Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: sync-diff-inspector数据校验表结构不一致问题
[TiDB Usage Environment] Production Environment
[TiDB Version] tidb6.1.1, sync_diff_inspector v2.0
[Encountered Problem] sync-diff-inspector data validation table structure inconsistency (upstream MySQL, downstream TiDB)
[Reproduction Path]
Steps:
1. Use dumpling to export the upstream MySQL table structure and data
2. Use lightning to import into TiDB
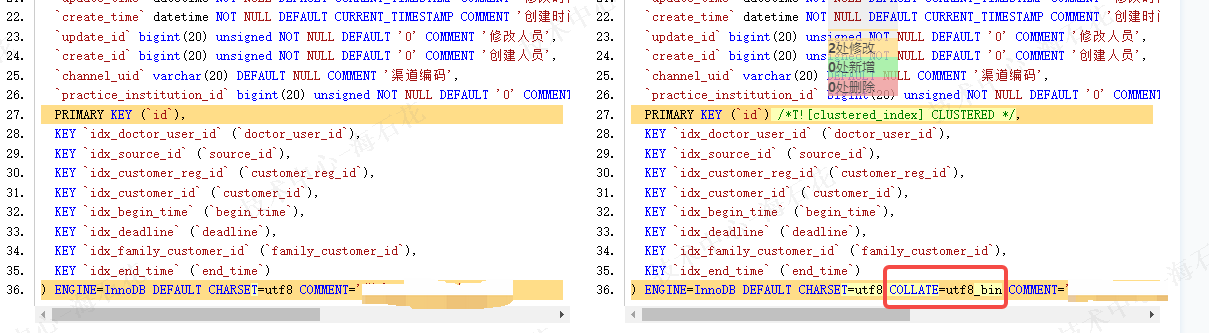
3. During the first step, the exported table structure automatically added the COLLATE=utf8_bin option
4. Use sync-diff-inspector for data validation, it reports that the table structures of the two tables are inconsistent
There are dozens of tables online waiting for data validation, what should I do??
Is no one answering this question… 
Dear experts, please help me~
I think the problem is with the network. You can try to check the network connection between the TiDB server and the PD server.
I have tried setting collation to “utf8_bin” or “utf8_general_ci” here, but it doesn’t work. How exactly should this parameter be used? Also, I have a question: it prompts that the table structure is inconsistent, but it doesn’t indicate where the inconsistency is, nor does it provide any hints or log output?
I’ve read it, read it several times… If you don’t believe me, find it yourself. Where will it print if the table structure is different? 
I previously focused on the issue of data verification, so I can share some insights.
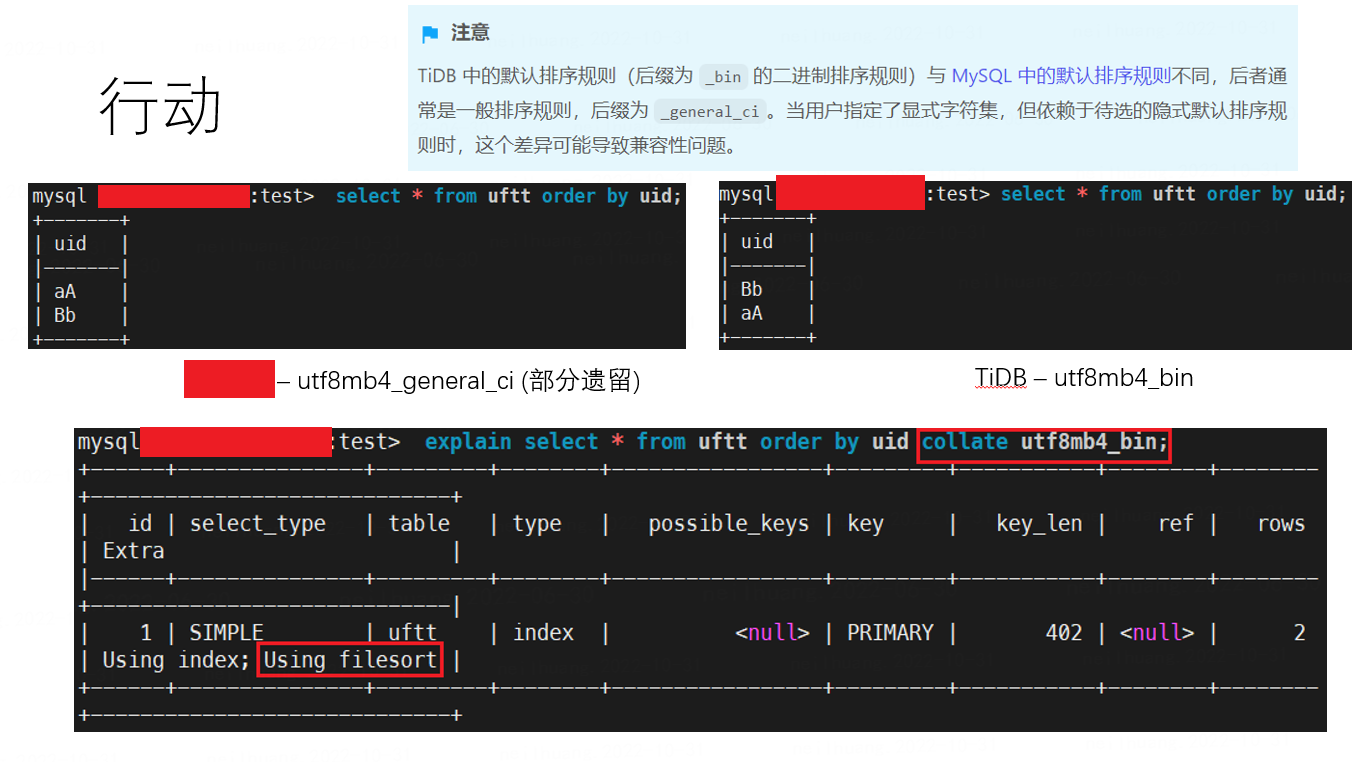
The error is due to the fact that this tool performs sharding and then comparison.
