Author: Wink Yao
The TiDB Hackathon 2023 just ended. And I carefully reviewed almost all the projects. While not explicitly emphasizing the use of artificial intelligence (AI), the remarkable projects almost unanimously use AI to build their applications. The emergence of Large Language Models (LLM) has empowered individual developers to incorporate reasoning capabilities into their programs in just 5 minutes, a task that previously appeared achievable only for large teams. From the perspective of application developers, the era of AI has arrived. In these AI applications, the presence of vector databases is ubiquitous. While these projects still rely on relational database, its role seems to have become less prominent.
Do developers still need relational databases? To provide a clear answer, we must comprehend the distinctions between vector databases and traditional relational databases.
What is a vector database?
To answer this question, I spent some time learning vector databases. Here, I would like to simply explain what a vector database is. Actually, most things in this world have multiple features, such as describing a person using multiple dimensions like height, weight, personality, gender, dressing style, interests, and so on. And you can also expand these dimensions or features to describe an object more accurately if you want. The more dimensions or features, the more precise the description is. Now, let’s take an example. If we use one dimension to express emotional emojis, where 0 represents happiness and 1 represents sadness, the degree of happiness or sadness of each corresponding emotion can be represented by a number between 0 and 1 on the x-axis:

But you will find that if there is only one dimension to describe emotion emojis, it is general and not accurate enough. For example, there are many types of emojis that can express happiness. In such cases, we usually add new dimensions to describe them better. For instance, we can introduce the Y-axis, where 0 represents yellow and 1 represents white. After adding this dimension, the representation of each emoji on the coordinate axis becomes a tuple in the form of (x, y).
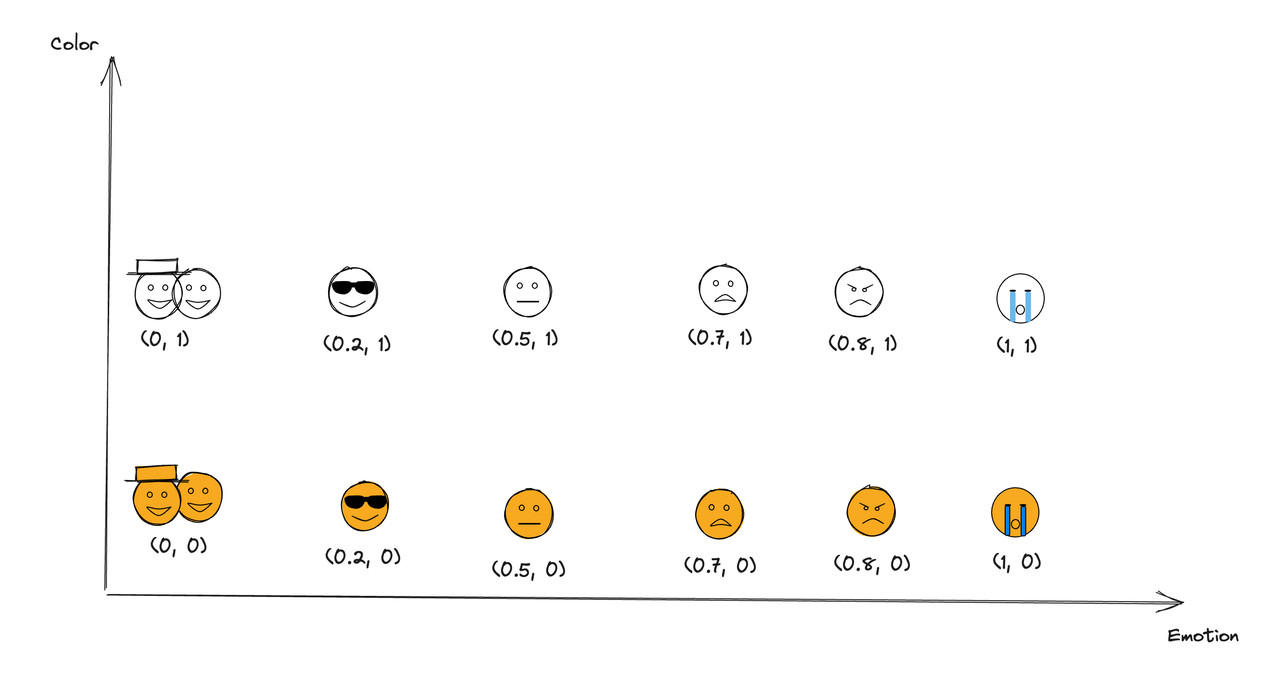
And you must have noticed that even with the addition of the Y-axis as a new descriptive dimension, there are still some emojis that we cannot distinguish. For example,
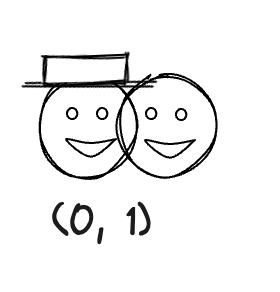
So how can we deal with this problem? The answer is that we can add another dimension. We can introduce the Z-axis to the coordinate system, like we can set the new dimension to whether the emoji is wearing a hat or not(Pay attention that the value here is as simple as possible for illustration purposes. ). And we can use 0 to represent no hat and 1 to represent wearing a hat. Therefore, we now have a three-dimensional coordinate point, (x, y, z), to describe an emoji.
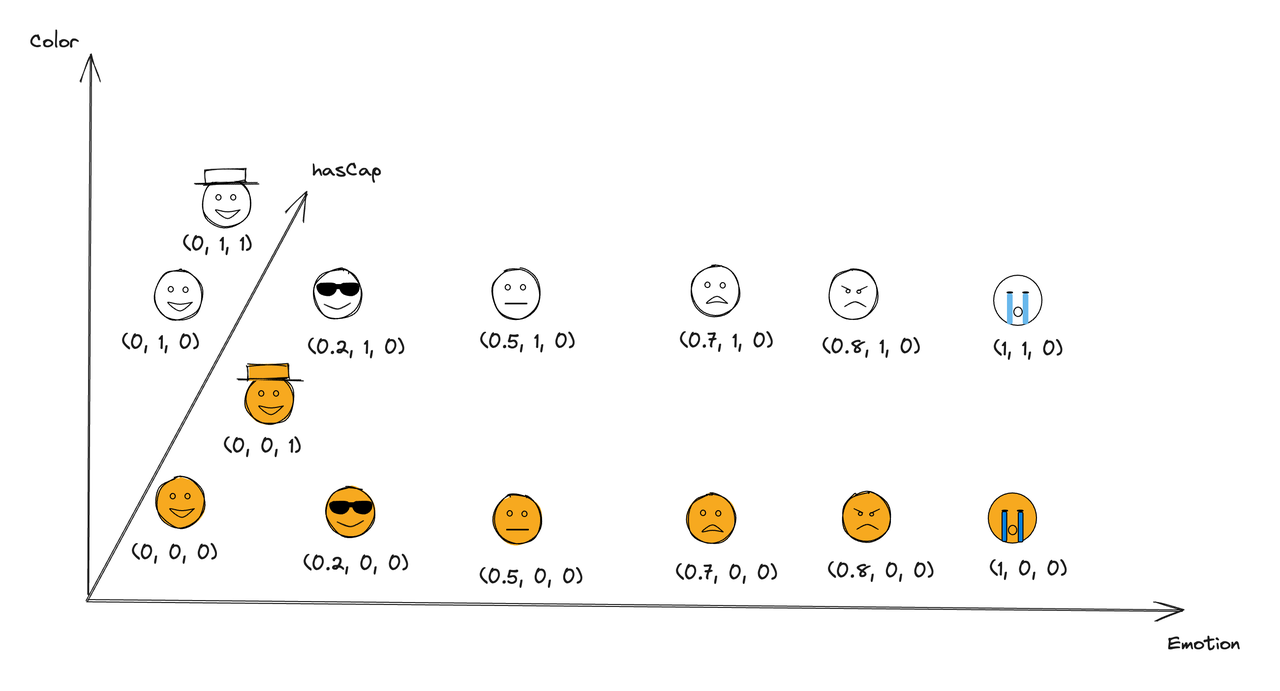
However, objects usually have more characteristics in real world, so we need to add more dimensions to describe them. This is where descriptions like high-dimensional arrays (e.g., (0.123, 0.295, 0.358, 0.222 …) come into play.
