Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: cdc好像自动过滤了INSERT语句并且checkpoint没变化
[TiDB Usage Environment] Production Environment
[TiDB Version] v7.1.5
[Encountered Issue: Problem Phenomenon and Impact]
Recently upgraded the TiDB cluster from v5.4.3 to v7.1.5 to introduce the ticdc filter rule feature and improve performance.
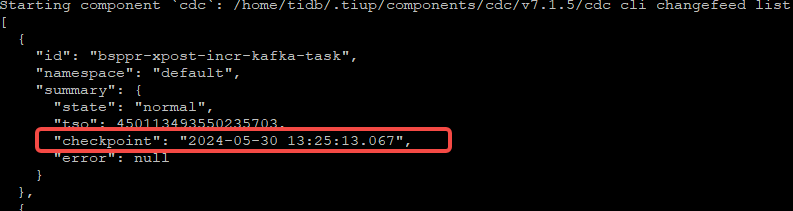
After the upgrade, when creating a cdc changefeed, it seems that the task automatically filters out INSERT statements, but there are UPDATE statements, which is very strange~
Also, the checkpoint hasn’t changed.
Could you please help me check where the problem is? Is there an issue with my configuration file? But my filter rules are quite simple.
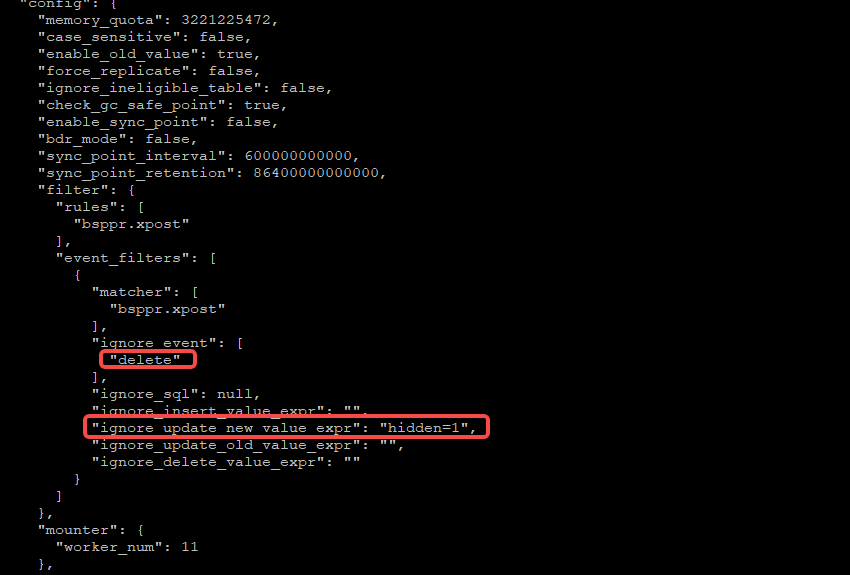
Configuration file:
# Specifies the upper limit of the memory quota for this Changefeed in the Capture Server. The excess usage will be prioritized for recovery by the Go runtime during operation. The default value is `1073741824`, which is 1 GB.
# memory-quota = 1073741824
memory-quota = 3221225472
# Specifies whether the database and table names involved in the configuration file are case-sensitive.
# This configuration affects both filter and sink related configurations. Since v6.5.6 and v7.1.3, the default value has been changed from true to false.
case-sensitive = false
# Whether to output old value, supported since v4.0.5, and defaulted to true since v5.0.
enable-old-value = true
# Whether to enable the Syncpoint feature, supported since v6.3.0, and disabled by default.
# Since v6.4.0, using the Syncpoint feature requires the synchronization task to have SYSTEM_VARIABLES_ADMIN or SUPER privileges on the downstream cluster.
# Note: This parameter only takes effect when the downstream is TiDB.
# enable-sync-point = false
# The interval for aligning snapshots between upstream and downstream using the Syncpoint feature.
# The configuration format is h m s, such as "1h30m30s".
# The default value is 10m, with a minimum value of 30s.
# Note: This parameter only takes effect when the downstream is TiDB.
# sync-point-interval = "5m"
# The duration for which data saved in the downstream table by the Syncpoint feature is retained. Data exceeding this time will be cleaned up.
