Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: kv leader数量不均衡
[TiDB Usage Environment] Production Environment
[TiDB Version] 5.3.2
[Encountered Issue] Uneven distribution of kv node leaders, querying certain specific tables results in region unavailable errors.
[Reproduction Path] Unable to determine
[Issue Phenomenon and Impact]
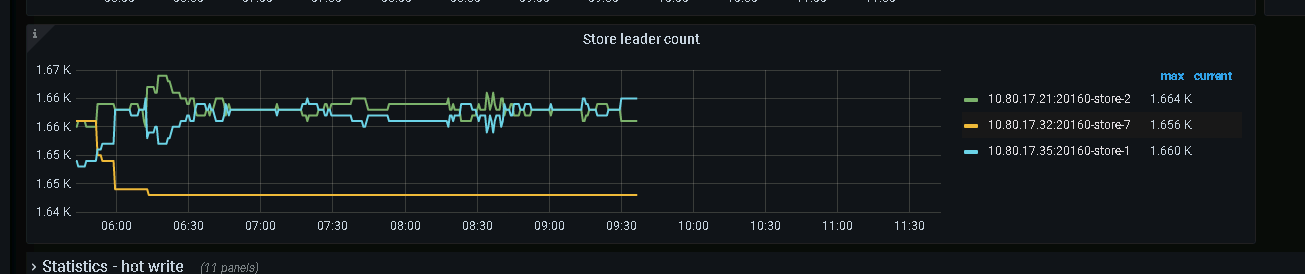
Observed from kv monitoring that there is an issue with the number of leaders, the nodes cannot return to a balanced state, and almost all leaders are received by 32 nodes.
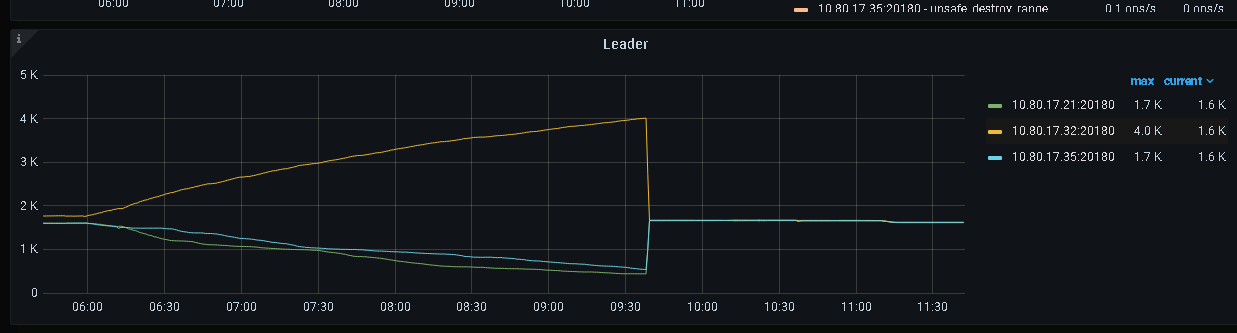
From the PD monitoring page, it is observed that leader migration occurred during this period. The distribution of kv leaders seen from the PD leader node monitoring panel is inconsistent with the distribution seen in kv monitoring, which seems to cause the 32 nodes to continuously receive leaders transferred from the other two nodes.
Why does this situation occur? This issue has occurred several times before, and it can be temporarily resolved by restarting the server where the PD node is located, but the reason for the uneven distribution of kv leaders (or the incorrect distribution of kv leaders read by the PD node) has not been found.
The current speculation is related to disk reads (unable to read or too slow to read), and there is no significant abnormality or interruption in network latency between nodes.
