[TiDB Usage Environment] Production Environment / Testing / Poc Production Environment
[TiDB Version] v5.4.0
[Reproduction Path] Operations performed that led to the issue
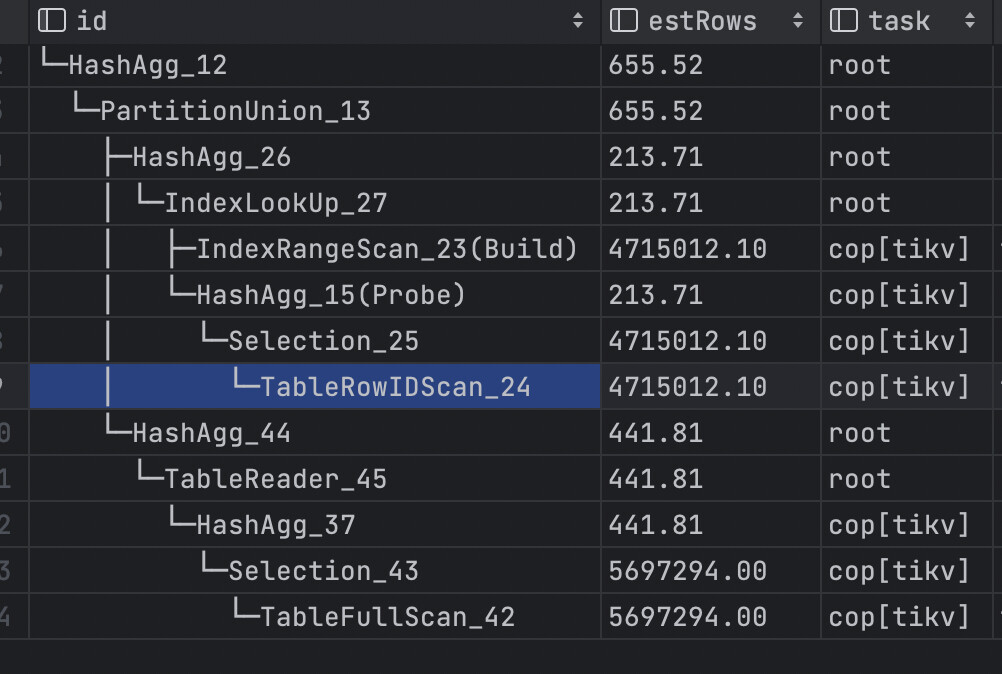
[Encountered Issue: Problem Phenomenon and Impact] Using an index actually made the performance worse
[Resource Configuration] 50 cores, 384GB
[Attachments: Screenshots/Logs/Monitoring]
TableFullScan is much more efficient than IndexRangeScan, not sure if large data volumes cannot use indexes
Execution Plan:
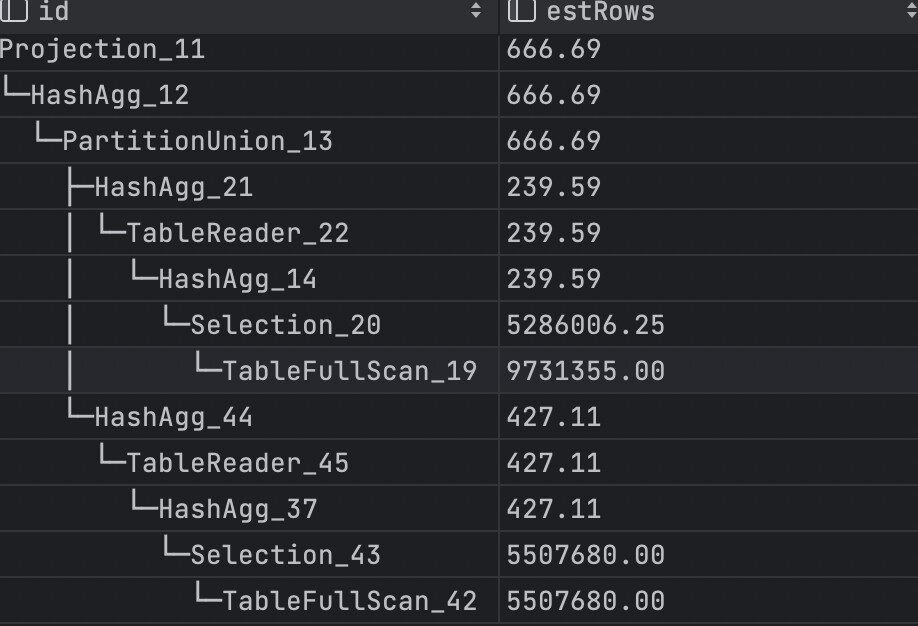
Yes, the optimizer uses the index based on the data volume, but if my time range becomes larger, it will perform a TableFullScan, which is the second picture, and the performance is better.
Indexes are used to avoid full table scans, but accessing the index and then the table incurs additional overhead. If the amount of data accessed is too large a proportion of the table, a full table scan is faster. Generally, queries that use indexes should access less than 10% of the table.
It is not that large amounts of data are not suitable for indexing! Indexing is meant to quickly find data that meets the conditions from a large table. However, if the query conditions do not filter much data, then using an index may not necessarily be faster. If each query needs to return a large amount of data from this table, then the index is not very meaningful.
Yes, my business only involves partial columns. When accessing, there may be a large number of queries or a small number of queries. It feels like the optimizer should handle this. For example, if less than 10% of the columns are queried, use IndexRangeScan; otherwise, use TableFullScan.
This seems to be the optimizer’s job. For queries, you can only choose not to add indexes, because there are both large and small scan requirements. As a compromise, it’s better not to add indexes.
I don’t understand your actual scenario. Why compromise by not adding an index? Generally, you add an index, and for special SQL, you add a hint to fix the execution plan.
Well, after adding the index, the optimizer used IndexRangeScan, but the efficiency slowed down. So, the compromise is not to add it. The purpose of my post is to discuss under what circumstances to add an index. Currently, it seems that the optimizer needs optimization. Since we have fixed SQL for our business, hints can only optimize specific scenarios of SQL and cannot be generalized.
sql:
SELECT
info_id, COUNT(*) AS log_call_event_count, MAX(log_test.error_message) as error_message FROM
sy_db.log_test
where log_ds >= ‘2023-07-03’ AND log_ds <= ‘2023-07-04’ AND log_ts >= ‘2023-07-03 15:00:00’ and log_ts <= ‘2023-07-04 15:00:00’
group by info_id
tidb_index_lookup_size: Controls the chunk size during the index lookup process, default is 20000. If the number of rows matched by the query is large, you can appropriately increase the value of this parameter to reduce the number of chunks.
tidb_index_scan_batch_size: Controls the batch size during the index scan process, default is 256. If the batch size is too small, it will lead to frequent network transmissions, thereby affecting query performance.
tidb_max_chunk_size: Controls the maximum chunk size of the returned result set, default is 32MB. If the result set returned by the query is large, you can appropriately increase the value of this parameter to reduce the number of chunks.
SQL:
SELECT
info_id, COUNT(*) AS log_call_event_count, MAX(log_test.error_message) as error_message FROM
sy_db.log_test
where log_ds >= ‘2023-07-03’ AND log_ds <= ‘2023-07-04’ AND log_ts >= ‘2023-07-03 15:00:00’ and log_ts <= ‘2023-07-04 15:00:00’
group by info_id