# The configuration format is h m s, such as "24h30m30s".
# The default value is 24h.
# Note: This parameter only takes effect when the downstream is TiDB.
# sync-point-retention = "1h"
# Introduced since v6.5.6 and v7.1.3, used to set the SQL mode used when parsing DDL. Multiple modes are separated by commas.
# The default value is consistent with TiDB's default SQL mode.
# sql-mode = "ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
[mounter]
# The number of threads for mounter to decode KV data, default value is 16.
worker-num = 11
[filter]
# Ignore transactions with specified start_ts.
# ignore-txn-start-ts = [1, 2]
# Filter rules
# Filter rule syntax: https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法
# rules = ['*.*', '!test.*']
rules = ['bsppr.xpost']
# Event filter rules
# Detailed configuration rules for event filters can be found at: https://docs.pingcap.com/zh/tidb/stable/ticdc-filter
# First event filter rule
# [[filter.event-filters]]
# matcher = ["test.worker"] # matcher is a whitelist, indicating that this filter rule only applies to the worker table in the test database.
# ignore-event = ["insert"] # Filter out insert events.
# ignore-sql = ["^drop", "add column"] # Filter out DDLs starting with "drop" or containing "add column".
# ignore-delete-value-expr = "name = 'john'" # Filter out delete DMLs containing the condition name = 'john'.
# ignore-insert-value-expr = "id >= 100" # Filter out insert DMLs containing the condition id >= 100.
# ignore-update-old-value-expr = "age < 18" # Filter out update DMLs with old value age < 18.
# ignore-update-new-value-expr = "gender = 'male'" # Filter out update DMLs with new value gender = 'male'.
[[filter.event-filters]]
matcher = ['bsppr.xpost']
ignore-event=["all ddl","delete"]
ignore-update-new-value-expr = "hidden=1"
# Second event filter rule
# [[filter.event-filters]]
# matcher = ["test.fruit"] # This event filter only applies to the test.fruit table.
# ignore-event = ["drop table", "delete"] # Ignore drop table DDL events and delete type DML events.
# ignore-sql = ["^drop table", "alter table"] # Ignore DDLs starting with drop table or containing alter table.
# ignore-insert-value-expr = "price > 1000 and origin = 'no where'" # Ignore insert DMLs containing the conditions price > 1000 and origin = 'no where'.
[scheduler]
# Distribute tables to multiple TiCDC nodes for synchronization by Region.
# Note: This feature only takes effect on Kafka changefeed and does not support MySQL changefeed.
# The default is "false". Set to "true" to enable this feature.
enable-table-across-nodes = true
# After enable-table-across-nodes is enabled, there are two allocation modes:
# 1. Allocate by the number of Regions, i.e., each CDC node processes an approximately equal number of regions. When the number of Regions in a table exceeds the `region-threshold` value, the table will be allocated to multiple nodes for processing. The default value of `region-threshold` is 10000.
# region-threshold = 10000
# 2. Allocate by write traffic, i.e., each CDC node processes an approximately equal number of modified rows. This mode only takes effect when the number of modified rows per minute in the table exceeds the `write-key-threshold` value.
# write-key-threshold = 30000
write-key-threshold = 30000
# Note:
# The default value of the `write-key-threshold` parameter is 0, which means that the allocation mode by traffic is not used by default.
# Only one of the two methods can take effect. When both `region-threshold` and `write-key-threshold` are configured, TiCDC will prioritize the allocation mode by traffic, i.e., `write-key-threshold`.
[sink]
# For MQ type Sink, event dispatchers can be configured through dispatchers.
# Supports two types of event dispatchers: partition and topic (supported since v6.1). Detailed descriptions of both can be found in the next section.
# The matching syntax of matcher is the same as the filter rule syntax. Detailed descriptions of matcher matching rules can be found in the next section.