Now we can see that we are very close to the concept of “vectors” in vector databases. In fact, vector databases store these arrays to represent various types of data, including images, videos, and texts. These items are transformed into high-dimensional arrays using the method described above and then saved.
Maybe you still have some problems about the purpose and significance of vector databases. In conclusion, we are able to quantify the relationships and similarities between any two things in the world by transforming items into vectors. And items that are closer in each dimension will be closer in space. Also, by calculating the distance between two points, we can judge their similarity.
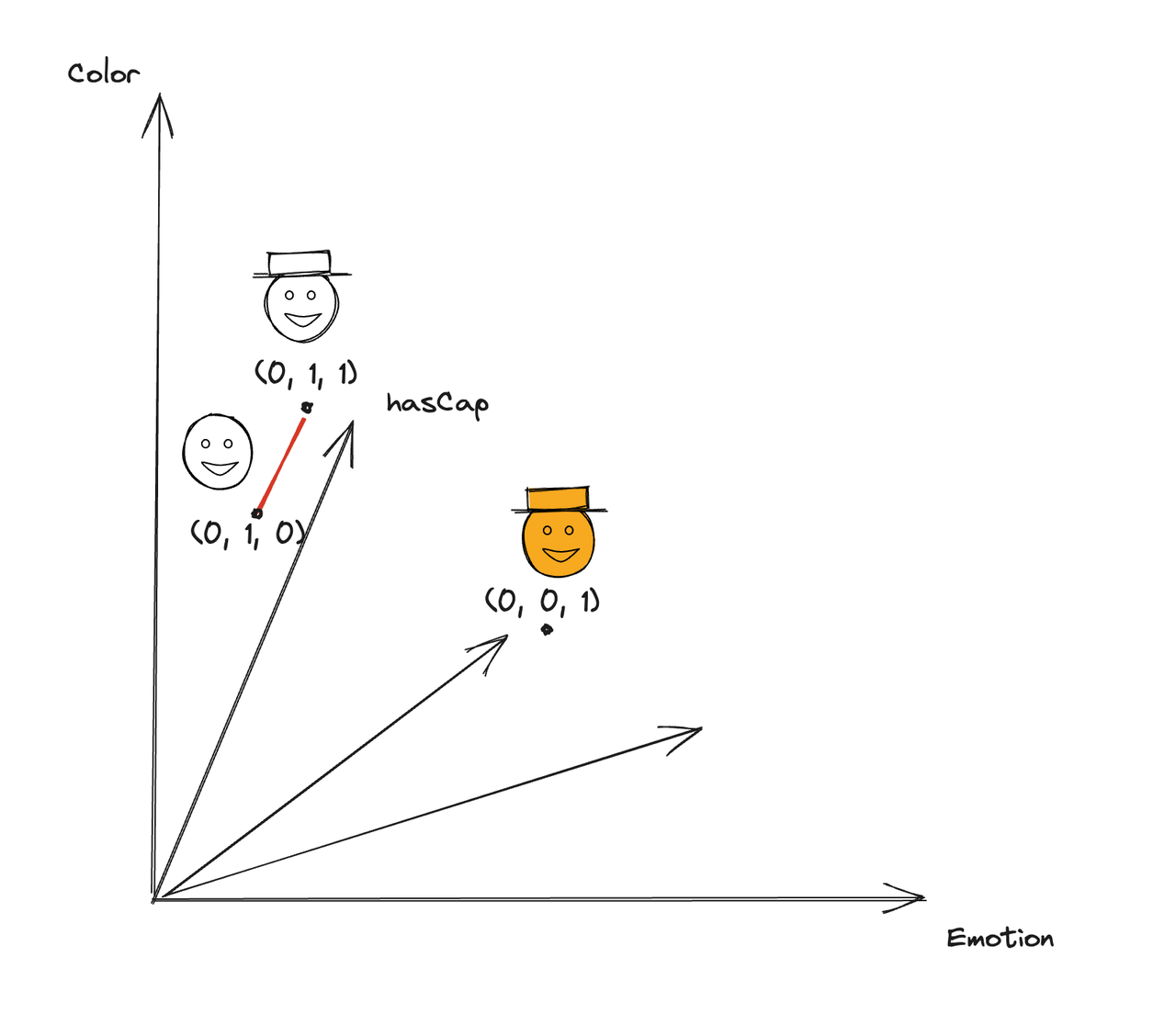
So if we have a new Emoji, we can transform it into a vector (0.01, 1, 0) , using the method described above.

