Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tikv 节点重启后,集群响应时间飙升问题
【TiDB Usage Environment】Production environment
【TiDB Version】v6.1.4
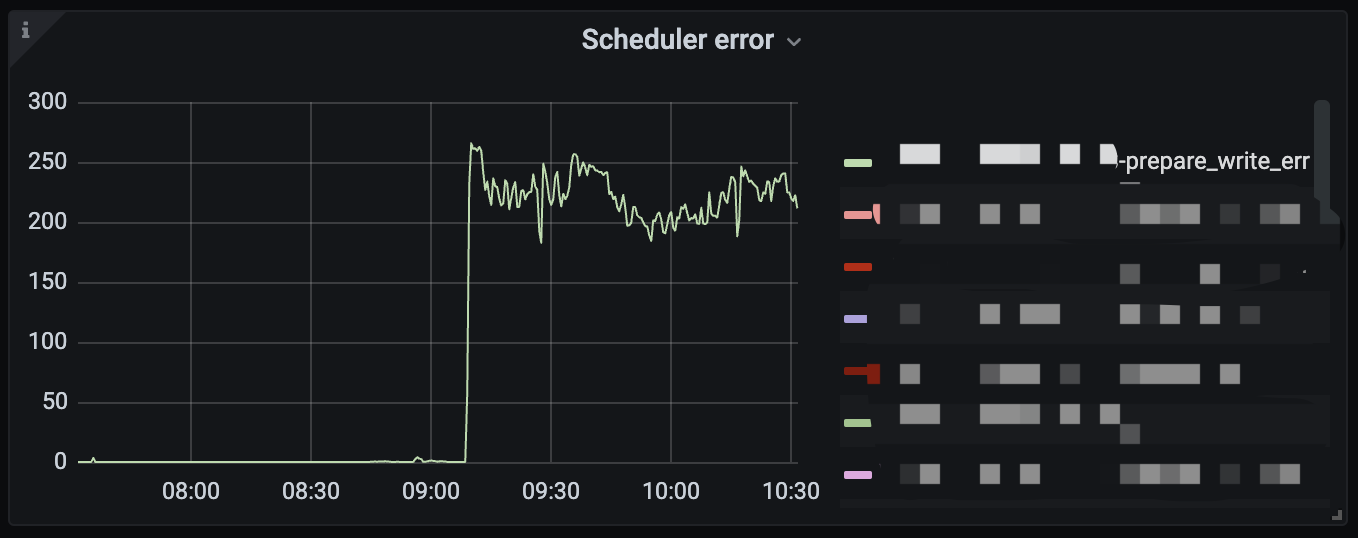
【Reproduction Path】After one TiKV node restarts, another node starts outputting prepare_write_err exceptions.
【Encountered Problem: Symptoms and Impact】Overall cluster latency increases
【Resource Configuration】8 TiKV machines, 24 instances
【Attachments: Screenshots/Logs/Monitoring】
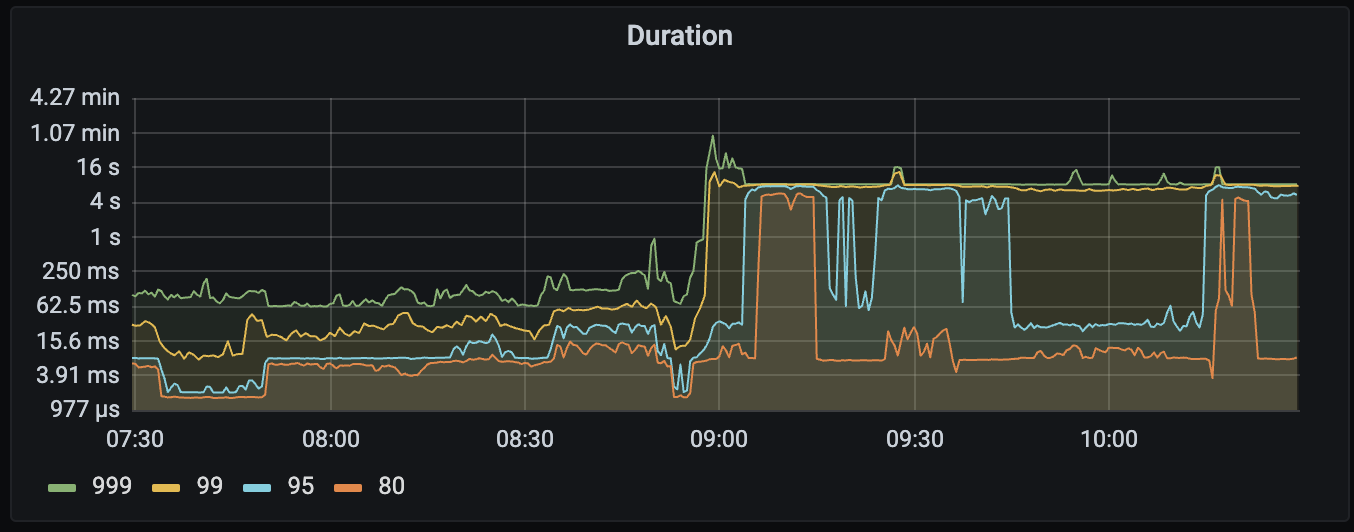
