Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: inconsistent index tbl handle count 144 isn’t equal to value count 140
[TiDB Usage Environment] Production Environment
[TiDB Version] v3.0.3
[Encountered Issues: Symptoms and Impact]
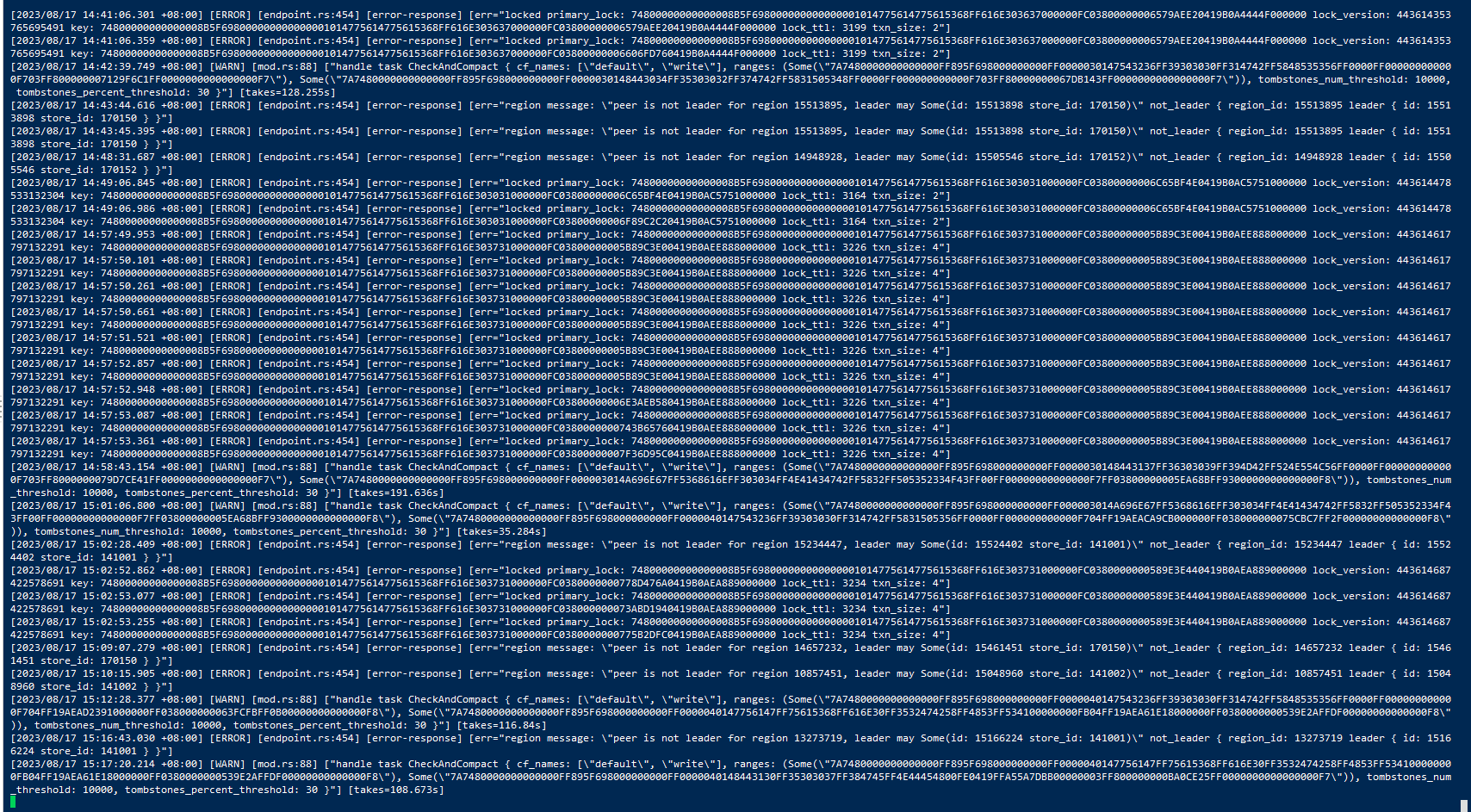
- Yesterday, the TiKV server unexpectedly crashed. After restarting the server and bringing up the TiDB service, it indicated that two TiKVs were in a down state and could not be brought up. Checking the error log showed [Err] 9005 - Region is unavailable. Using the unsafe-recover command on all TiKVs, they all started up normally. A simple check of large tables showed they could be opened normally, so no further inspection was done.
