Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: sync_differ_inspector问题
[Environment]
Source: v5.2.3, table with 200 million rows, approximately 167 varchar(100) fields, only 1 FILEDATE is an int field
Target: v6.1.1, empty table
sync_diff_inspector: v2.0
Table index:
TABLE_NAME varchar(100) NOT NULL,
FILE_NAME varchar(100) DEFAULT NULL,
FILEDATE int(11) NOT NULL,
PRIMARY KEY (TABLE_NAME,FILEDATE) /*T![clustered_index] NONCLUSTERED */,
KEY INX_USAIMS_FILENAME_20220913 (FILENAME),
KEY INX_USAIMS_CALLNUMBER_20220913 (CALLINGNUMBER,CALLEDNUMBER)
)
PARTITION BY LIST (FILEDATE)
(PARTITION P20220901 VALUES IN (20220901),
PARTITION P20220902 VALUES IN (20220902),
Configuration file parameters:
check-thread-count = 4
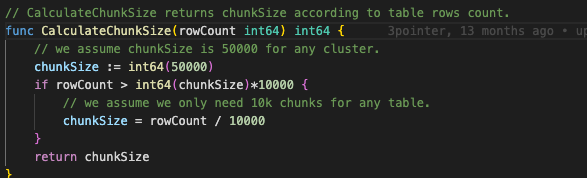
chunk-size = 10000
[Process]
Using one table for sync_diff check, using show processlist to check the executed SQL, only one full table scan:
select xxx as CHECKSUM FROM jiesuan.T_GIMS_USAGE_13_202209 WHERE ((TRUE) AND (TRUE))
[Questions]
-
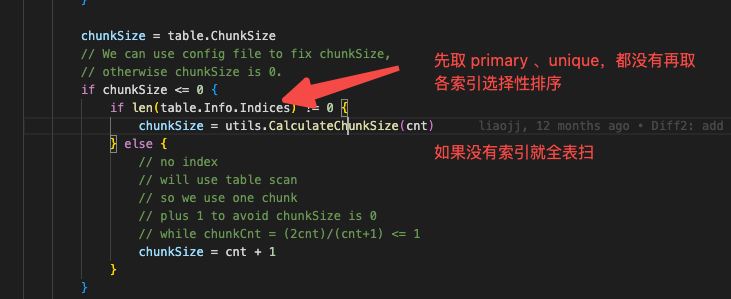
From the show processlist results, it seems that chunks are not divided. Is chunk division only possible with single-column int type primary keys or unique indexes?
-
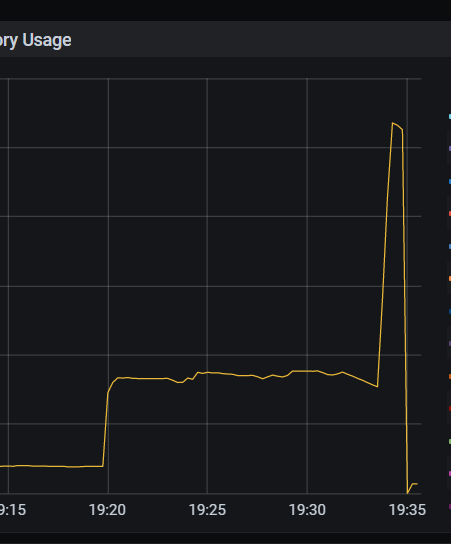
If chunks are not divided and a full table scan is performed, does the TiDB server store the entire table data in memory and release it only after the full table comparison is completed, or does it release part of the memory after comparing part of the data?
-
Does the check-thread-count concurrency apply to the number of threads for a single table or the number of threads for the entire database (e.g., checking a batch of tables through regex)? Why is the upstream slightly larger than this value, and by approximately how much?
check-thread-count # Number of threads for checking data, the number of connections to the upstream and downstream databases will be slightly larger than this value -
After running for a while, the TiDB memory suddenly increases, causing OOM. Why does it suddenly increase? (Tried twice, the sudden increase occurred around 15 minutes)