Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 日志堆积问题
[TiDB Usage Environment] Production Environment
[TiDB Version] 7.5
[Reproduction Path] Default installed cluster
[Encountered Issue: Phenomenon and Impact] The tidb component log on one machine is too large
[Resource Configuration]
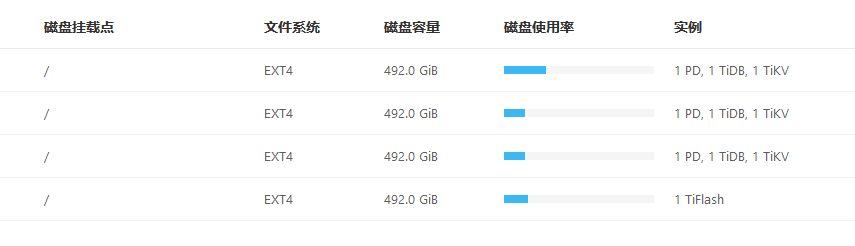
The disk usage on the first machine in the monitoring interface is too large, and it was found to be a tidb log issue.
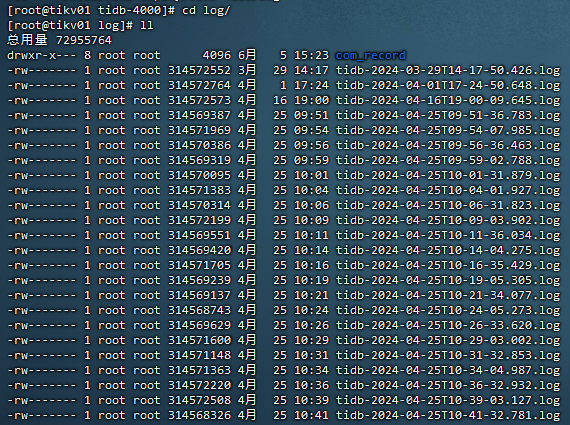
Below are the logs from the problematic server

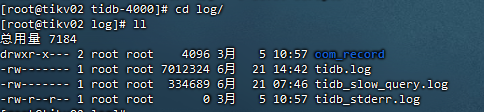
Below are the logs from the normal server

Checked show config where name like ‘%log.%’
The log.file.max-days parameter on both machines is 0
Why is there log accumulation on only the first machine (approximately 70G of logs generated)?
Check the logs to see what they are. There might have been a network issue or something similar during that time, causing a lot of logs to be generated. If they are not needed, you can manually delete the logs.
It contains some SQL operation information, it should not be a network issue, the logs span from March of this year to the present.
Is your TiDB connection direct or allocated through something like LVS?
That might be because the load balancing wasn’t done properly, and everything is running on one TiDB instance.
It is recommended to add a load balancer on top and allocate based on CPU capacity. Additionally, manually delete those redundant historical files.
It feels like only one TiDB node is working, and the other nodes have no logs at all. This is definitely not right.
It feels like everything is on one host, there might be an issue with load balancing.
Check if it’s a load balancing issue.
What load balancer are you using? It seems like the load balancing has failed.