Three servers (201, 202, 203) form a TiDB cluster, with each server deploying TiDB/PD/TiKV/TiFlash. To test the high availability of the cluster, a network disconnection test was conducted:
2022-08-31 22:36: Disconnected the network of server 202 for testing. After connecting with the database connection tool, the query reported “Region is unavailable” (this error was reported when querying through haproxy’s 3390, single node 201:4000, and 203:4000 ports).
2022-08-31 23:40: Disconnected the network of server 201 for testing. The database connection tool query was normal (queries through haproxy’s 3390, single node 202:4000, and 203:4000 ports were all normal).
2022-08-31 23:53: Disconnected the network of server 203 for testing. The database connection tool query was normal (queries through haproxy’s 3390 and single node 4000 ports were all normal).
2022-09-01 00:21: After reconnecting the network of all servers, the overall log was tested. The database connection tool query was normal (queries through haproxy’s 3390 and single node 4000 ports were all normal). Attached are the logs of each server Server Logs 20220901.rar (1.5 MB)
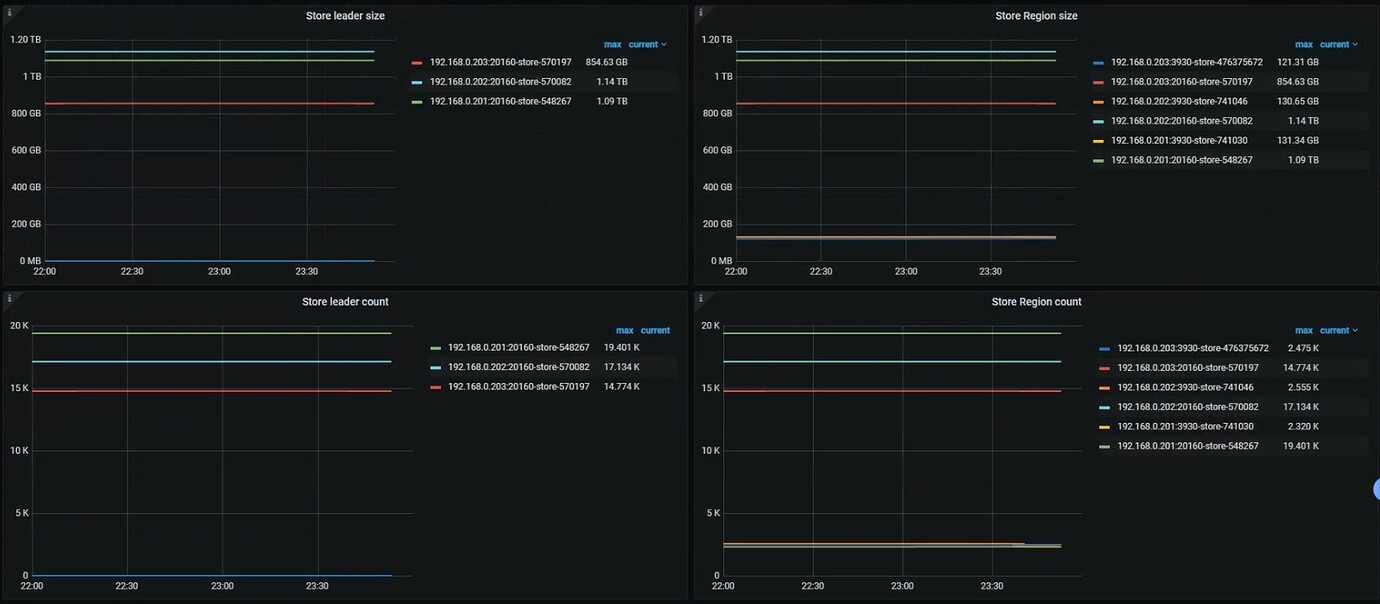
Node 202, which is disconnected from the network, should have some regions with the leader role. You can check if there were any abnormal messages before the disconnection.
First, the network was disconnected around 22:33:00, and the leaders of other stores did not increase, which triggered the issue of “Region is unavailable”;
The disappearance of the Region heartbeat report was expected due to the network disconnection.
The absence of balance-leader operator was unexpected and also triggered point 1;
During the failure period of 202, the PD leader was 203, and it was not the PD leader that was killed.
