[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version] 6.5.3 Can it be downgraded? Too many issues.
[Reproduction Path] What operations were performed that caused the issue
[Encountered Issues: Issue Symptoms and Impact]
[Resource Configuration]
[Attachments: Screenshots / Logs / Monitoring]
After the cluster upgrade was successful, two nodes kept losing leaders, causing the cluster to remain unstable, and the QPS dropped to less than 1/5 of the original. A large number of execution statements timed out, and it was not an issue with a single statement. Initially, TiFlash reported an error and was unusable. With the support of forum members, the TiFlash node was reinstalled, and normal TiFlash access was restored. Now the cluster is extremely unstable, and any SQL statement may get stuck.
Production. I thought 6.5.3 was already a fixed version, but after upgrading, the problems were very serious, and people are about to be driven to collapse.
Find a new environment (using the old cluster version), move the data back, and switch it.
Organize the current issues, focusing on identifying the critical ones, and pass them up so everyone can help you review them.
Leader is gone? What does that mean?
TiFlash is much more stable in versions after 6.X compared to 5.X.
CDC is the same, it has even been restructured… much more stable than before…
If you expect a quicker resolution, you still need to properly organize the background and key issues (even though you are in a hurry, sharpening the axe won’t delay the job of chopping firewood, and the toothpaste squeezing method will undoubtedly increase the time cost).
My cluster is relatively large and cannot be managed in a short time. It is approximately 20TB in total, with 6 KV nodes and 2 TiFlash nodes.
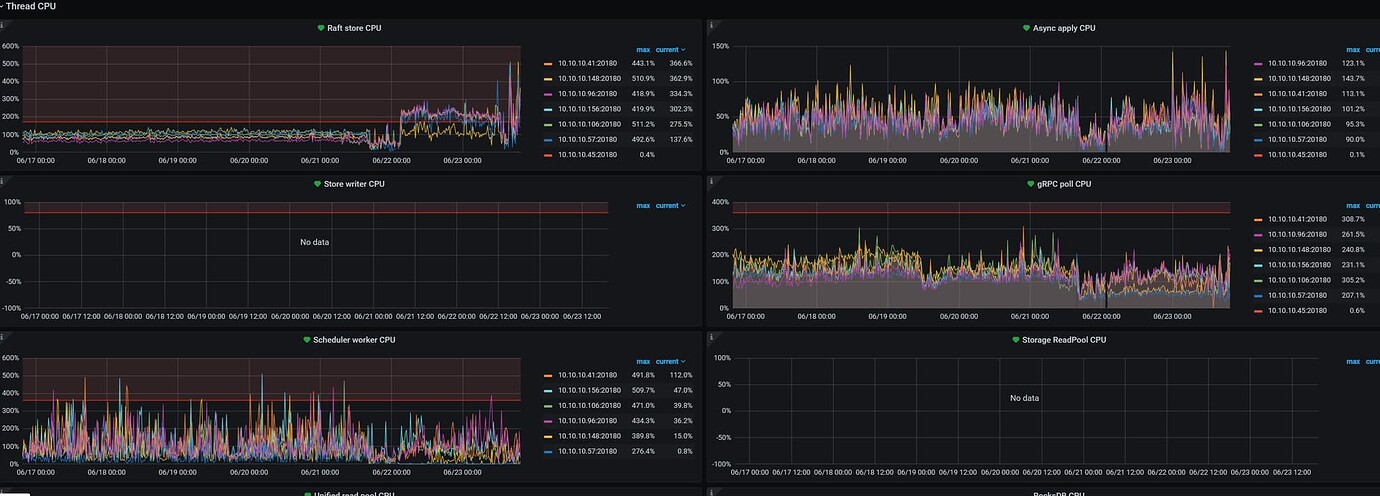
1). One of the KV nodes’ leader count suddenly drops from 120K to 0, then slowly recovers to balance, but it doesn’t stay stable for more than five minutes before dropping again. This cycle repeats continuously.
2). I upgraded from 6.1.5 to 6.5.3 to resolve some issues in 6.1 (specifically the low performance of CDC, as I saw that 6.5 improved from 4000/s to 35000/s, which convinced me to upgrade).
3). CDC is practically unusable, similar to the issues other friends on the forum have encountered. Please see others’ feedback: TICDC distributing data to one table per TOPIC often inexplicably freezes, with no new data being written - Suggestions / Product Defects - TiDB Q&A Community (asktug.com). No one seems to be able to provide a clear explanation.
For example, in such a situation, can anyone help me see what’s going on…
I’ve been struggling with this for two or three days, and the entire cluster is on the verge of collapse, basically unusable.
There is a known issue with CDC where it collects some status and data information from Kafka at startup or periodically for performance and processing statistics of CDC.
However, this issue does not mention when it will be fixed…
There is a workaround, which requires modifying the source code and then packaging a patcher to skip it.
This issue is uncertain, and it might not be the one you encountered.
If the region leader is not balanced enough, you can refer to the troubleshooting guide and check it step by step.
Basically, it is a timeout issue, causing the follower to think the original leader is dead, which will initiate an election to select a new leader.
You can refer to the following for specific operations:
I currently have 6 nodes, four of which are stable, and 2 are experiencing significant drops. I have set them to not enable Leader, so they can barely run. CDC and TiFlash cannot be turned off, especially TiFlash, as business queries use TiFlash to accelerate. If TiFlash is turned off, it will cause a large number of big queries to fall on TiKV, resulting in durations of over 5 minutes. There doesn’t seem to be any obvious hotspot issues. Are there any logs that can be investigated? For example, I see something like this:
2023-06-23 19:04:30 (UTC+08:00)
TiKV 10.10.10.156:20160
[cleanup_sst.rs:119] [“get region failed”] [err=“failed to load full sst meta from disk for [242, 148, 145, 51, 128, 141, 72, 6, 165, 188, 254, 164, 106, 120, 179, 243] and there isn’t extra information provided: Engine Engine(Status { code: IoError, sub_code: None, sev: NoError, state: "Corruption: file is too short (0 bytes) to be an sstable: /data/tidb-data/tikv-20160/import/f2949133-808d-4806-a5bc-fea46a78b3f3_4080615702_42367_145285_write.sst" })”]
The log indicates that the file /data/tidb-data/tikv-20160/import/f2949133-808d-4806-a5bc-fea46a78b3f3_4080615702_42367_145285_write.sst has a size of 0. You should check if this is the case, as it seems that some data stored in this TiKV might be lost.