- This morning, the log showed an error during insertion. Using admin check table xx, the same [Err] 9005 - Region is unavailable error appeared. Checking the TiDB log, the error indicated an index inconsistency.
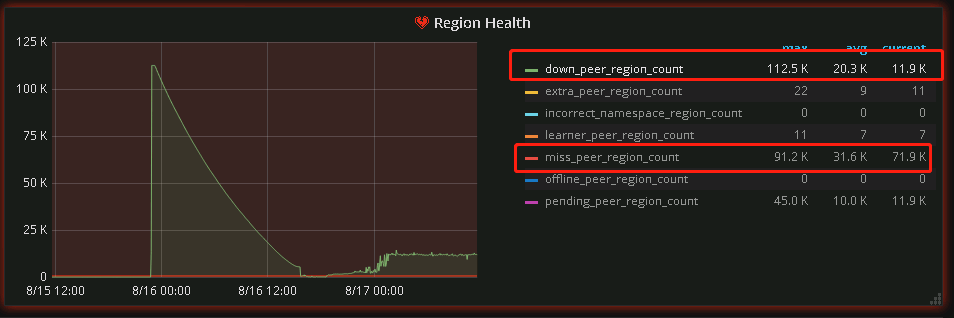
- Checking the TiDB monitoring, there are still many down-regions, and the number is not decreasing significantly. What should be done now?
tikv-ctl has a function to check bad SST files. Try testing it.
Use pd-ctl region check down-peer to see which regions are down.
Check if the region replicas are all on those two nodes. If both of those KV nodes have issues, it is recommended to scale down those problematic nodes.
Your problem is that all the data is already corrupted, the index is corrupted, and the table is corrupted. Export whatever you can and back up whatever you can. Then rebuild.
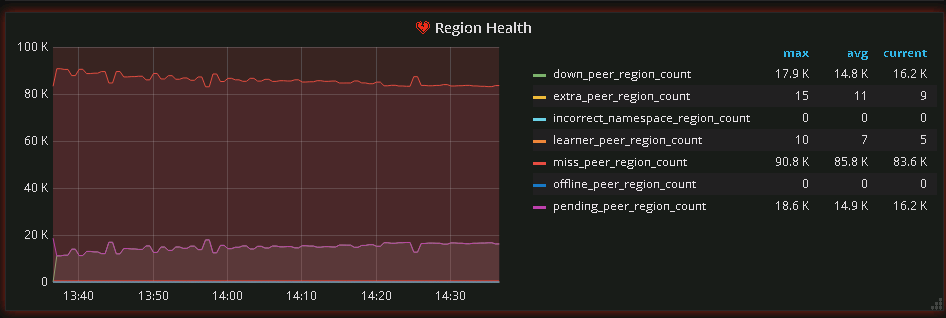
I noticed that there is a down-peer on each store.
This down-peer doesn’t seem to be automatically resolving itself.
Previously, I had a small number of SST files damaged, and I manually repaired them. However, your scale is too large, and the disk must have issues. If you can, back up the data first and prepare to rebuild.
The issue won’t be resolved. The region you lost here has 90k data, all of which is corrupted.
I replied incorrectly earlier. Previously, I used tikv-ctl to check the bad-region, not the bad-ssts. I just checked and found that this toolkit command does not support checking bad-ssts.
I searched the TiDB logs and did not find any “region is unavailable” errors; the errors reported are all about index inconsistencies.
