This article briefly introduces the new architecture of TiCDC, the problems it addresses, and a comparison with the previous architecture, helping readers quickly grasp the key concepts of the new design. If you are considering testing the new architectural TiCDC, this article also offers some practical testing suggestions.
Project plan
The development of the new architectural TiCDC will start around June 2024. Currently (January 2025), the first version that can be tested by users has been released. It is expected to be released in the near future, to become the default architecture of TiCDC.
You can now follow this document to try out the new architecture TiCDC on older versions of TiDB.
Positioning
- As the next generation of CDC, users of the old version can upgrade directly and smoothly. There is no difference in deployment or user experience compared to the old version of TiCDC, except for:
- Grafana monitoring has been completely refactored, making it simpler and easier to use than before.
- The new TiCDC is compatible with > = V7.5 version of TiDB experimentally.
-
Users can easily test the new TiCDC.
-
It planned that after sufficient testing and user verification, the experimental compatibility will be turned into official compatibility. Due to unknown risks, the officially supported version cannot be estimated at this time, but will be pushed forward as a high priority after the Experimental release
- To ensure the project makes progress smoothly, the new architecture TiCDC will not accept any new features until it is officially GA, except support dynamic splitting and merging of single table synchronization tasks, whose purpose is to support larger single table traffic, maintain system stability, and avoid hotspots
Performance reference
The following provides the new architecture TiCDC performance reference. It shows that the performance increases nearly linearly as more nodes are added to the cluster.
Note:
-
The synchronization traffic performance of TiCDC is closely related to the specific business situation, including the number of tables, row width, etc., so an accurate reference value cannot be provided. Below are some typical scenarios for reference.
-
The performance here refers to the synchronization performance of TiCDC itself, excluding downstream write speed. If there is a performance bottleneck in the downstream system, the synchronization performance may be limited, thus failing to achieve the performance level here.
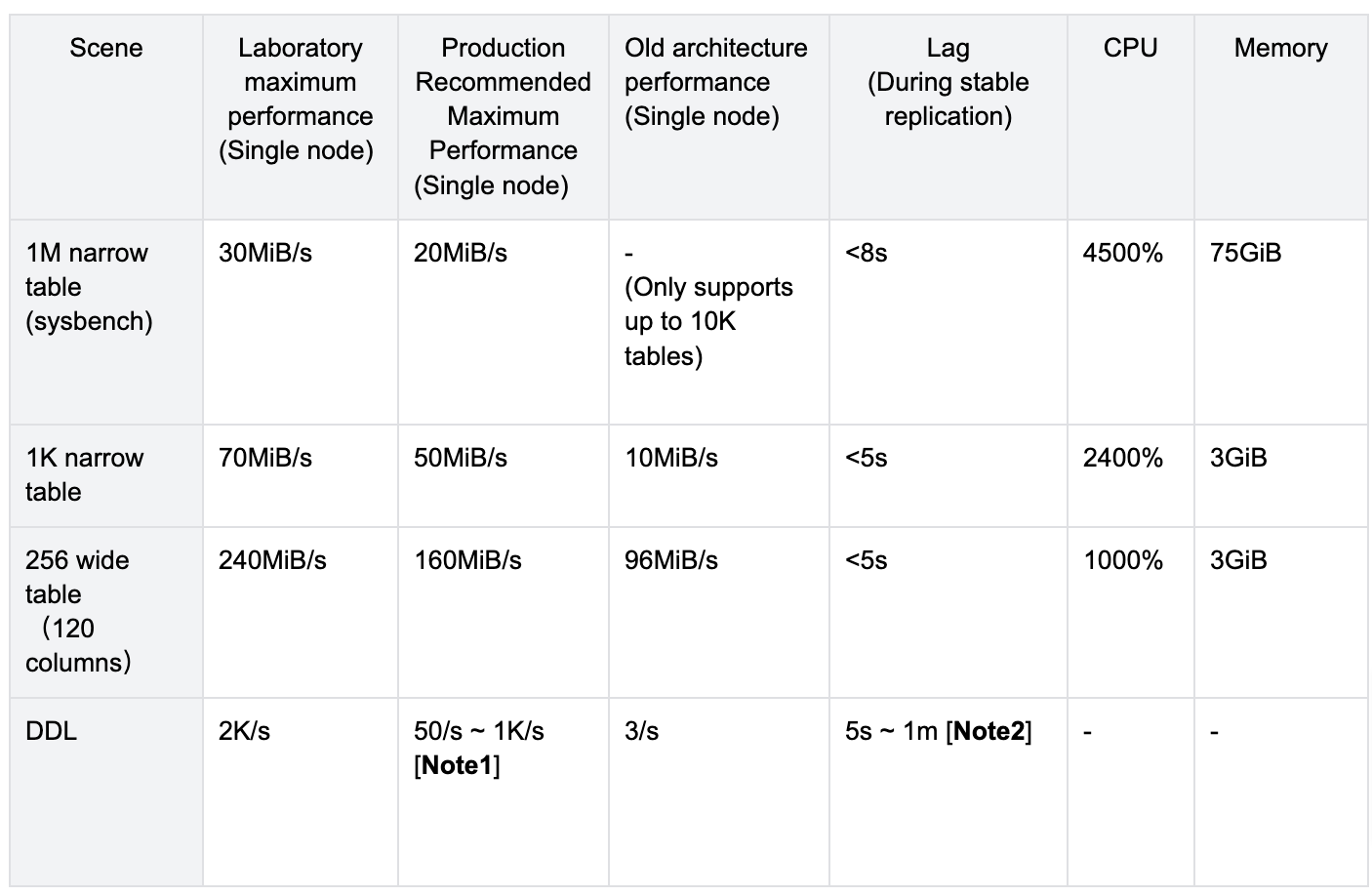