By calculating the similarity with the vectors stored in the database, we can find the closest matching Emoji:

The second closest matching Emoji is like:

We can also see the data obtained by PineCone Query Data to better understand (Score here can be simply understood as similarity.)
index.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)
# Returns:
# {'matches': [{'id': 'C',
# 'score': -1.76717265e-07,
# 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
# {'id': 'B',
# 'score': 0.080000028,
# 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]},
# {'id': 'D',
# 'score': 0.0800001323,
# 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]}],
# 'namespace': ''}
“Values” refers to the retrieved vectors which can be considered as corresponding emojis. This means that we can vectorize all query conditions and find the most “similar” items to what we are looking for. If we replace emojis with text, we can achieve “semantic” search. If we replace emojis with images or videos, we can achieve similarity-based recommendations for images or videos.
Why do AI applications often rely on vector databases?
To sum up, the “Large Language Model” (LLM) used in AI applications have limited memory capacity, similar to our brains. Like during communication, we cannot provide all of our knowledge to others in every conversation. Instead, we rely on limited context to make inferences. In AI applications, this inference capability is provided by the “Large Language Model” (LLM). And the vector database can be seen as the memory of the LLM, where the most relevant context is retrieved for expression, similar to how our brains retrieve relevant information. To complete an AI-related task, without the help of a vector database, the functionality and accuracy achievable by the “Large Language Model” (LLM) would be limited.
