Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
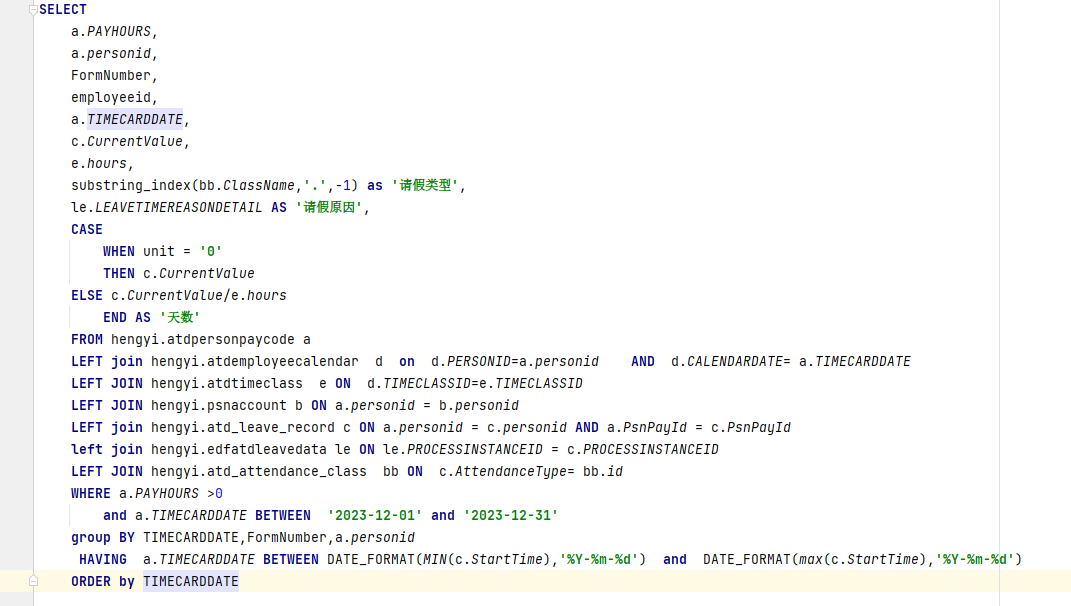
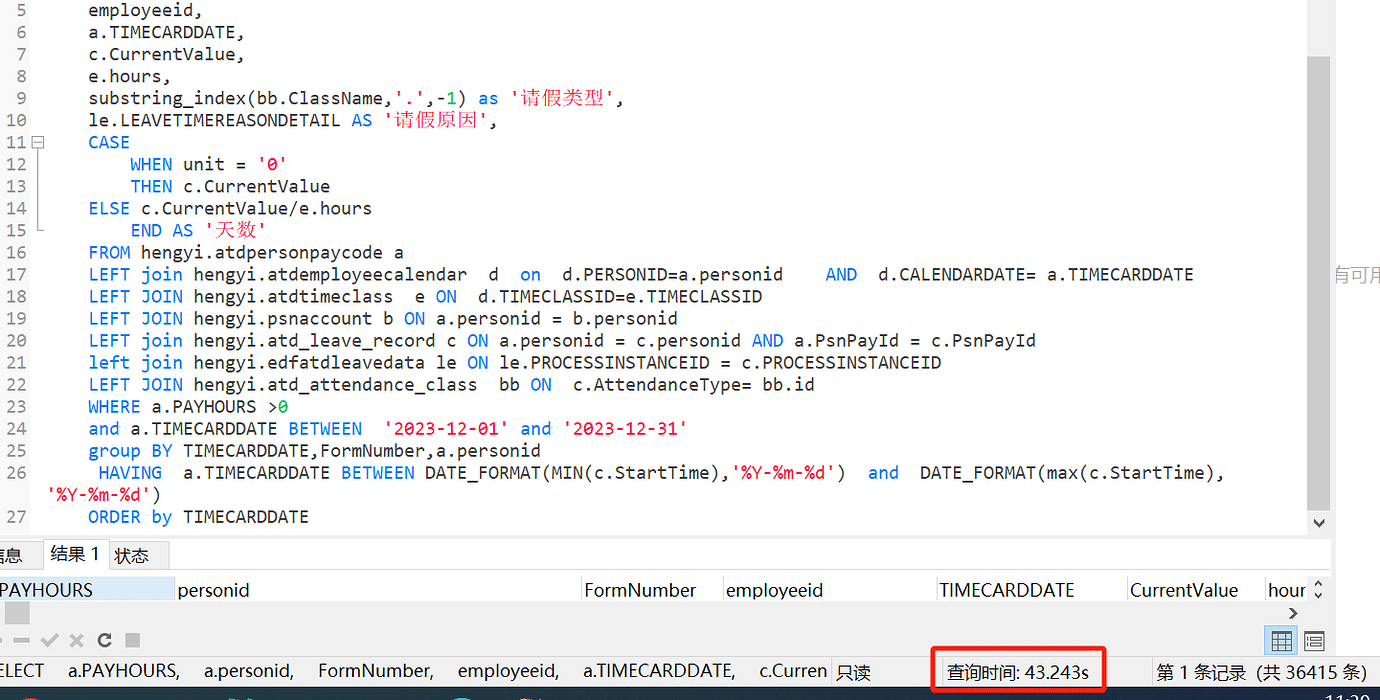
Original topic: 几百万数据group有没有优化空间,能提升到10几秒吗?group条件过滤之前大概数据300万到400万
【TiDB Usage Environment】Production Environment
【TiDB Version】
【Reproduction Path】What operations were performed when the issue occurred
【Encountered Issue: Issue Phenomenon and Impact】
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】
It is recommended to use TiFlash for such large data volume queries.
For analytical SQL, you can create TiFlash replicas to utilize TiFlash MPP. For online SQL, you can check if the filter conditions and join conditions are using indexes, and whether the join order can be adjusted, such as having a small table drive a large table. However, to determine the specific optimization, you should first examine the execution plan.
Could you share the execution plan?
Go on the machine with 2TB of memory.
You can try it, first send the execution plan text and table structure for us to take a look.
TiFlash + MPP. This is very suitable for your SQL.
This is purely a query with a large amount of data.
I just looked at TiFlash, there are some issues, let them take a look first.
You must use TiFlash + MPP to achieve speed.
If you only use TiFlash for scanning, there won’t be much improvement. It might even be better to optimize the index and use TiKV instead.
Don’t assume that just because the execution plan includes TiFlash, it will be sufficient.
Doesn’t TiDB’s parser itself determine whether the index or TiFlash is faster?
 I suggest directly providing the execution plan and SQL trace text.
I suggest directly providing the execution plan and SQL trace text.
To be honest, it’s best if we discuss specific issues. If you have an execution plan, I can help you see how to optimize it.
Otherwise, if we just expand on your current problem, it will end up with us just complaining about the optimizer together.
Are you sure that’s the result you want from posting this thread?
The first link is an introduction, and the second link is the key point. If you want TiFlash to perform hash join pushdown, you must use MPP mode. With all these associations, if there is no MPP and TiFlash replica, once the optimizer chooses to do aggregation on TiDB and scan on TiFlash, it will be inefficient and the speed will not be fast.
Won’t the execution plan be captured?
a.timecarddate can consider interval partitioning, a.payhours and associated keys can consider adding indexes, and can consider using TiFlash.
There is an issue with TiFlash, it hasn’t been fixed yet. Once it’s fixed, I’ll provide an execution plan.
 Your SQL is a bit strange,
Your SQL is a bit strange,
- I don’t see any aggregate functions, but I see a GROUP BY
- It’s recommended to change the LEFT JOIN to an INNER JOIN if possible
- Please share the execution plan and table structure. We can’t just guess~