Note 1: Simple DDLs such as alter column have higher synchronization performance, while operations such as truncate table involving rebuilding internal physical tables have poor performance, which is why 50/s is recommended here
Note 2: Some DDLs such as truncate table can cause a significant increase in Lag. We will optimize this phenomenon in the future
Original intention
The new architecture CDC was initially designed to solve several problems encountered by typical users as their scale grew
- The current version of TiCDC cluster can only support synchronization of about 100K tables and 400 changefeeds. However, some users hope to support synchronization of more than 1 million tables and more changefeeds.
- Unable to stably scale out to more than 10 CDC nodes
- Unable to support super large traffic, such as synchronizing several GB of traffic in a cluster
- Unable to execute DDL with higher frequency stably. Actually, the current CDC can only support about 3 DDL per second per changefeed
- During cluster scale-out, scale-in, or other changefeed operations, the normally running changefeeds will be affected, resulting in an increase in lag
After conducted in-depth research, we found that the fundamental limitations behind these issues come from the current CDC architecture design, including some basic abstractions and processing logic. Simple optimization iterations may have some effect but cannot completely solve the problem, so we launched a new architecture project.
Advantage
The new architecture TiCDC has significant improvements in performance, stability, scalability, and other aspects. The following are what have been discovered so far:
- Single-node performance improved significantly
-
A TiCDC node can support up to 500K tables
-
A TiCDC node can support up to 200MiB/s traffic (wide table scenario)
- Highly horizontally scalable
-
It is expected to be able to scale-out to more than 100 nodes
- Supports millions of tables per cluster
- Supports GiBs per cluster
-
Be able to support more than 10K changefeeds
-
One changefeed can manage millions of tables
- Much better stability
- Under high write in traffic scenarios, keep the replication latency low and more stable.
- Under TiCDC cluster scale-out, scale-in scenario, and operations such as creating and deleting changefeeds, less impact on other irrelevant changefeeds.
- The same synchronization ability, less resources, and less cost.
- Under typical scenarios, the CPU and memory efficiency improved by up to one order of magnitude.