And there are also many situations that require precise and deterministic searches or indexing in real life. This is similar to how we record important information in a notebook and use an index to precisely retrieve it when needed.
So the key difference between a vector database and a relational database lies in the storage and indexing methods for data. The presence of indexing in a relational database allows it to retrieve information corresponding to a query within milliseconds. For business systems which require high-speed access to data such as account, product, and order information, relational databases are still commonly used.
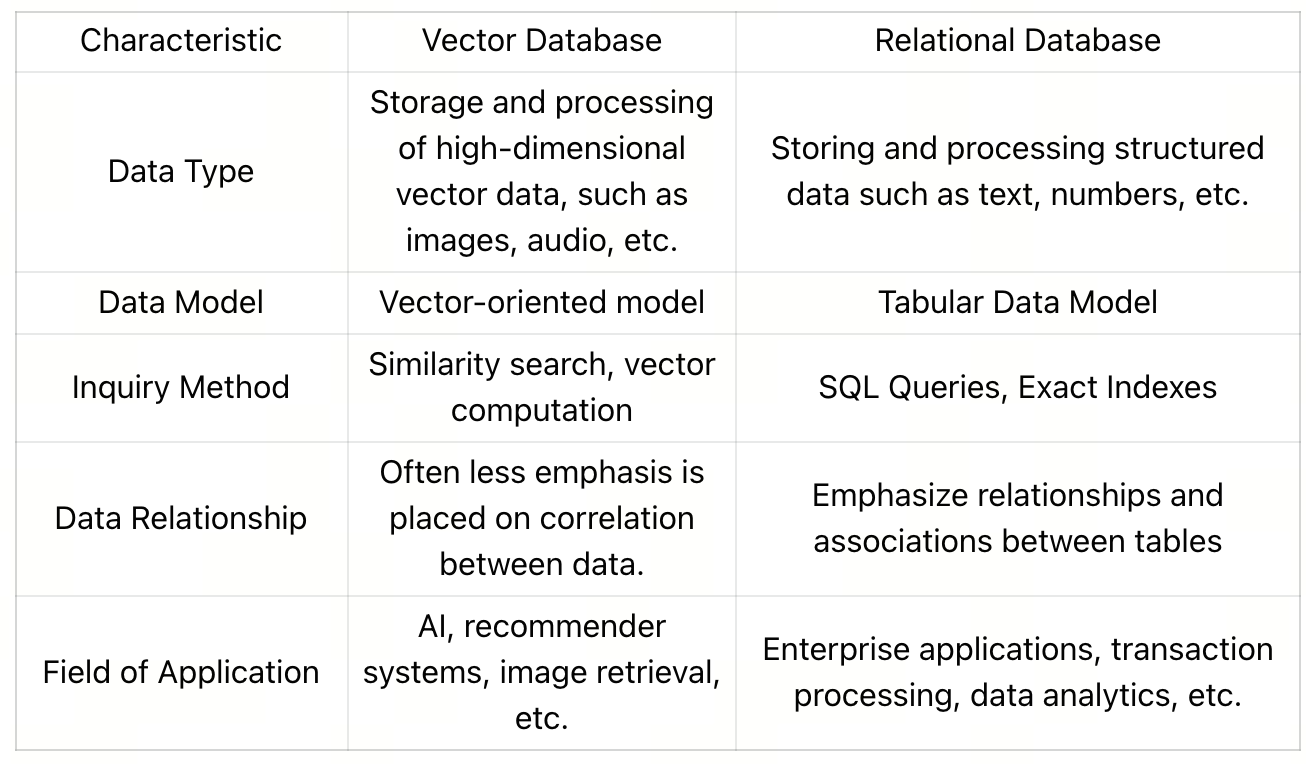
Comparison between Vector Database and Relational Database
Now, I will show you how to use these two types of databases in a real project, taking the award-winning application Heuristic AI in our hackathon as an example.
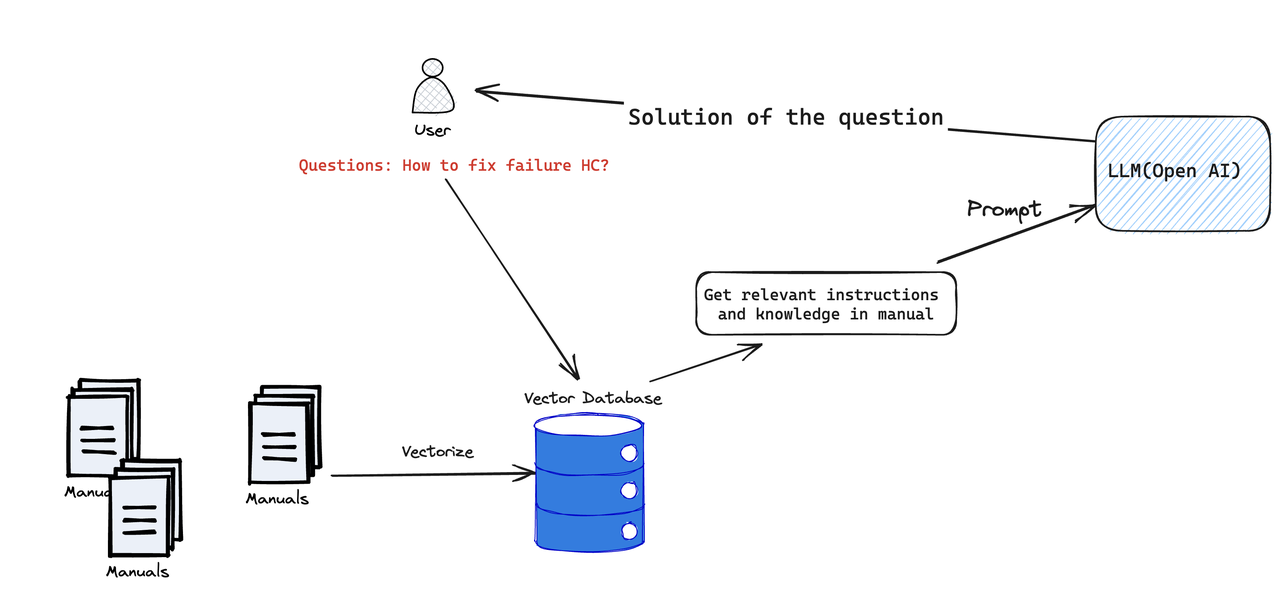
We usually need to refer to complex user manuals to find solutions when we have some problems with our electronic products in our daily life, which is time-consuming. And the Heuristic AI project accomplishes the following tasks. It imports all product manuals into a vector database, describes encountered problems in natural language, performs semantic searches to find the most relevant context in the vector database, and then packages the context as prompts to send to OpenAI for generating corresponding solutions.