[Attachments]
Leader distribution in kv monitoring panel:
Leader distribution in PD monitoring panel:
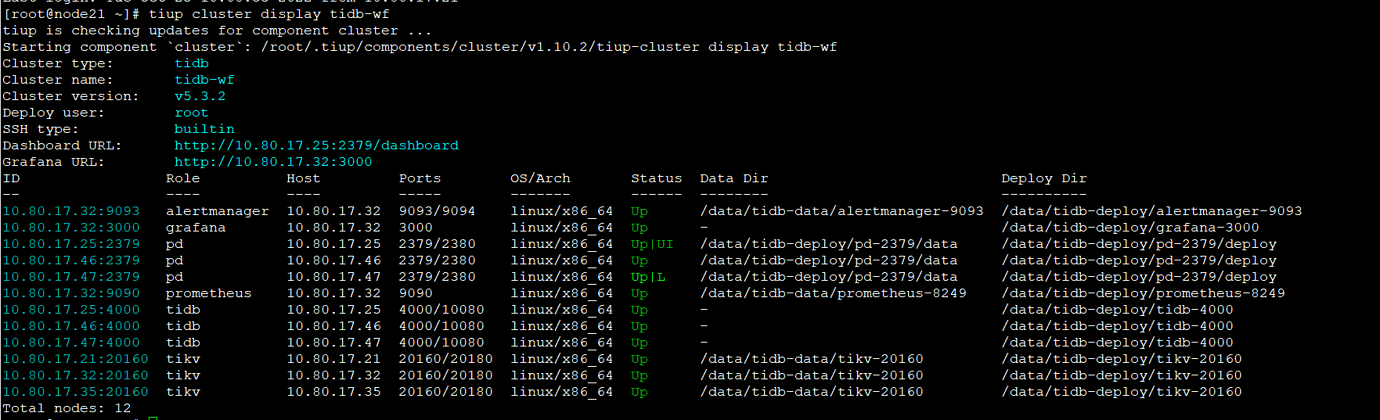
TiUP Cluster Display Information
Logs from two PDs around 5 o’clock
Follow these steps to export the monitoring data for PD, TiKV, Overview, and Node Exporter. Make sure to expand all panels and wait for the data to fully load. Are there any scheduled tasks at 6 o’clock?
Following with interest, learning how to analyze.
Actually, since 3 AM, there have been some statistical SQLs running, including some relatively complex group by query logic and million-level insert logic. I will export the logs later.
pd and node exporter have no data. You need to wait for the data to load completely before exporting the file. You can scroll to the bottom and wait for a while. Export the TiKV detail for TiKV. Also, please upload the tikv.log for the 32-node cluster around 6 o’clock.
There are several nodes in node exporter that seem to be unable to export data.
tidb导出json新.rar (4.0 MB)
tikv-32-cut.txt (6.1 MB)
Here are the issues observed:
- At 5:01, there was a PD leader switch, and node 25 became the leader, likely due to slow disk issues.
[2022/10/25 05:00:30.858 +08:00] [WARN] [wal.go:712] [“slow fdatasync”] [took=2.426173237s] [expected-duration=1s]
[2022/10/25 05:00:30.858 +08:00] [WARN] [raft.go:363] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=a8a1d6bded45bf4b] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=1.471525001s]
During the time it became the leader, many monitoring items on PD had no data. There should be an issue with communication with TiKV.
[2022/10/25 05:01:30.546 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“[PD:grpc:ErrGRPCRecv]rpc error: code = Canceled desc = context canceled”]
- During the period when node 25 was the leader, the transfer leader scheduling from store2 (17.21) and store1 (17.35) to store7 (17.32) could not be completed normally and timed out, which is suspected to be related to TiKV being busy. However, subsequent scheduling from store7 to stores 1 and 2 was successful.
The specific reasons will be analyzed by the official experts @neilshen.
Thank you for the analysis.
Regarding the first point, looking at the disk monitoring, the disk latency is relatively high, and all three store nodes have relatively high latency. This is also related to the logic of the scheduled tasks being executed, putting considerable pressure on the disk. It is very likely that this is what caused the PD leader switch.