The new architecture also reduces the code complexity, which is helpful to accelerate the evolution of the project. Since the design of the new architecture fully considers the future requirements, such as Cloud-Native based architecture, and TiCDC independent deployment.
Comparison between the old and the new architectures
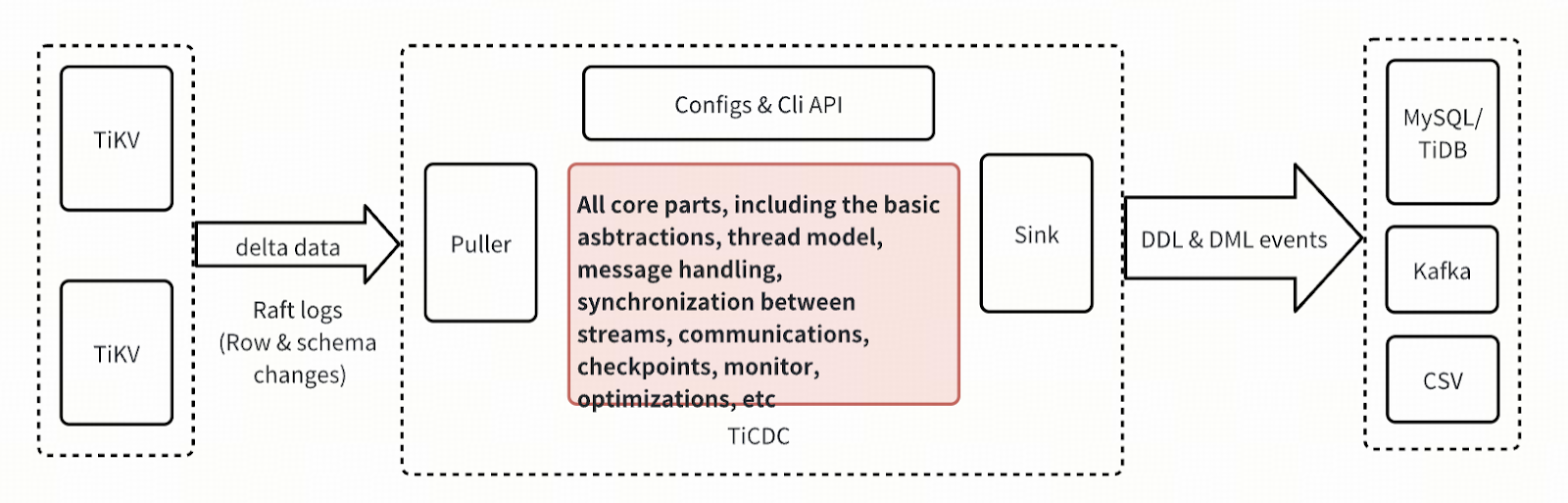
First, let’s take a look at which modules have been redesigned. As shown in the figure below, we have kept three modules basically unchanged: Puller (pulling changes from TiKV), Configs & Cli API (configuration and user operation API), and Sink (module for writing data to downstream systems, such as Kafka, MySQL, etc.). This ensures good compatibility between the new TiCDC and upstream and downstream, and users can upgrade the TiCDC cluster smoothly.
All other components has been redesigned, including the basic abstraction model, thread model, monitoring, etc. We have also migrated the code base from pingcap/tiflow to pingcap/ticdc , the TiFlow repository is shared by the TiCDC and the DM, it has been proved that there is very little connection between them, and they affect each other due to share the same golang module dependencies. It is a good opportunity to let the TiCDC have an independent code repository for easy management.
