Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: lightning 恢复报错:create TSO stream failed, retry timeout
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.1.0
[Reproduction Path] lightning restore
[Encountered Problem]
When dumping tidbv5.0.6 and executing lightning restore to v6.1.0, an error “create TSO stream failed, retry timeout” occurred.
Check pd log error
[Resource Configuration]
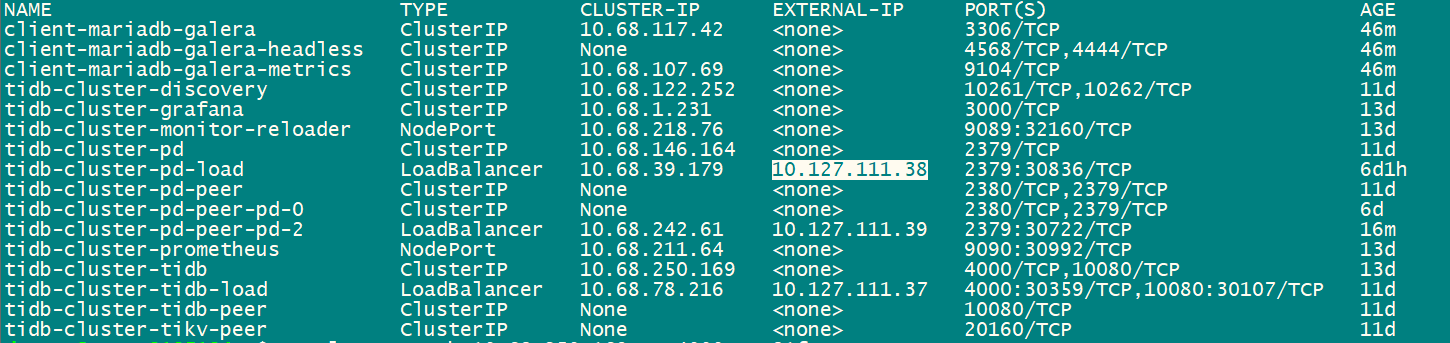
If restoring in lightning local mode, it should be taking the hostmap of TiKV from PD. It seems like it can’t find the corresponding TiKV nodes of the cluster.
Error: “lookup tidb-cluster-pd-2.tidb-cluster-pd-peer.mcd-reng.svc on 100.64.0.101:53: no such host”
tidb-cluster-pd-2 is the PD leader, and this error occurs before reaching the stage of obtaining the hostmap from PD for TiKV.
I don’t understand why the service’s DNS is being resolved when accessing through LoadBalancer.
If the data volume is not large, you can try the logical mode.
Can the address 100.64.0.101:53 be reached?
The data volume is relatively large, more than 1TB, and breakpoint resume is also needed. How can I further troubleshoot the problem?
It can be restored with a k8s cluster, as long as you connect S3 or some network storage for access on both sides.
Cross-data center data migration is quite troublesome. If it can be restored within the same cluster, then just use the same cluster directly.
Is the version of Lightning consistent with the cluster? Is it also 6.1.0?
Data import from v5.0.4 to 6.1.0 using v5.0.4 lightning resulted in an error, suggesting to use v6.1.0 lightning for import:
How about not crossing the k8s cluster and mounting the exported data to the new cluster for recovery?
Cross-data center data migration is quite troublesome. If it can be restored within the same cluster, just use the same cluster.  Please help to look at it from a technical perspective.
Please help to look at it from a technical perspective.
Judging by the error, it seems that the PD node is not accessible. I’m not very familiar with Kubernetes either, let’s wait for responses from other experts.
Adjusting to the same k8s cluster, error message
After adjusting to the same cluster, the error message is shown in the above image.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.