Sharding inevitably involves sorting and then splitting, but if the collation is inconsistent, it will lead to inconsistencies in the way the data is split.
One solution is to explicitly specify the collation during the select operation, but this will use external sorting, which greatly reduces efficiency.
In the end, we did not use this sync-diff tool and switched to another data verification tool.
Which tool did you end up using?
A tool provided by an upstream vendor is currently not publicly available, and we have made modifications to it.
Is this the problem you mentioned? Changing the collation doesn’t work, and adding the collate you mentioned also doesn’t work. What should I do?
I followed the official documentation and changed the collation to the collation of the upstream MySQL table (utf8_general_ci), and then I got this error… Seeking expert advice
Here it is:
The issue I initially reported was later found to be due to inconsistent table structures between upstream and downstream. The primary database didn’t have an index, while the secondary database did. Synchronization followed the primary, and verification followed the secondary. Therefore, the initial troubleshooting was incorrect. The error was not due to collation but was caused by the missing index.
The error screenshot I posted later was indeed due to incorrect chunk calculation, leading to synchronization failure.
Here are my solutions:
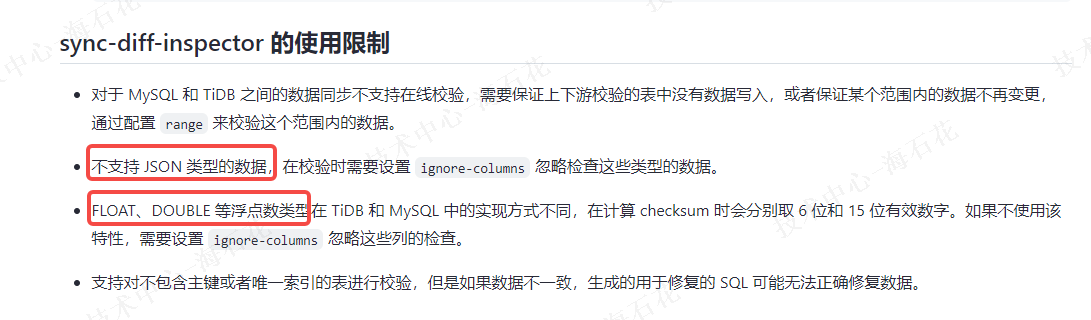
- Review the table structures involved in the verification and ignore all text, blob, and json formats. This is likely to be useful.
- Adjust the chunk_size; sometimes it helps.
- Do not set the verification rules for the table individually. Let the tool scan the entire table; sometimes this works.
-
The issue I initially reported was later found to be due to inconsistent table structures between upstream and downstream. The primary database had no index, while the secondary database had an index. Synchronization followed the primary, and verification followed the secondary. Therefore, the initial troubleshooting was incorrect. The error was not due to collation but was caused by the missing index.
→ The explanation is problematic. “Using sync-diff-inspector for data verification, it indicates that the table structures of the two tables are inconsistent” should indeed point out the collation difference. The workaround collate should be the solution to this problem. (The first cause and effect do not correspond)
-
The error screenshot I posted later was indeed due to incorrect chunk calculation, leading to synchronization failure.
→ Incorrect chunk calculation indicates data inconsistency. Sync-diff is based on indexes to divide chunks, and then both upstream and downstream simultaneously take the CDC32 calculation results within the chunk. In other words, if the chunk is incorrect, it means data inconsistency (it could also be an issue with chunk division between upstream and downstream). (Incorrect chunk calculation cannot be considered the root cause, only a phenomenon)
-
Check the table structures involved in the verification and ignore all text, blob, and json formats. This is likely useful.
→ This is likely useful, but it’s unclear which step is being bypassed to achieve this usefulness.
-
Adjust the chunk_size; sometimes it helps.
→ For small tables, it might directly perform a full table scan without using indexes to distinguish chunks, which might feel somewhat similar to the following point. (Personal guess)
-
Do not set the verification rules for this table separately; let the tool perform a full table scan operation. Sometimes it helps.
→ The phenomenon and underlying principle are also unclear.
However, I think there might be inconsistent index data in your downstream.  I suggest performing an admin check table to avoid future production issues.
I suggest performing an admin check table to avoid future production issues.
Thank you for the reply~ The issue I mentioned and the measures I took are aimed at situations involving many databases and tables, not just a single database or table. At least for now, the daily detection tasks have stabilized, and there are no other issues.
The official recommendation is also to ignore certain types of columns:
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.