Basic abstraction and architecture
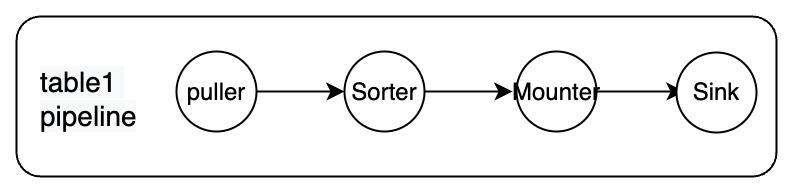
The internal abstraction of the current architecture TiCDC is closely related to changefeed. A business-level changefeed also corresponds to the internal changefeed data structure and corresponding resources, including threads and memory resources. It contains all necessary modules, including Puller for pulling data from TiKV, Sorter for sorting by disk, Sink for writing games, and so on. The advantage of this design is that the concept is easy to understand and the changefeeds are relatively independent. The problem is that it is difficult to split the tasks of changefeed, and stateful and stateless modules are mixed together, which is not conducive to balanced scheduling between nodes.
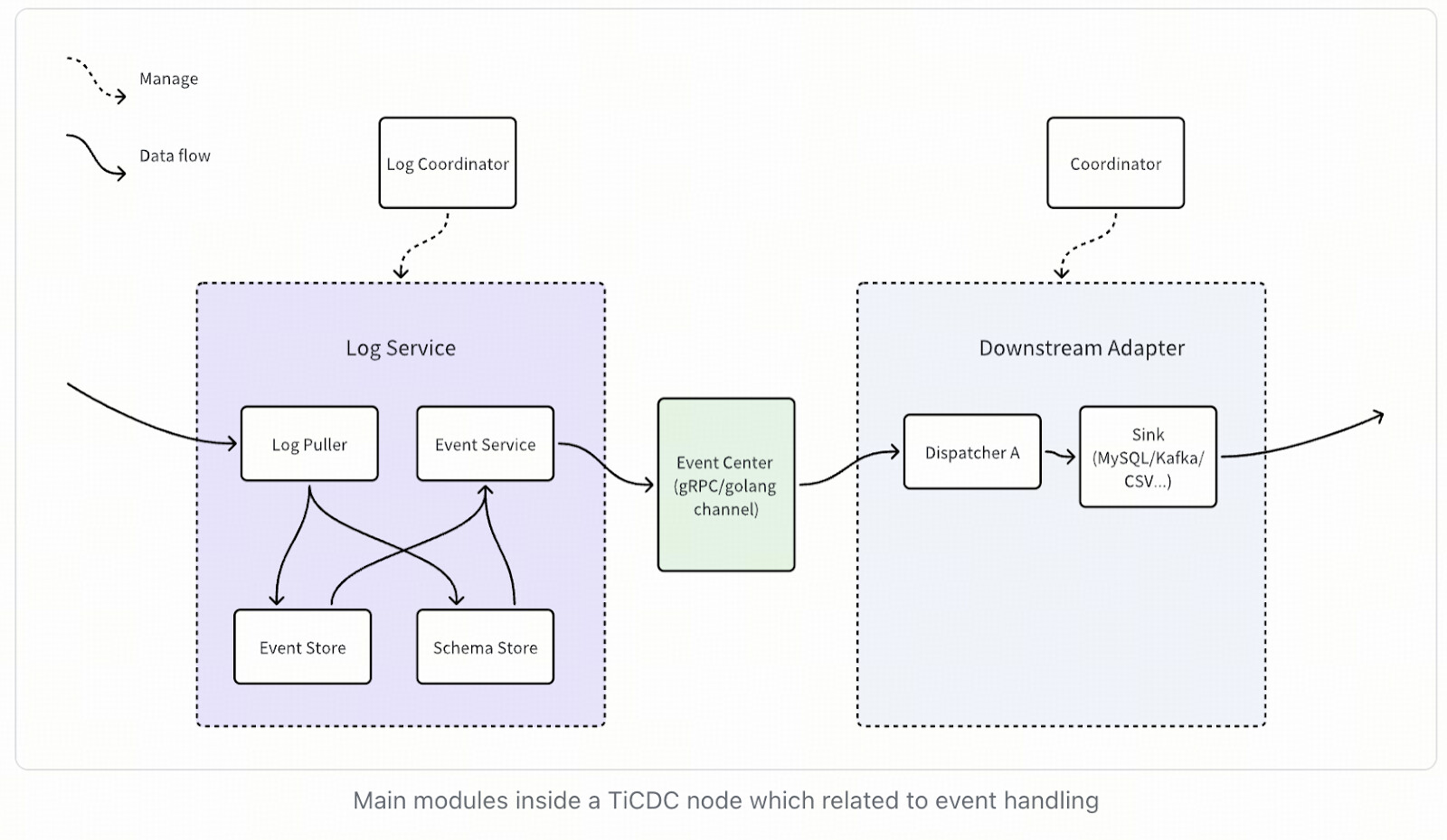
In the new architecture, changefeed does not directly correspond to data structures and resources, but is used as a parameter to control the activities of internal services. After changefeed is created, it triggers the creation of one or more dispatchers (including Sink function), each of which handles a range of data changes in a table. These dispatchers are responsible for requesting data from the upstream Log Service and then writing it downstream. Dispatchers are stateless and can be quickly created and deleted.
