Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 关于tablereader算子的copr_cache问题
[TiDB Usage Environment] Test
[TiDB Version] 5.7
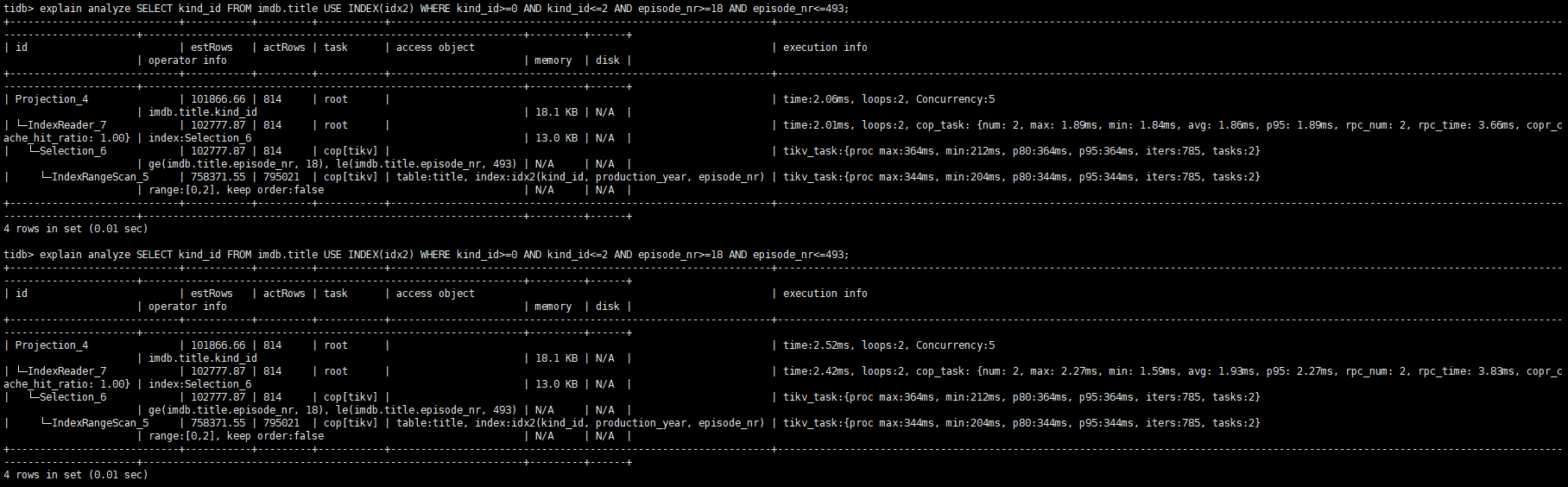
[Encountered Problem] The same SQL executed twice has a significant time difference. After checking the plan, it was found that the time difference is mainly caused by the tablereader operator. One shows copr_cache_hit=1.0, while the other does not. May I ask which level of cache this is? Is it the block cache of RocksDB? Or is it the cache at the TiKV layer? Can this cache be controlled to enable or disable, or can its size be adjusted?
[Reproduction Path] What operations were performed to encounter the problem
[Problem Phenomenon and Impact]
[Attachment]
Please provide the version information of each component, such as cdc/tikv, which can be obtained by executing cdc version/tikv-server --version.