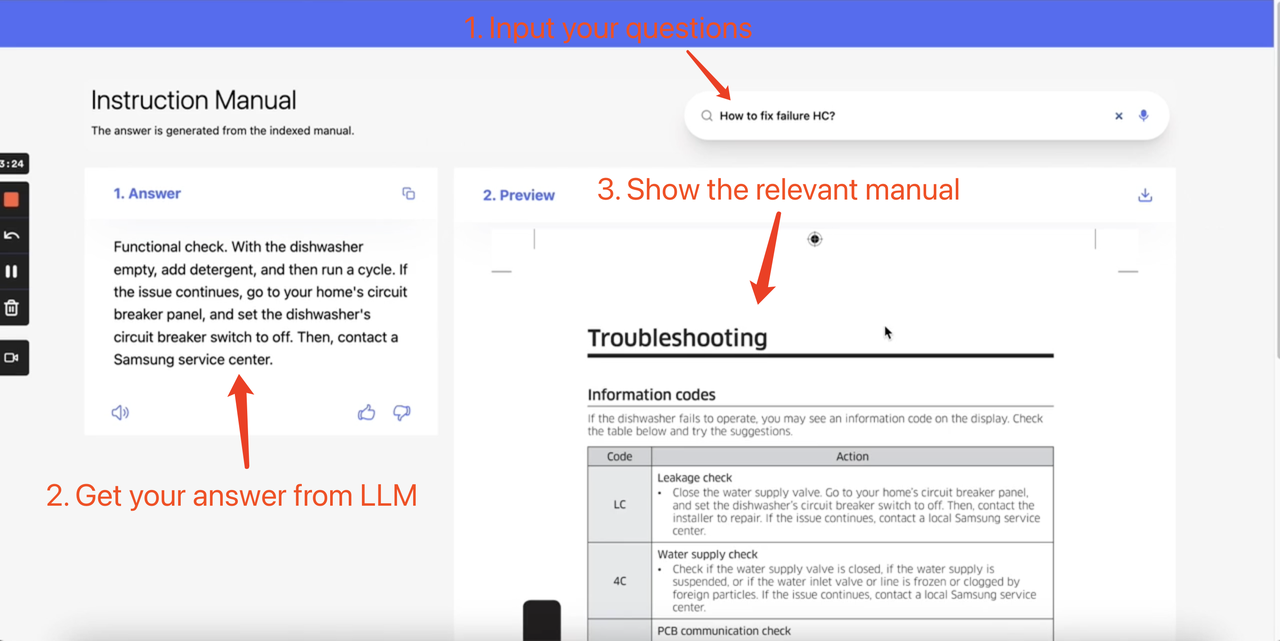
The general technical implementation is as follows:
Usually we also need the user authentication and management systems. In addition, we also need to add the analysis system of business data to the background, to see how many online users use the product, how often to use it and so on. And these functions require us to use the traditional database to achieve it.
