Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: kyuubi-tispark 的sql如何使用.mode(“append”)
To improve efficiency, please provide the following information. A clear problem description will help resolve the issue faster:
[Overview] How to use insert into and insert overwrite in kyuubi + tidb mode
[Application Framework and Business Logic Adaptation]
[Background]
Using kyuubi + tispark + tidb for data processing
[Phenomenon]
There are primary key issues and errors in these two cases,
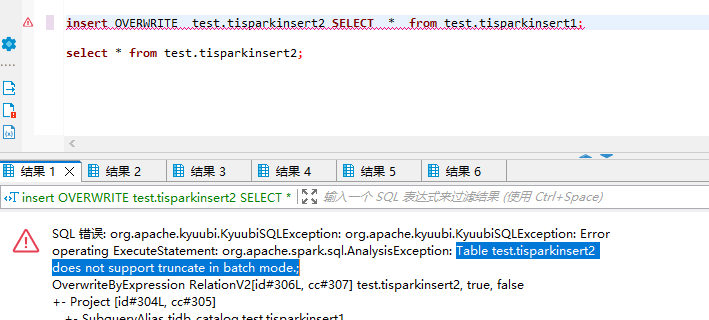

Inserting into a table without a primary key is normal.
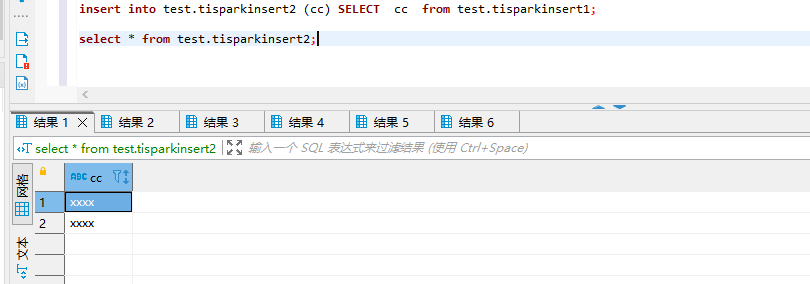
After searching for information, enabling batch mode, and in submit mode, you can use the following method

How can I use batch mode by submitting SQL through kyuubi?
[Problem] Current issues encountered
How to solve the batch mode insert method under kyuubi
[Business Impact]
[TiDB Version] 6.5.6
[Attachments] Relevant logs and monitoring
SQL Error: org.apache.kyuubi.KyuubiSQLException: org.apache.kyuubi.KyuubiSQLException: Error operating ExecuteStatement: org.tikv.common.exception.TiBatchWriteException: currently user provided auto id value is only supported in update mode!
at com.pingcap.tispark.write.TiBatchWriteTable.preCalculate(TiBatchWriteTable.scala:179)
at com.pingcap.tispark.write.TiBatchWrite.$anonfun$doWrite$7(TiBatchWrite.scala:199)
at scala.collection.immutable.List.map(List.scala:293)
at com.pingcap.tispark.write.TiBatchWrite.doWrite(TiBatchWrite.scala:199)
at com.pingcap.tispark.write.TiBatchWrite.com$pingcap$tispark$write$TiBatchWrite$$write(TiBatchWrite.scala:94)
at com.pingcap.tispark.write.TiBatchWrite$.write(TiBatchWrite.scala:50)
at com.pingcap.tispark.write.TiDBWriter$.write(TiDBWriter.scala:41)
at com.pingcap.tispark.v2.TiDBTableProvider.createRelation(TiDBTableProvider.scala:94)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:47)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:98)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated