Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: INSERT INTO ON DUPLICATE KEY UPDATE失效问题
tidb 4.0.13
sql_mode STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
Business table: There is an auto-increment primary key and a unique composite index uk_name(a,b,c), with data types bigint(20), varchar(100), and varchar(20) respectively.
Character set: utf8mb4
Collation: utf8mb4_bin
Phenomenon: There is an issue where some INSERT INTO ON DUPLICATE KEY UPDATE operations (indicating Query OK, 2 rows affected) fail (the insert does not include the primary key field, only the composite unique index and other fields, and the update part involves non-unique index fields). That is, when encountering duplicate values, the update part is not executed (due to the sensitivity of business data, screenshots are not convenient).
However, when creating a new database in the current instance and using the create table like method to create the business table in the new database, and then inserting this row of data into the new table, executing the same INSERT INTO ON DUPLICATE KEY UPDATE achieves the expected result.
Moreover, this issue only affects some data in the business table.
Replacing INSERT INTO ON DUPLICATE KEY UPDATE with replace shows the same phenomenon. Additionally, during testing, it was found that executing and querying within a transaction works fine. The specific process is as follows:
Test:
- Start a new transaction and record the current data through select.
- Execute INSERT INTO ON DUPLICATE KEY UPDATE (indicating Query OK, 2 rows affected).
- Query again and find that it matches the expectation (the update part is executed, and the data is updated).
- Commit the transaction (Query OK, 0 rows affected).
- Query again and find that the data has not been persisted, i.e., it is still the original data.
Another test was conducted by removing the ON DUPLICATE KEY UPDATE part from INSERT INTO ON DUPLICATE KEY UPDATE, leaving only insert into, which directly reported a unique key conflict, indicating that the unique index constraint is fine.
Tests on update and delete operations showed that direct update (update table set col1=‘xxx’, col2=‘yyy’ where a = ‘’ and b = ‘’ and c = ‘’) also did not work, and delete (delete from table where a = ‘’ and b = ‘’ and c = ‘’) had the same issue. The difference is that after delete execution, the auto-increment primary key changes, but other field data remains unchanged.
Therefore, I would like to ask for troubleshooting ideas for this issue.
Additional Information
Table structure
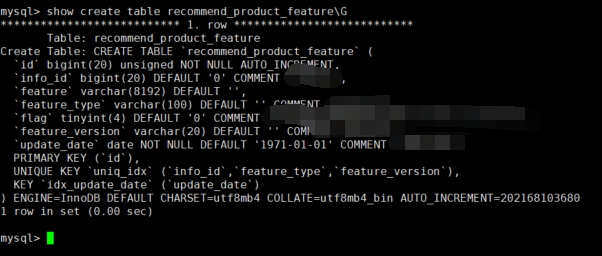
Update test, updating the time field from 2023-01-11 to 2023-01-12, first querying to find 25 matching rows
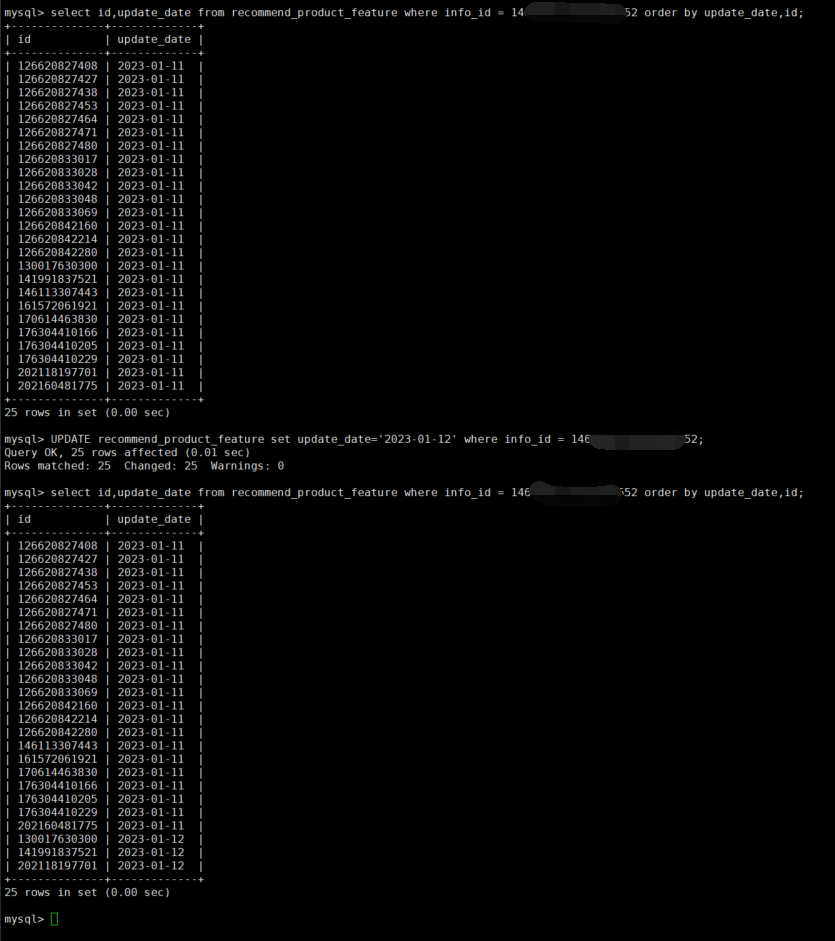
It can be seen that the update statement returns a result indicating 25 rows updated, but in reality, only three rows were updated.
Operation within a transaction
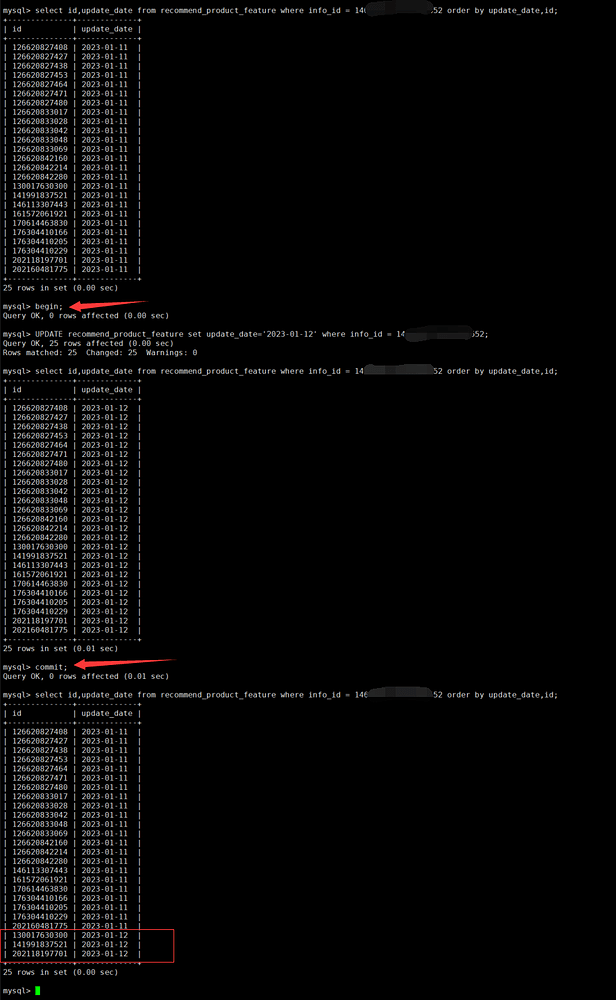
It can be seen that within the transaction, the operation meets expectations, but after committing and querying again, only some data is updated.
Execution plan

Summary of the issue:
When performing DML operations on data, some data exhibits DML anomalies:
- insert into on duplicate update update ---- Based on the unique key
- direct update — Updating based on the first field of the unique key, only some data is changed
- delete (primary key changes after delete execution) — Based on the unique key
Only some data has issues, not all data, and it cannot be consistently reproduced in other environments