Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 关于分区表的主键问题
[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version]
[Reproduction Path] What operations were performed to encounter the issue
[Encountered Issue: Issue Phenomenon and Impact]
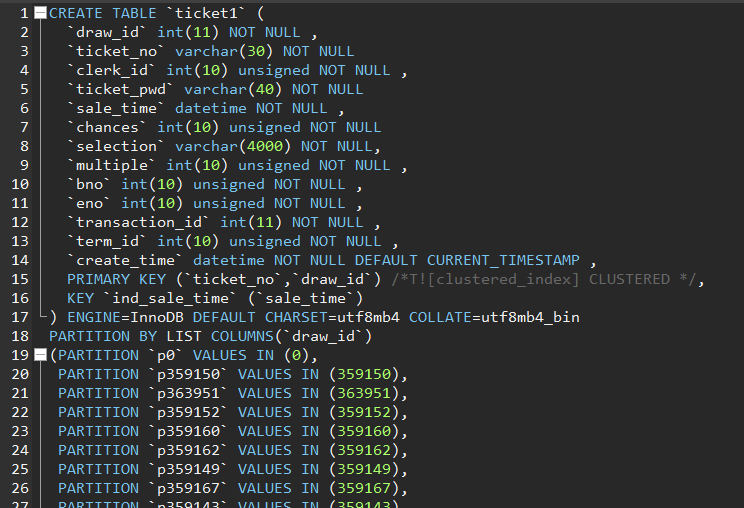
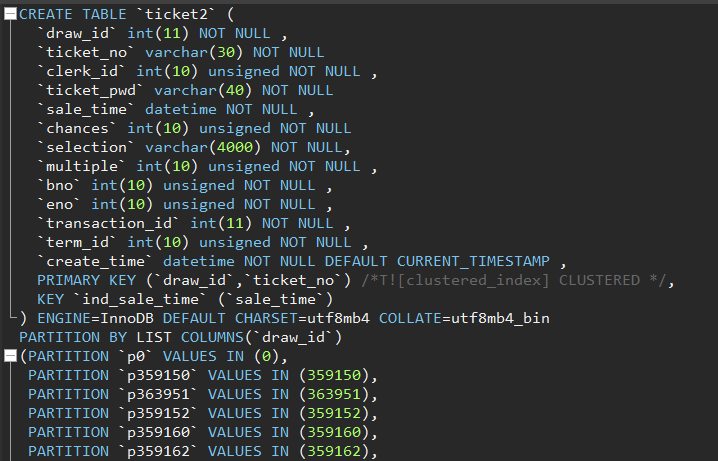
Test Case: There are two partitioned tables, both using list partitioning with the partition key draw_id. The difference is in the primary key. The primary key for ticket2 is (draw_id, ticket_no), while for ticket1 it is (ticket_no, draw_id). The data volume is 27 million, and the data is exactly the same. The table creation statements are as follows:
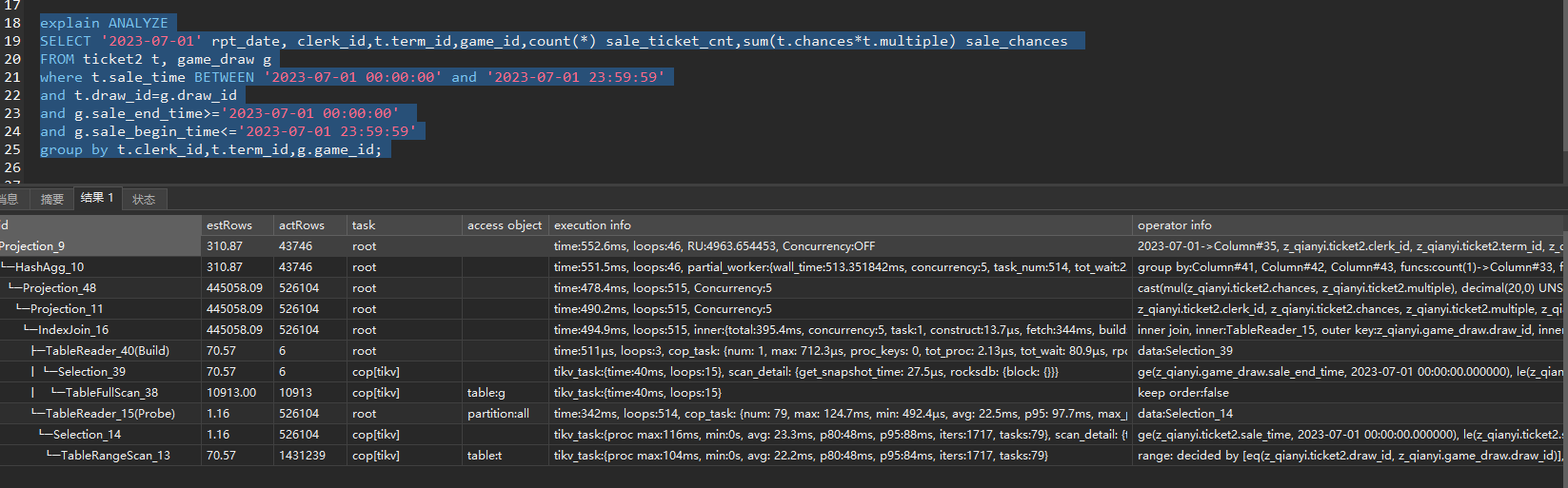
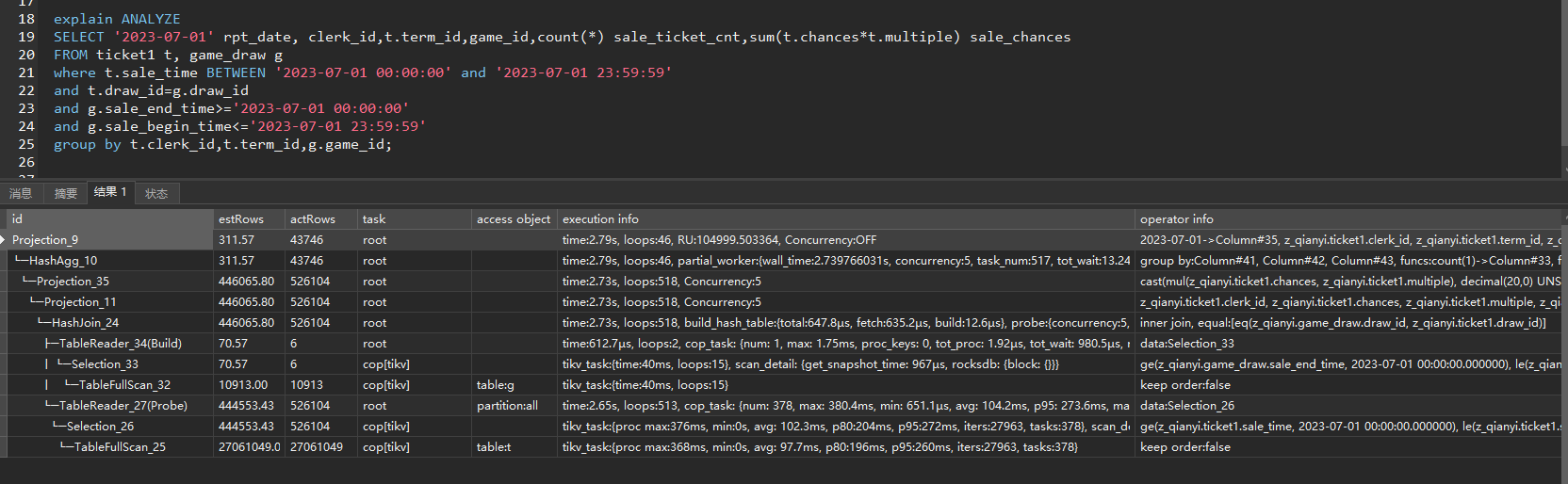
The execution plans for the same SQL are different
The issue is:
Partitioned tables require the partition key to be part of the primary key, making the primary key a composite key. Does the partition key have to be the first column in the primary key index? In my test, if the partition key is the second column, the SQL performs a full table scan.
From the test, when partitioning by draw_id, as long as draw_id is not in the first position of the primary key, the execution plan will perform a full table scan.
It’s the leftmost prefix principle of the index (Huh? What? You said the join key draw_id is the partition key of the list partition table, so it can’t use NL_JOIN and then partition pruning to do a full partition scan? Maybe it just hasn’t been implemented yet  )
)
Theoretically, having the partition key in the where condition should directly query these partitions instead of performing a full table scan, so this is quite puzzling.
You’re talking about the simple query on the second floor, right? Both of them went through partition pruning. You can see the partition keyword in the access object. Actually, TiDB doesn’t have an operator for full partition scan; a full partition scan is displayed as a full table scan.
Is there a difference in execution time between the two SQL queries?
Whether the primary key index should be the first or second depends on the filtering conditions used.
The actrows of the two SQLs are the same. The upper SQL follows the leftmost index principle and uses index join, while the lower SQL does not have a suitable index and uses hash join. If you create an index for the table in the lower SQL, both will be the same.
The training video for TiDB explains the basics well. Not bad. I don’t use partitioned tables much either. But it’s covered in the video, though the video can’t consider all scenarios.
The query result speed of the second floor’s SQL query is the same. I think the estimated number of rows in the execution plan is incorrect.
It seems that there is an issue with the execution plan display, but the actual execution is fine.