Other modules have been abstracted into independent services, including the Log Puller service specifically responsible for pulling data from TiKV, the Event Service service (formerly Sorter) that handles data caching and sorting, and these services are stateful.
The significant change is that the new architecture divides stateful and stateless services, and can only communicate through the Event Center. We use this method to help developers carefully design API interfaces and avoid unconscious coupling behavior in subsequent code iterations. Another significant benefit is that in subsequent TiCDC iterations, it is possible to support the execution of Log Service and Downstream Adapter modules in different processes, allowing TiCDC to separately expand necessary modules according to different loads. It is also used to implement other functions, including independent deployment of TiCDC services.
Core processing logic
The old architecture TiCDC uses the Timer Driven pattern to process messages within the system, while the new architecture uses the Event Driven pattern.
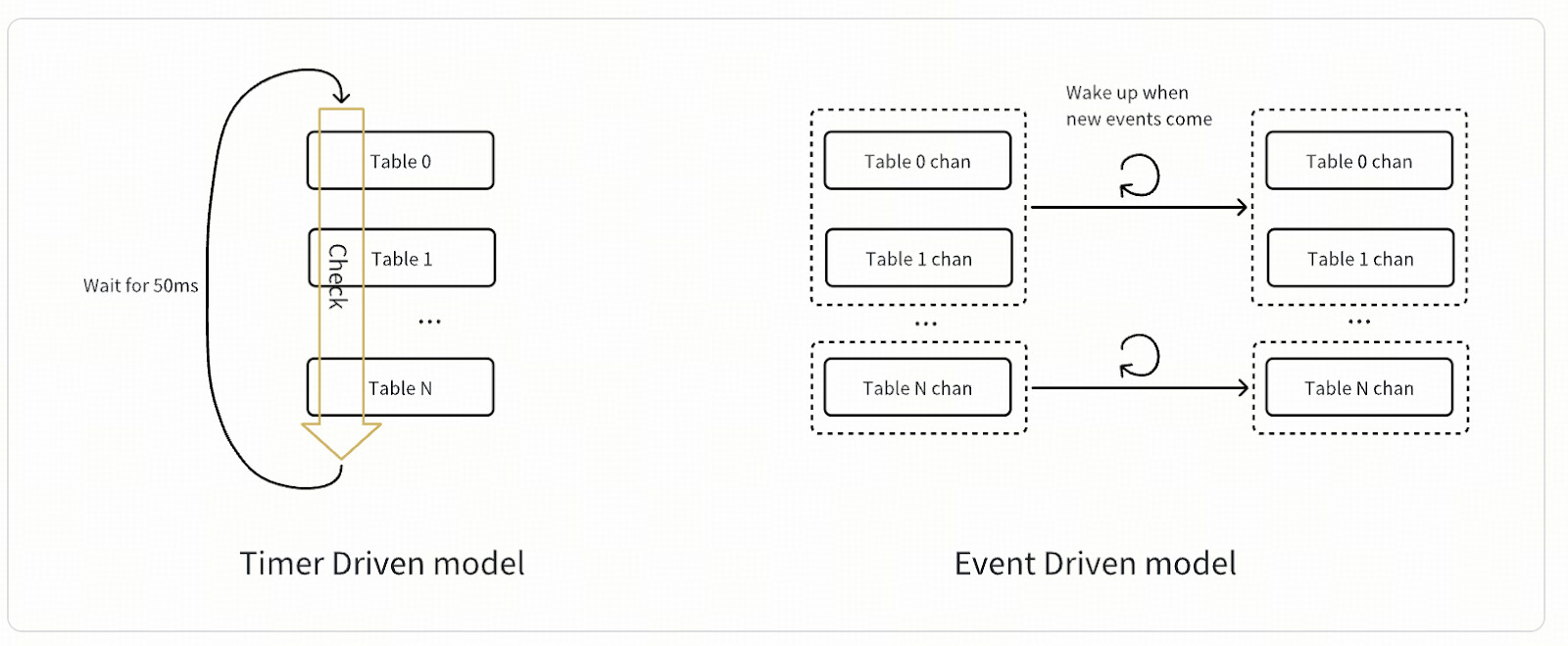
Timer Driven
The basic logic of the Timer Driven pattern is to use a large loop triggered by a timer to continuously push the execution of the next batch of tasks. For example, there will be a large loop inside each changefeed, checking all tables every 50ms to see if there are any tasks waiting to be processed. If there are, they will be placed in the processing queue for other threads to process.
The advantage of this processing model is that it is easy to understand. The biggest drawback of this model is limited processing performance, inability to scale, and waste of resources. Here are some examples
- 50MS is the result of balancing performance and resource waste. Currently, TiCDC takes 3 steps to process a DDL operation, and because there is a central control node (Owner) that needs to communicate with the worker node (Worker), it actually takes 6 cycles to process it. 1s /(3 * 2 * 50ms) = 3.33 DDLs per second.