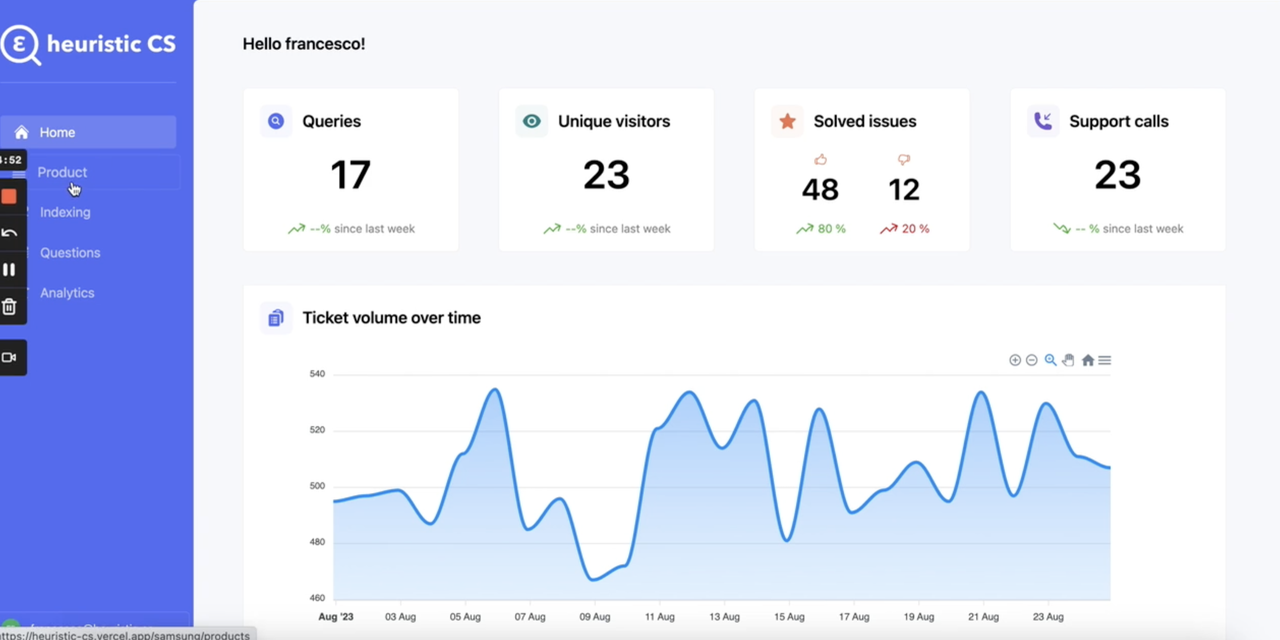
Of course, as a hackathon project, it is highly accomplished. However, if it aims to be turned into a product, the following aspects should be taken into consideration: the exponential growth of user data, system scalability and stability, data backup and recovery in multiple data centers to prevent data corruction disasters. These are not cool aspects, and sometimes even painful, but they are still areas that we need to take seriously and carefully. Fortunately, another observable trend from the hackathon is Serverless, which helps developers continuously reduce the technical difficulties of productizing an application.
The efficiency improvement brought by the serverless transformation of foundational software.
It has been observed that independent developers are playing an increasingly prominent role in project development. In contrast to the large team collaborations in hackathons of the past few years, nowadays outstanding projects are often completed by 1–2 developers, or even by individuals on their own. Behind this trend, the wave of serverless transformation plays an important role. With serverless, developers can focus on business logic without getting entangled in the details of underlying infrastructure. I haven’t seen developers using local deployments anymore, instead they deploy front-end and business code using Vercel. For backend components, they use Vector databases like Qrdrant or Pinecone and use relational databases like TiDB Cloud Serverless. With these tools, basically one engineer can complete a demo-level application.
In this era, it’s not just the AI field that shines. Other traditional technologies are also providing developers with increasingly convenient user experiences and are continuously evolving with the waves.
The developer experience is always the key.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts too: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts too: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!