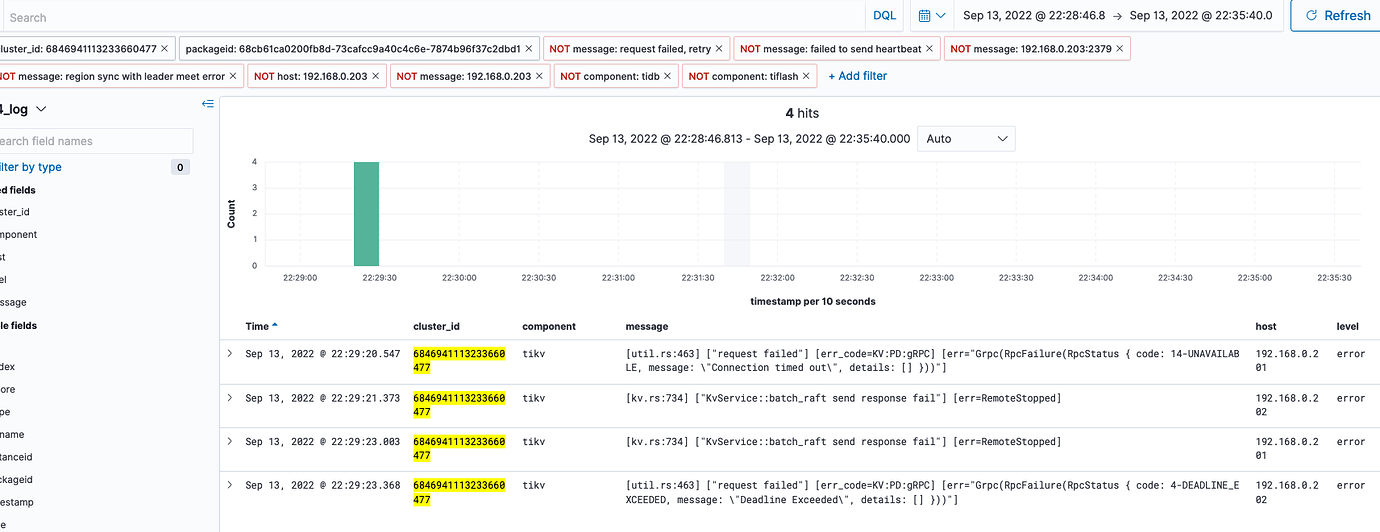
Looking closely at the log, after removing some useless logs using expressions, the content is as follows: 203 rpc failed to connect to itself, but in fact, the network connection to itself should be fine:
For the new version, please provide another clinic. My machine is not sufficient to reproduce the issue as it is.
Is it always this node that has the problem? If so, kill this node’s PD and then collect the clinic to avoid interference from other information.
If only this node has the problem, you can ask the network team if there is anything special about this node.
The strange point now is that killing the leader does not report region unavailable, but killing an irrelevant PD reports an error. However, monitoring shows that the region has not been scheduled.
If you are willing to try, you can also configure a Label for them to see if it bypasses the issue (this is just an attempt because regions are not scheduled to the same host by default, it feels like there is some problem with the scheduling).
Is the cluster set to log.level == error? It’s hard to see the specific behavior of the components , for example, when the PD leader switch is completed. Some information points need to be viewed at the info or even debug log level.
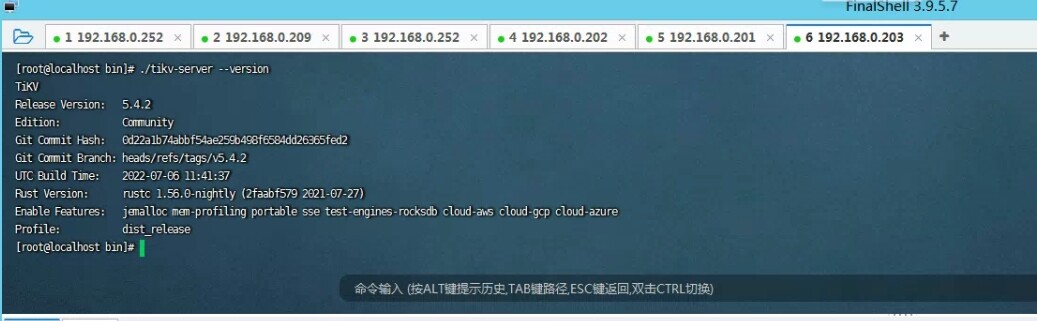
There seems to be no problem with the patch command. You can go to the TiKV deploy directory and use ./tikv-server --version to check if the patch was successful.
This time, the scheduler looks normal. By the way, do you often use ctrl + c during testing? This can easily leave behind evict-leader-scheduler, or the network disconnection test intervals are too frequent.
The internal balance-leader mechanism in PD is actually running, but it hasn’t generated a real balance leader operator.
First, remove the evict-leader this time, then check each panel to ensure there are no anomalies. Disconnect the network (only one machine), then use the following statement to check. See if it can be reproduced. If it can be reproduced, check again after 15 minutes. If it still can be reproduced, use the following statement to check the results. Finally, restore the network. After the cluster returns to normal, take the clinic results from 10 minutes before the disconnection and 10 minutes after the cluster returns to normal, as well as several results from trace select ......
trace select * from XXX;
By the way, this time the clinic did not include information before the disconnection.
Each clinic gives a slightly different feeling It doesn’t seem like the same issue.