- The complexity of this processing model is O (n), where n is generally equal to the number of tables. When the number of tables is large, the processing performance will significantly decrease. Moreover, each check wastes a lot of CPU on checking inactive tables because there is no new data to process for a large number of tables
- A changefeed can only use one logical CPU to process loops, which means it cannot be scaled-out.
Event Driven
The event driven pattern takes actions by the events such as DML, DDL changes, changefeed creations, modifications, etc. Events are placed in a queue and then consumed and processed concurrently by multiple threads. This pattern has the following benefits:
- The event will be processed as soon as possible, no need to wait for 50ms.
- Increasing the number of consumption threads can improve processing ability.
- The complexity of each processing step is O(1), which is more efficient and not affected by the number of tables. This is the key to the new architecture being able to handle massive tables
Code complexity
Even though the event change between multiple tables is irrelevant, and can be executed parallely in most scenarios, but there is also some cases that event changes between tables have dependencies, such as cross-table DDL, Syncpoint, etc. Therefore, complex judgments are needed to determine whether a change (such as DML, DDL) can be executed. The processing method of the old architecture, due to the lack of good abstraction, leads to a dramatic increase in code complexity. For example, as shown in the figure below, each processing module needs to consider the logic of other modules and make various judgments, and its complexity is N x N. This problem is the main source of the complexity of the old CDC code.
In the new architecture, we abstract these dependencies and handle them separately in the Maintainer module. Logically, after each Event arrives, we only need to ask the Maintianer to know if it can be processed immediately, or when it can be processed, the Maintainer will actively send a new Event to the corresponding module. The complexity of this architecture is N x 1, greatly improving maintainability.
