consistent, meaning that the migration upgrade method can also be used to adjust the overall architecture, migrate data centers, replace cluster hardware in batches, replace operating systems in batches, etc., and is safer and more reliable than scaling.
As shown in the figure below, the overall architecture of the migration upgrade involves deploying a new cluster, setting up forward real-time incremental synchronization after importing the base data, and establishing a master-slave cluster. During migration, stop business access to the main cluster, verify data consistency between upstream and downstream, stop forward synchronization, start reverse synchronization, and then switch business access to the downstream slave cluster to complete the migration upgrade.
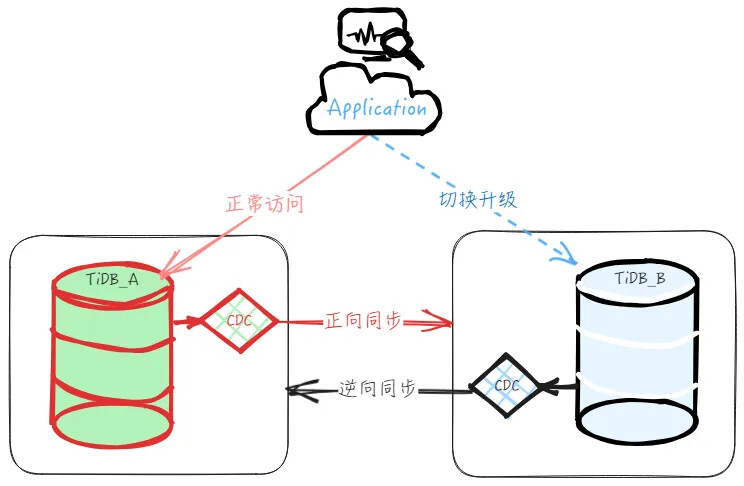
The specific steps are as follows:
- Set up master-slave synchronization
- Migrate users and permissions.
- Migrate SQL Bindings.
- Migrate scheduled tasks: such as scheduled statistical analysis scripts, data backup scripts, scheduled analyze scripts, etc.
- Base data: If the data volume is in the GB range, use Dumpling+Lightning to migrate the base data. If the data scale is in the TB range, it is recommended to use BR for backup and restore to the downstream cluster. After restoring the base data, use the sync_diff_inspector tool to verify data consistency between the upstream and downstream clusters.
- Incremental data: If the upstream cluster version is after v4.0.16, deploy the TiCDC cluster for real-time incremental synchronization. For older versions, use the TiDB Binlog tool Pump+Drainer to set up real-time master-slave synchronization.
- Observe for a period, periodically using sync_diff_inspector to check data consistency between the upstream and downstream clusters. You can also develop a checking tool for quick consistency verification to avoid the long time required for full data verification with sync_diff_inspector.
- The business can fully verify the compatibility and performance of the new version on the slave cluster, identifying and fixing issues in advance. If testing contaminates the data, rebuild the master-slave cluster before going live according to the above steps.
- Deploy a new cluster based on the data volume scale and growth rate of the upstream cluster, as well as the access QPS performance requirements.
- Pre-set cluster parameters: inherit specially adjusted parameters from the upstream, set new version feature parameters, etc.
- Deploy the new cluster: the front and back topologies can be different.
- Set up the master-slave cluster: configure forward synchronization.
- Migrate surrounding auxiliary businesses in advance.
- Full migration upgrade
- Confirm the migration upgrade time window with the business, and make an announcement in advance.
- Stop business services. If necessary, lock or reclaim read-write permissions of the upstream cluster, ensuring no business access requests.
- Confirm data catch-up and master-slave consistency.
- Stop forward synchronization.
- Switch business access to the downstream database.
- Start the business, confirming that requests normally read and write to the downstream cluster.
- Business verification
- Confirm normal reverse synchronization, periodically checking data consistency between upstream and downstream. Observe for a period.
- Emergency rollback: switch traffic back to the old cluster
- If the business confirms an issue that cannot be resolved in a short time, implement the rollback plan.
- Stop business access to the slave cluster.
- Reauthorize business read-write permissions to the upstream cluster.
- Confirm data catch-up and master-slave consistency of reverse synchronization.
- Switch business back to the upstream main cluster, and start the business.
- Further investigate and fix issues, then schedule the next switch upgrade operation.
The above operations treat the business application as a whole for switch upgrades. During migration, the entire business will have a short downtime window, during which business services are unavailable.
In more sensitive or higher-demand scenarios, such as paid services, where downtime windows or complete business traffic unavailability are not allowed, consider the gray cutover solution, gradually migrating application traffic in batches to complete the upgrade. The specific bidirectional synchronization solution is as follows:
IV. Bidirectional Synchronization Gray Migration Upgrade
For sensitive or high-demand businesses where complete business unavailability is not allowed, adjust the business itself, modularizing it to support batch gray switching. This allows for modifications to the full migration upgrade plan, achieving gray migration upgrades for safer database upgrades.
In this scenario, we can discuss the bidirectional synchronization migration upgrade plan.