Regarding the second point, if the scheduling from store2 and store1 to store7 cannot be completed normally, why is the number of leaders on store7 increasing? (From the KV monitoring panel, it can be seen that the number of leaders on store2 and store1 is decreasing, while the number of leaders on store7 is increasing.) In the PD logs, after the PD leader switched to node 25, node 25 issued many transfer leader schedules. What is the reason for initiating these schedules?
Or is it that the PD received a transfer leader scheduling failure, so the PD node 25 always considers the number of KV leaders on store 7 to be low, thereby continuously initiating new scheduling, ultimately causing the store 7 node to continuously receive leaders transferred from the other two store nodes?
The transfer leader is mainly due to balanced scheduling. Why is there a timeout? You can upload the tikv.log of those two nodes to take a look.
The logs of the other two store nodes.
Let’s wait for the official experts to take a look.
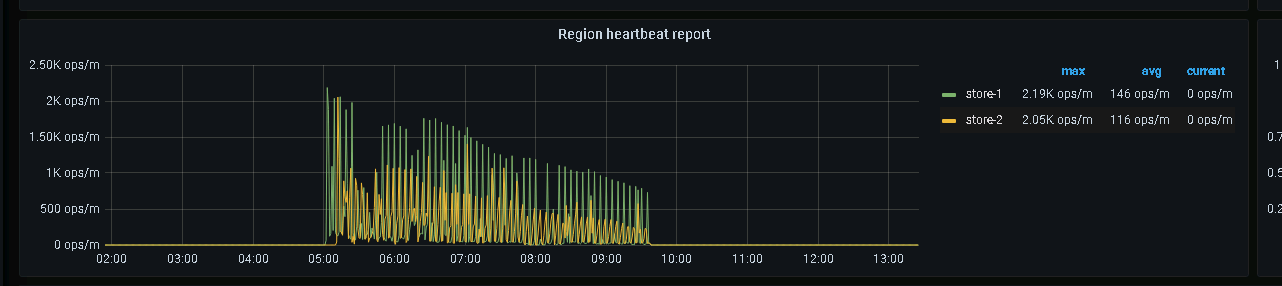
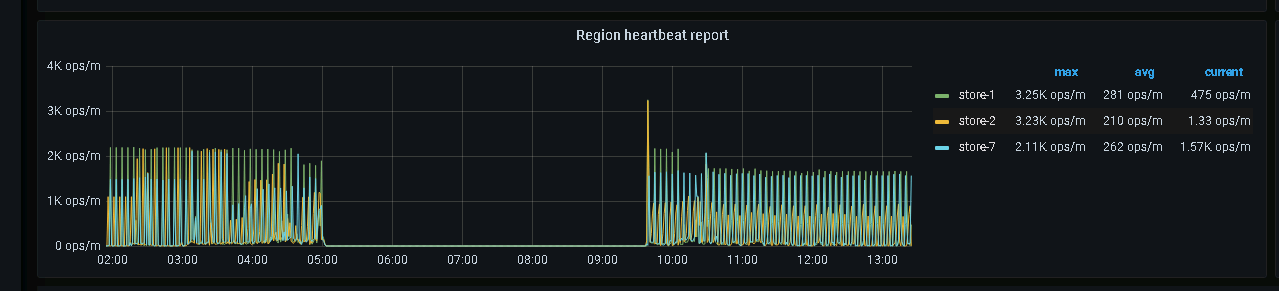
Thank you for the guidance. From the release notes, it seems to match the situation we encountered. Looking at the region heartbeat report panel, indeed, after the PD leader switched to node 25, the region heartbeat of store 7 has not been received. Before and after the PD leader switched to node 25, the heartbeats of the three store nodes were normal.
We will upgrade the TiDB version later and follow up to see if this issue will recur.
Impressive, it’s time for another upgrade.
Update: After upgrading TiDB on October 27th, the issue has not reoccurred. During this period, the PD leader has undergone at least four leader switches.
Try not to reply with irrelevant content to resolved issues, as this will bring the previously resolved issues back to attention, causing confusion for those who helped solve the problem and distracting others.