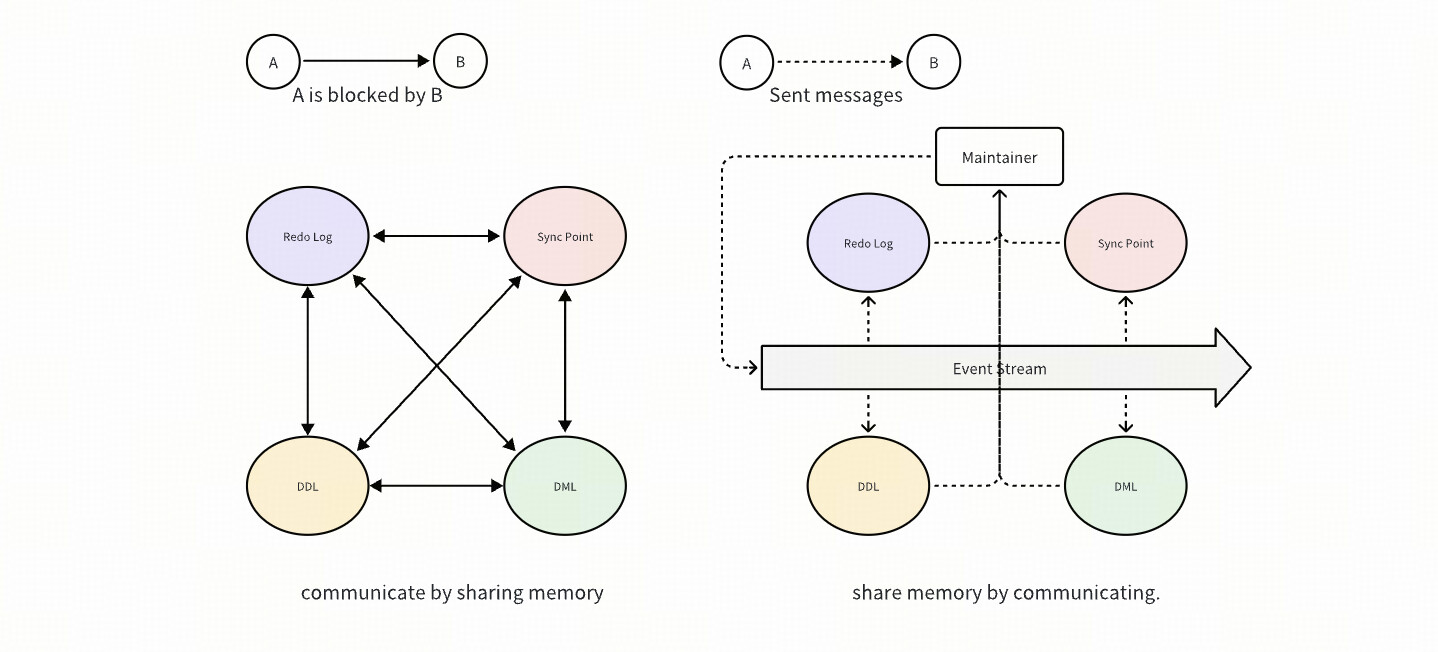
Further improvements chances
The new architecture TiCDC opens possibilities for future improvements. Including storing the logs by separate processes, to avoid stopping GC of MVCC versions.
Test direction
You can now follow this document to try out the new architectural TiCDC on older versions of TiDB. If you want to test the new architecture TiCDC, you can consider starting from these perspectives:
- Simulate your normal business operations. If you encounter any bugs, please give feedback to here ticdc/issues . We will fix it as soon as possible
- Observe if the delay lag is more stable than before, especially during peak business periods
- Observe whether resource utilization (CPU, memory) has significantly decreased
- Test the expansion and contraction of the TiCDC cluster, or perform operations such as creating, deleting, pausing, and resuming on changefeed, observe the impact of changefeed’s lag, whether the traffic is stable during the process, and whether there is any imbalance
- If you previously needed to split the changefeed or even cluster to complete it due to too many tables, too frequent DDL, or too much traffic, you can try to use only one cluster or a few changefeeds in the new architecture CDC to see if they can be synchronized normally
- For your business, see where the CDC can improve