Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: count 结果不一致
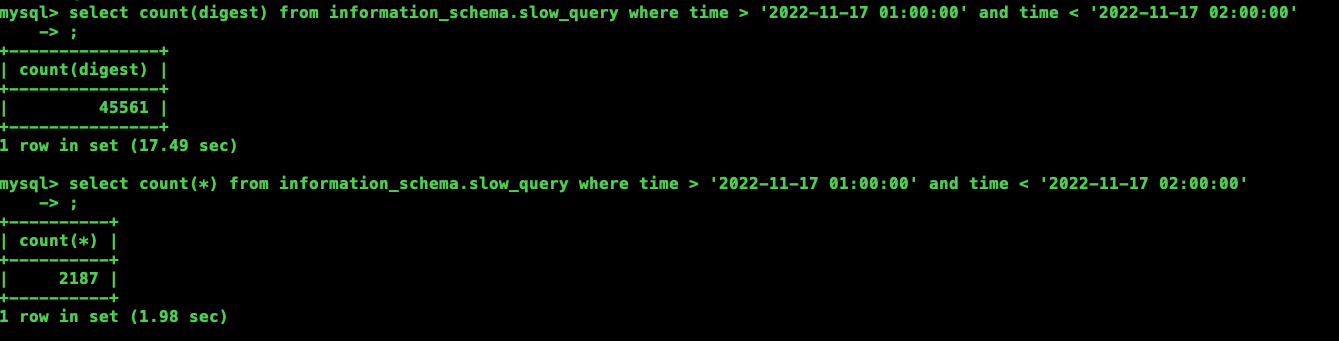
Today, while investigating an issue where a compute node’s CPU was fully utilized, I logged into the node to check the slow logs and found a strange problem: the results of count(*) and count(digest) were inconsistent. Has anyone encountered this before?
TiDB version v5.4.2
Take a look at the execution plans of the two using EXPLAIN ANALYZE.
I have the same issue here. The execution plan is the same, so it should be a syntax problem. According to Baidu, there is a difference between count(*) and count(col) in terms of data retrieval.
count(1) and count(*) are the same.
count(*) is not querying the total number of rows in the table. It should be more than the count(digest), right? Why is it showing less? Have I always misunderstood?
I also found inconsistencies on my end, but count(*) is greater than count(digest).
Is this column a non-null column?
Checked, there are no null or empty values.
Then that’s not the issue. count(*) will include null values, while count(col) does not count nulls, resulting in fewer data 
Now it always feels unreliable to perform aggregation operations like group by, count, and sum on the slow_query table.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.