# Note: This parameter only takes effect when the downstream is a message queue.
# dispatchers = [
# {matcher = ['test1.*', 'test2.*'], topic = "Topic Expression 1", partition = "ts" },
# {matcher = ['test3.*', 'test4.*'], topic = "Topic Expression 2", partition = "index-value" },
# {matcher = ['test1.*', 'test5.*'], topic = "Topic Expression 3", partition = "table"},
# {matcher = ['test6.*'], partition = "ts"}
# ]
dispatchers = [
{matcher = ['bsppr.xpost'], dispatcher = "default"},
]
# The protocol used to specify the format of the data passed to the downstream.
# When the downstream type is Kafka, supports canal-json and avro protocols.
# When the downstream type is a storage service, currently only supports canal-json and csv protocols.
# Note: This parameter only takes effect when the downstream is Kafka or a storage service.
# protocol = "canal-json"
protocol = "canal-json"
# The following three configuration items are only used in the sink for storage services and do not need to be set in MQ and MySQL type sinks.
# Line break character, used to separate two data change events. The default value is empty, which means using "\r\n" as the line break character.
# terminator = ''
# The date separator type for the file path. Optional types are `none`, `year`, `month`, and `day`. The default value is `day`, which means separating by day. See <https://docs.pingcap.com/zh/tidb/v7.1/ticdc-sink-to-cloud-storage#数据变更记录> for details.
# Note: This parameter only takes effect when the downstream is a storage service.
date-separator = 'day'
# Whether to use partition as the separator string. The default value is true, which means that data from different partitions in a table will be stored in different directories. It is recommended to keep this configuration item as true to avoid the issue of data loss in downstream partition tables <https://github.com/pingcap/tiflow/issues/8581>. See <https://docs.pingcap.com/zh/tidb/v7.1/ticdc-sink-to-cloud-storage#数据变更记录> for usage examples.
# Note: This parameter only takes effect when the downstream is a storage service.
enable-partition-separator = true
# The URL of the Schema registry.
# Note: This parameter only takes effect when the downstream is a message queue.
# schema-registry = "http://localhost:80801/subjects/{subject-name}/versions/{version-number}/schema"
# The number of threads used by the encoder when encoding data.
# The default value is 16.
# Note: This parameter only takes effect when the downstream is a message queue.
# encoder-concurrency = 16
# Whether to enable Kafka Sink V2. Kafka Sink V2 is implemented internally using kafka-go.
# The default value is false.
# Note: This parameter only takes effect when the downstream is a message queue.
# enable-kafka-sink-v2 = false
# Whether to synchronize only columns with content updates to the downstream. Supported since v7.1.0.
# The default value is false.
# Note: This parameter only takes effect when the downstream is a message queue and uses Open Protocol or Canal-JSON.
# only-output-updated-columns = false
# Since v6.5.0, TiCDC supports saving data change records to storage services in CSV format, and does not need to be set in MQ and MySQL type sinks.
# [sink.csv]
# The delimiter between fields. Must be an ASCII character, the default value is `,`.
# delimiter = ','
# The quote character used to wrap fields. An empty value means no quote character is used. The default value is `"`.
# quote = '"'
# The character used to represent NULL in CSV columns. The default value is `\N`.
# null = '\N'
# Whether to include commit-ts in CSV rows. The default value is false.
# include-commit-ts = false
# The encoding method for binary type data, optional 'base64' or 'hex'. Supported since v7.1.2. The default value is 'base64'.
# binary-encoding-method = 'base64'
# The fields in consistent are used to configure the data consistency of Changefeed. For detailed information, please refer to <https://docs.pingcap.com/tidb/stable/ticdc-sink-to-mysql#eventually-consistent-replication-in-disaster-scenarios>.
# Note: Consistency-related parameters only take effect when the downstream is a database and the redo log feature is enabled.