The premise of bidirectional synchronization between two clusters is that data written to both clusters must be conflict-free. This requires the business side to manage and ensure access isolation, theoretically preventing simultaneous modifications to the same row in the same table in both clusters. Practically, business traffic needs to achieve access isolation at the database or table level for the plan to be feasible.
The specific operations for bidirectional synchronization gray migration upgrade are roughly as follows:
- Business modification
- Modify the business vertically based on its characteristics, enabling modular deployment (microservices), and achieving access isolation between databases or tables.
- Optimize the modular deployment of the business online.
- Set up master-slave synchronization
- This step is similar to the full migration upgrade steps mentioned above and will not be repeated here.
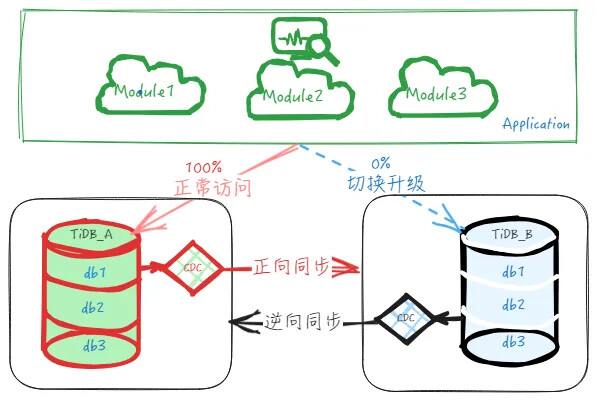
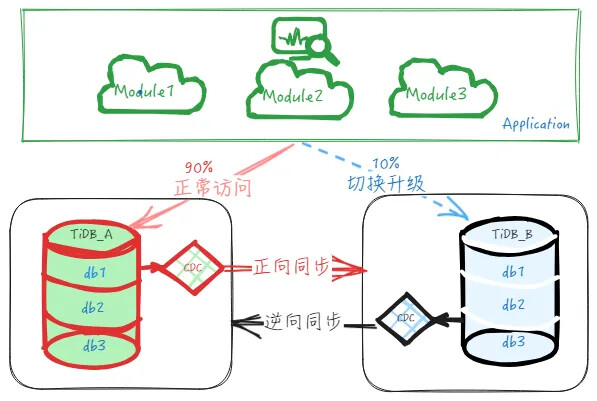
(Continuous migration…)
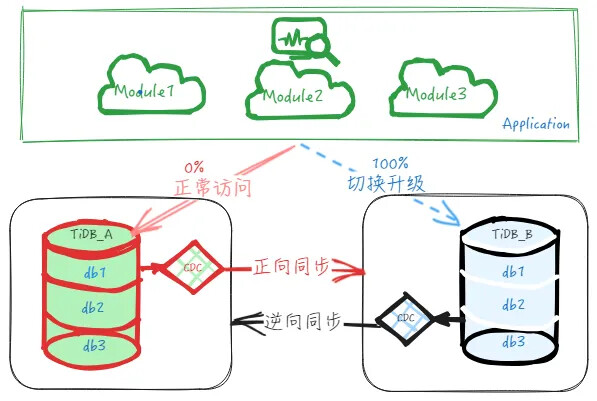
- Gray migration upgrade
- Continuously confirm normal forward and reverse synchronization, periodically checking data consistency between upstream and downstream for rollback preparation.
- Track and verify the accuracy of migrated business. If any issues cannot be resolved in a short time, roll back. If no issues, continue observing for a period (usually in days).
- After stable operation of migrated business for a period, start the second batch migration upgrade task, migrating other modules to the downstream cluster. Increase migrated business traffic from 10% to 20% (actual traffic share determined by business), then continue verification and observation. Fix or roll back if issues arise, continue if normal.
- Continue migrating remaining modules, verifying and observing step by step until 100% of business traffic is migrated to the downstream cluster.
- Initially, migrate relatively less important modules or partial traffic to the downstream, as shown in the diagram. Migrate 10% of business traffic accessing database db1 to the downstream TiDB_B’s db1, with no direct business access to the upstream TiDB_A, only handling reverse synchronized data.
- Confirm the time window for modular migration upgrade with the business, ensuring normal forward and reverse synchronization.
- Emergency rollback: switch traffic back to the old cluster
- If migrated business confirms an issue that cannot be resolved in a short time, implement the rollback plan.
- Stop migrated business access to the slave cluster.
- Reauthorize business read-write permissions to the upstream cluster.
- Confirm data catch-up and master-slave consistency of reverse synchronization.
- Switch business back to the upstream main cluster, and start the business.
- Further investigate and fix issues, then schedule the next switch upgrade operation.
For details on TiCDC bidirectional replication, especially the impact of DDL on business, refer to the official documentation: TiCDC 双向复制 | PingCAP 文档中心.
V. Summary
Database upgrade operations are high-risk and need to be evaluated based on actual conditions, considering the database environment (testing, production), business type (offline, online), whether there is a downtime window, and sensitivity. Assess risks and benefits comprehensively before proceeding.
In summary, adopting a steady, gradual approach to upgrade operations is the appropriate course of action.