Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 续扩容引起pending compaction bytes累计增加排查根因
[TiDB Usage Environment]
- Production
[TiDB Version]
- v4.0.12
[Encountered Issues]
- Original post: TiKV 扩容过程中,Pending compaction bytes 一直在增加 - TiDB 的问答社区
- Issue encountered: During scaling, pending compaction bytes keep accumulating
[Problem Phenomenon and Impact]
-
Adjusted
rocksdb.max-background-jobsfrom 8 to 12 and restarted the cluster for recovery. -
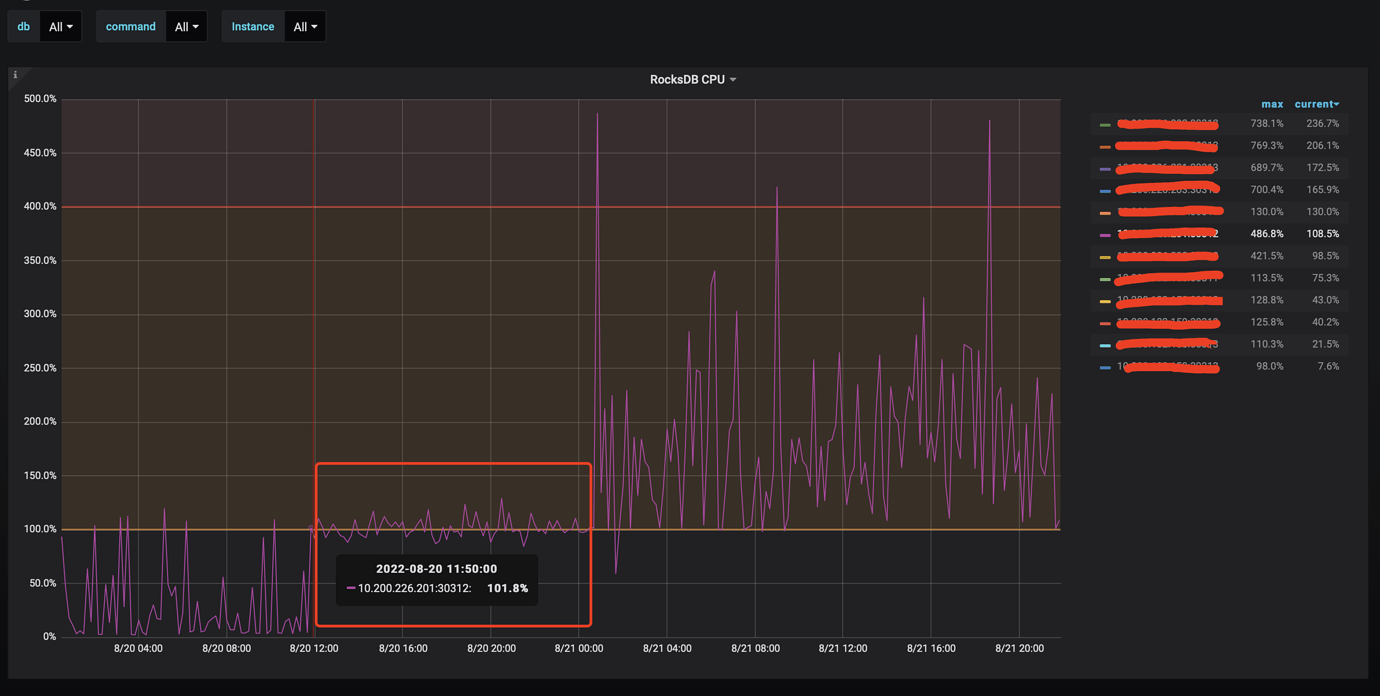
Matching metrics,
rocksdb cpuremained at 100% during scaling
-
View
rocksdb cpumetric description as follows:
-
Raised a few questions:
(1). Is rocksdb single-threaded, and which parameters are related to resource limitations?
(2). After adjustingrocksdb.max-background-jobsfrom 8 to 12, why did the CPU increase so much?
(3). This metric was not found in the official template for corresponding alerts, is it necessary?
raft store cpu
rocksdb cpu