[consistent]
# Data consistency level. The default value is "none", optional values are "none" and "eventual".
# Setting it to "none" will disable the redo log.
level = "none"
# The maximum log size of the redo log, in MB. The default value is 64.
max-log-size = 64
# The interval between two redo log flushes, in milliseconds. The default value is 2000.
flush-interval = 2000
# The URI for storing redo logs. The default value is empty.
storage = ""
# Whether to store redo logs in local files. The default value is false.
use-file-backend = false
# The number of encoding workers in the redo module, the default value is 16.
encoding-worker-num = 16
# The number of workers uploading files in the redo module, the default value is 8.
flush-worker-num = 8
# The compression behavior of redo log files, optional values are "" and "lz4". The default value is "", which means no compression.
compression = ""
# The concurrency for uploading a single redo log file, the default value is 1, which means disabling concurrency.
flush-concurrency = 1
[integrity]
# Whether to enable the Checksum verification function for single-row data, the default value is "none", which means it is not enabled. Optional values are "none" and "correctness".
integrity-check-level = "none"
# The log level for printing error row data related logs when the Checksum verification for single-row data fails. The default value is "warn", optional values are "warn" and "error".
corruption-handle-level = "warn"
## The following parameters only take effect when the downstream is Kafka. Supported since v7.1.1.
#[sink.kafka-config]
## Kafka SASL authentication mechanism. The default value is empty, which means SASL authentication is not used.
#sasl-mechanism = "OAUTHBEARER"
## The client-id in the Kafka SASL OAUTHBEARER authentication mechanism. The default value is empty. This parameter is required when using this authentication mechanism.
#sasl-oauth-client-id = "producer-kafka"
## The client-secret in the Kafka SASL OAUTHBEARER authentication mechanism. The default value is empty. It needs to be Base64 encoded. This parameter is required when using this authentication mechanism.
#sasl-oauth-client-secret = "cHJvZHVjZXIta2Fma2E="
## The token-url in the Kafka SASL OAUTHBEARER authentication mechanism used to obtain the token. The default value is empty. This parameter is required when using this authentication mechanism.
#sasl-oauth-token-url = "http://127.0.0.1:4444/oauth2/token"
## The scopes in the Kafka SASL OAUTHBEARER authentication mechanism. The default value is empty. This parameter is optional when using this authentication mechanism.
#sasl-oauth-scopes = ["producer.kafka", "consumer.kafka"]
## The grant-type in the Kafka SASL OAUTHBEARER authentication mechanism. The default value is "client_credentials". This parameter is optional when using this authentication mechanism.
#sasl-oauth-grant-type = "client_credentials"
## The audience in the Kafka SASL OAUTHBEARER authentication mechanism. The default value is empty. This parameter is optional when using this authentication mechanism.
#sasl-oauth-audience = "kafka"
[sink.cloud-storage-config]
# The concurrency for saving data change records to downstream storage services, the default value is 16.
worker-count = 16
# The interval for saving data change records to downstream storage services, the default value is "2s".
flush-interval = "2s"
# When the byte size of a single data change file exceeds `file-size`, it will be saved to the storage service. The default value is 67108864, which is 64 MiB.
file-size = 67108864
# The retention period of files, only effective when date-separator is configured as day. The default value is 0, which means file cleanup is disabled. Suppose `file-expiration-days = 1` and `file-cleanup-cron-spec = "0 0 0 * * *"`, TiCDC will clean up files saved for more than 24 hours at 00:00:00 every day. For example, at 00:00:00 on 2023/12/02, files before 2023/12/01 (note: excluding 2023/12/01) will be cleaned up.
file-expiration-days = 0
# The execution cycle of the scheduled cleanup task, compatible with crontab configuration, the format is `<Second> <Minute> <Hour> <Day of the month> <Month> <Day of the week (Optional)>`, the default value is "0 0 2 * * *", which means the cleanup task is executed at 2 AM every day.
file-cleanup-cron-spec = "0 0 2 * * *"
# The concurrency for uploading a single file, the default value is 1, which means disabling concurrency.
flush-concurrency = 1
Command:
tiup cdc cli changefeed create -c xxxxxx --server=http://192.168.241.71:8300 --sink-uri=“kafka://192.168.241.64:9092,192.168.241.65:9092,192.168.241.66:9092/tidb-xpost-incr?protocol=canal-json&kafka-version=1.1.1&partition-num=4&max-message-bytes=67108864&replication-factor=2” --config=./xxxxxx.toml