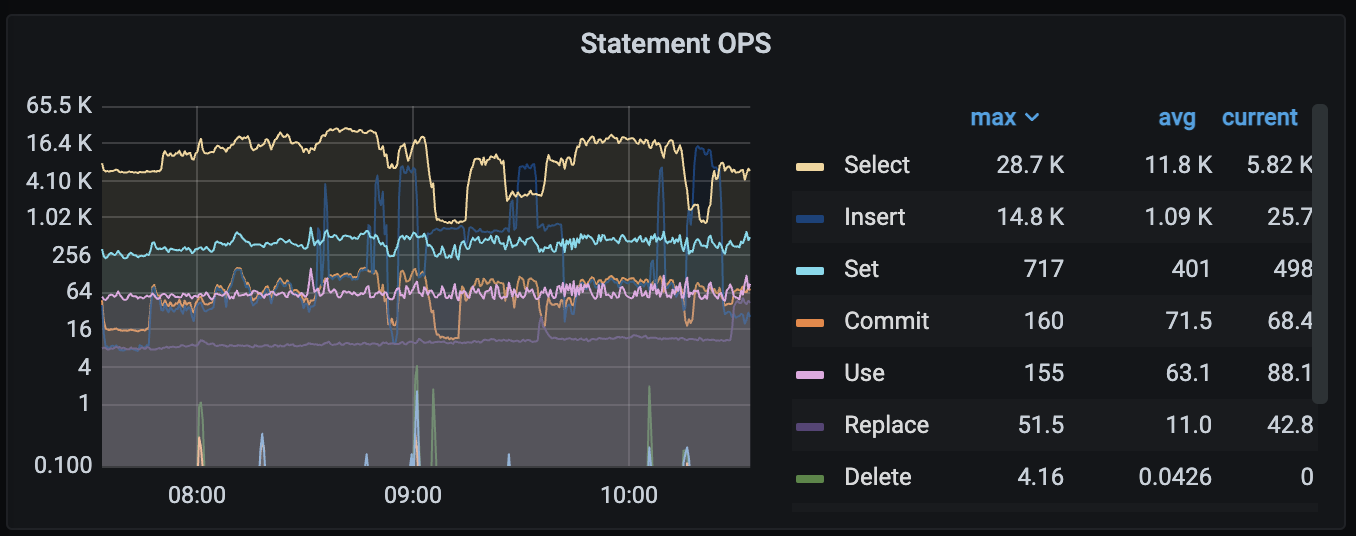
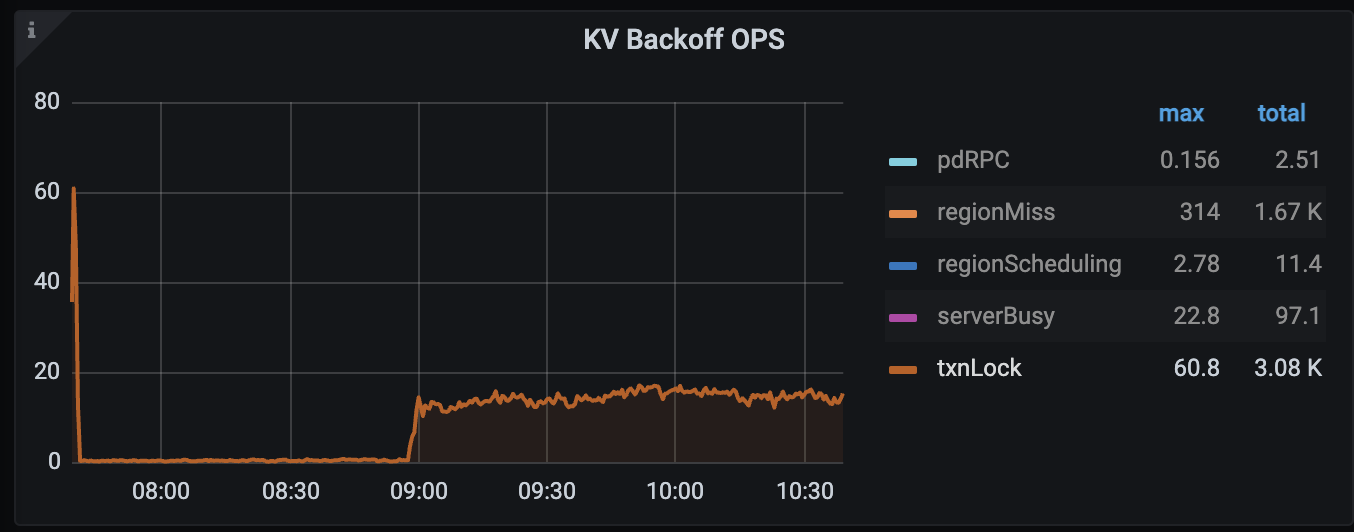
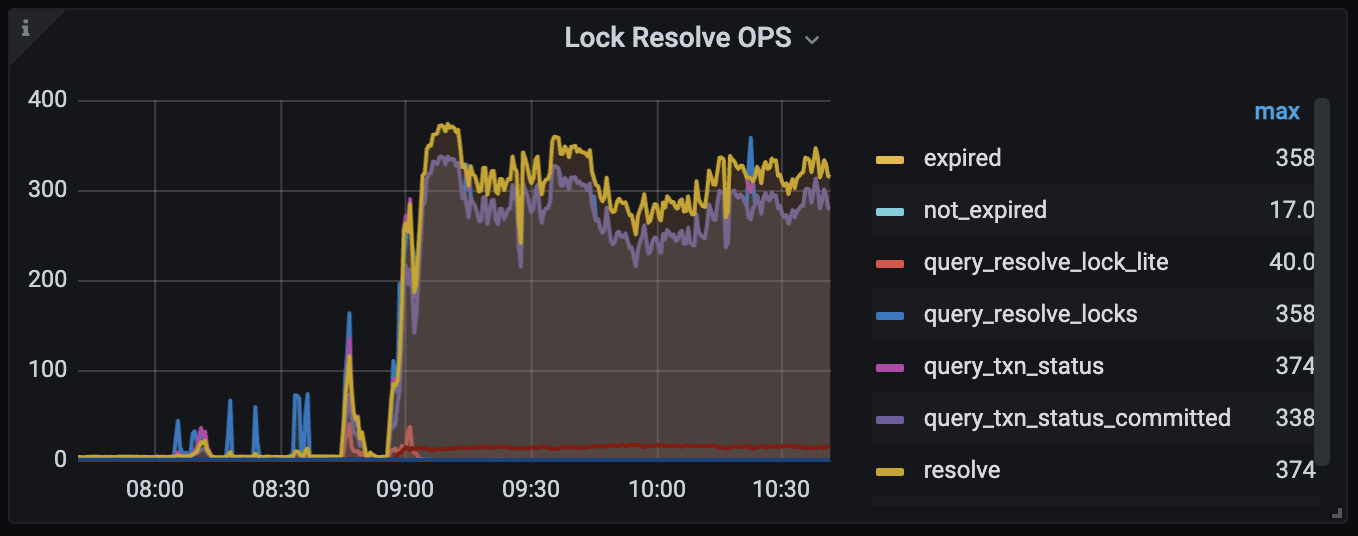
TiDB node reports an error:
[2023/11/09 11:15:08.205 +08:00] [WARN] [session.go:1966] [“run statement failed”] [schemaVersion=233964] [error=“previous statement: update mysql.table_cache_meta set lock_type = ‘READ’, lease = 445513650692423680 where tid = 203252: [kv:9007]Write conflict, txnStartTS=445513651491963030, conflictStartTS=445513651491963037, conflictCommitTS=0, key={tableID=57, handle=203252} primary=byte(nil) [try again later]”] [session=“{\n "currDBName": "",\n "id": 0,\n "status": 2,\n "strictMode": true,\n "user": null\n}”]
[2023/11/09 11:15:08.205 +08:00] [WARN] [cache.go:205] [“lock cached table for read”] [error=“previous statement: update mysql.table_cache_meta set lock_type = ‘READ’, lease = 445513650692423680 where tid = 203252: [kv:9007]Write conflict, txnStartTS=445513651491963030, conflictStartTS=445513651491963037, conflictCommitTS=0, key={tableID=57, handle=203252} primary=byte(nil) [try again later]”]