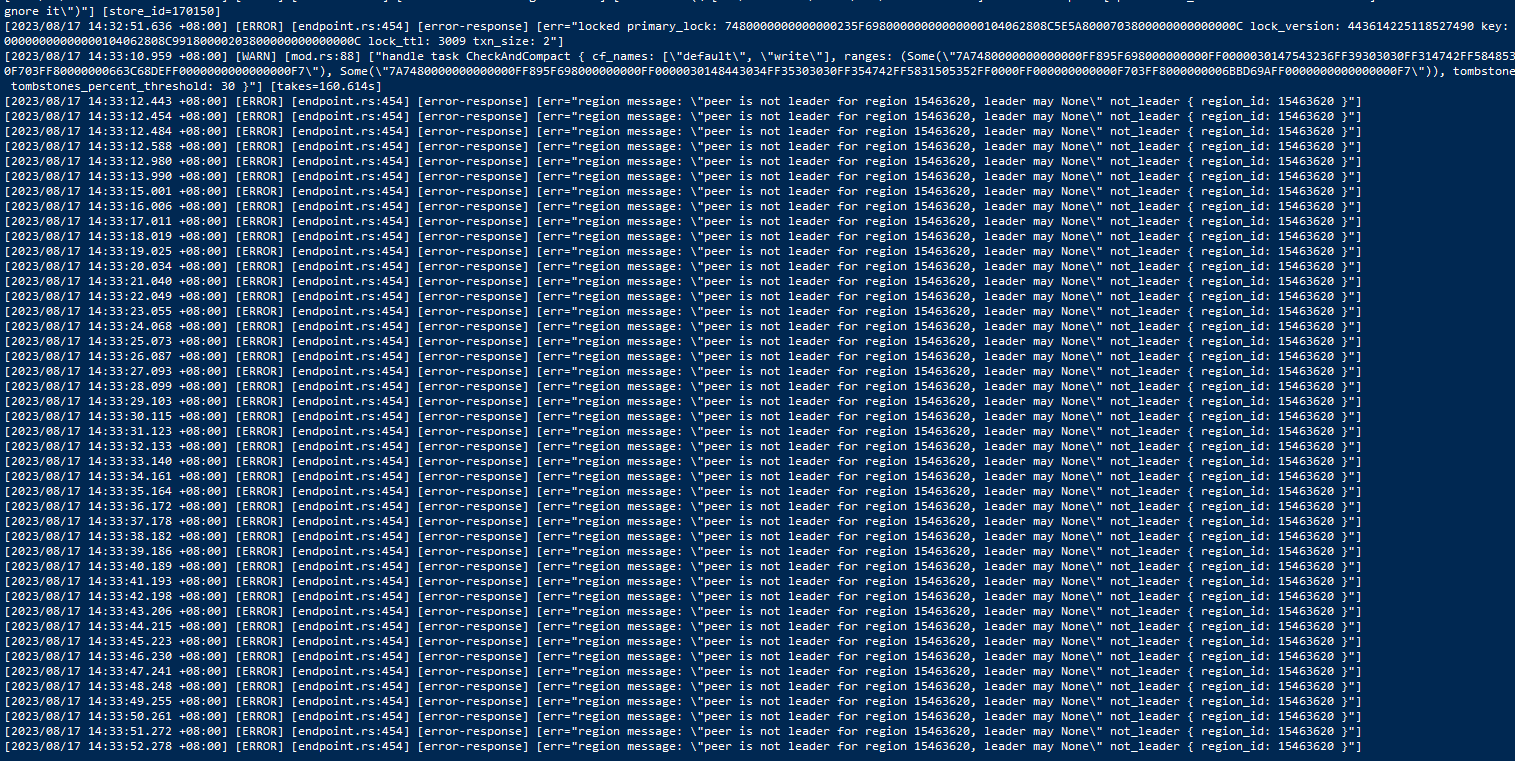
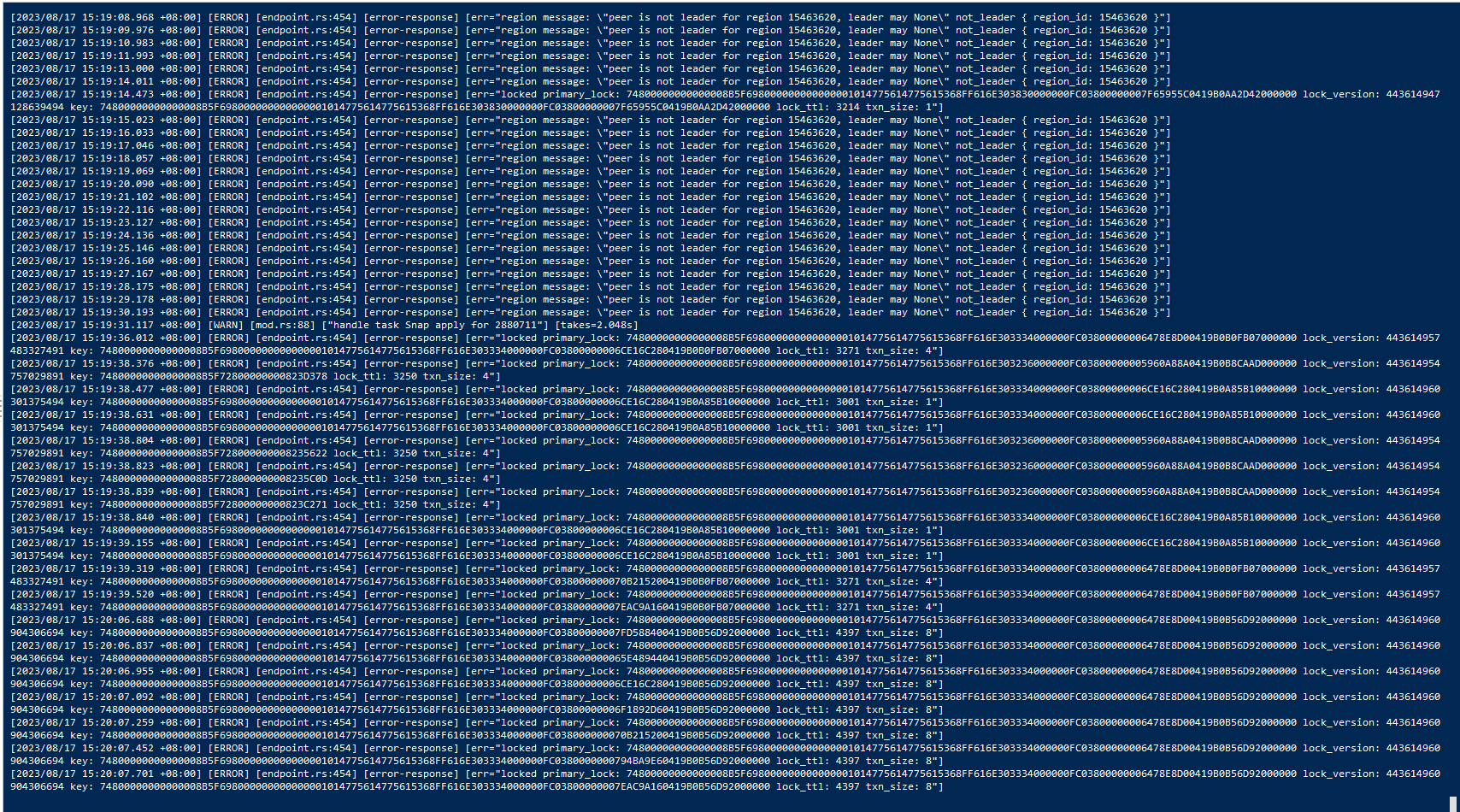
The TiKV logs report that region 15463620 has no leader issue, but I checked and found that there is no problem with this region.
miss-peer_region_count I see it is decreasing, but the speed is very slow.
Find the corresponding table and repair the index;
ADMIN CLEANUP INDEX tbl idx; — Index is more than the table
ADMIN RECOVER INDEX tbl idx; — Index is less than the table
Index inconsistency error, 数据索引一致性错误 | PingCAP 归档文档站
The third step checks the consistency of data indexes. RawKV is not required.
When executing ADMIN CHECK INDEX, it reported [Err] 9005 - Region is unavailable.
Here are the current TiKV logs,
After switching to a higher version of the toolkit, the bad-sst error is different from the one you reported.
check bad-sst reports the following error
corruption info:
/TiDBDisk1/deploy/data/db/5623506.sst: IO error: No such file or directory While opening a file for random read: /TiDBDisk1/deploy/data/db/5623506.sst: No such file or directory
sst meta:
sst 5623506 is not found in manifest: Error in processing file /TiDBDisk1/deploy/data/db/MANIFEST-5610025 NotFound: sst 5623506 is not in the live files set of the manifest
Check pd-ctl region 15463620, the bad-sst check error is likely because those SST files are already gone.