Note:
Original topic: 逻辑优化未能消除无用排序
For the orders table in the tpch schema, there is the following query:
select max(o_clerk), min(o_clerk) from (select o_clerk from orders order by o_clerk desc) a;
Viewing the execution plan:
mysql> explain select max(o_clerk), min(o_clerk) from (select o_clerk from orders order by o_clerk desc) a;
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
| StreamAgg_8 | 1.00 | root | | funcs:max(tpch1.orders.o_clerk)->Column#10, funcs:min(tpch1.orders.o_clerk)->Column#11 |
| └─Sort_13 | 15000000.00 | root | | tpch1.orders.o_clerk:desc |
| └─TableReader_12 | 15000000.00 | root | | data:TableFullScan_11 |
| └─TableFullScan_11 | 15000000.00 | cop[tikv] | table:orders | keep order:false |
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
It can be seen that a Sort operation is still performed.select max(o_clerk), min(o_clerk) from orders;
mysql> explain select max(o_clerk), min(o_clerk) from orders;
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
| StreamAgg_16 | 1.00 | root | | funcs:max(Column#14)->Column#10, funcs:min(Column#15)->Column#11 |
| └─TableReader_17 | 1.00 | root | | data:StreamAgg_8 |
| └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:max(tpch1.orders.o_clerk)->Column#14, funcs:min(tpch1.orders.o_clerk)->Column#15 |
| └─TableFullScan_15 | 15000000.00 | cop[tikv] | table:orders | keep order:false |
+----------------------------+-------------+-----------+---------------+----------------------------------------------------------------------------------------+
4 rows in set (0.01 sec)
Can this type of issue be optimized and enhanced?
Still not that intelligent
This is a classic subquery. It will definitely prioritize executing the part “select o_clerk from orders order by o_clerk desc” first…
The elimination of invalid associations also needs to be strengthened, as follows:
mysql> show create table customer \G
*************************** 1. row ***************************
Table: customer
Create Table: CREATE TABLE `customer` (
`C_CUSTKEY` bigint(20) NOT NULL,
`C_NAME` varchar(25) NOT NULL,
`C_ADDRESS` varchar(40) NOT NULL,
`C_NATIONKEY` bigint(20) NOT NULL,
`C_PHONE` char(15) NOT NULL,
`C_ACCTBAL` decimal(15,2) NOT NULL,
`C_MKTSEGMENT` char(10) NOT NULL,
`C_COMMENT` varchar(117) NOT NULL,
PRIMARY KEY (`C_CUSTKEY`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)
mysql> show create table nation \G
*************************** 1. row ***************************
Table: nation
Create Table: CREATE TABLE `nation` (
`N_NATIONKEY` bigint(20) NOT NULL,
`N_NAME` char(25) NOT NULL,
`N_REGIONKEY` bigint(20) NOT NULL,
`N_COMMENT` varchar(152) DEFAULT NULL,
PRIMARY KEY (`N_NATIONKEY`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)
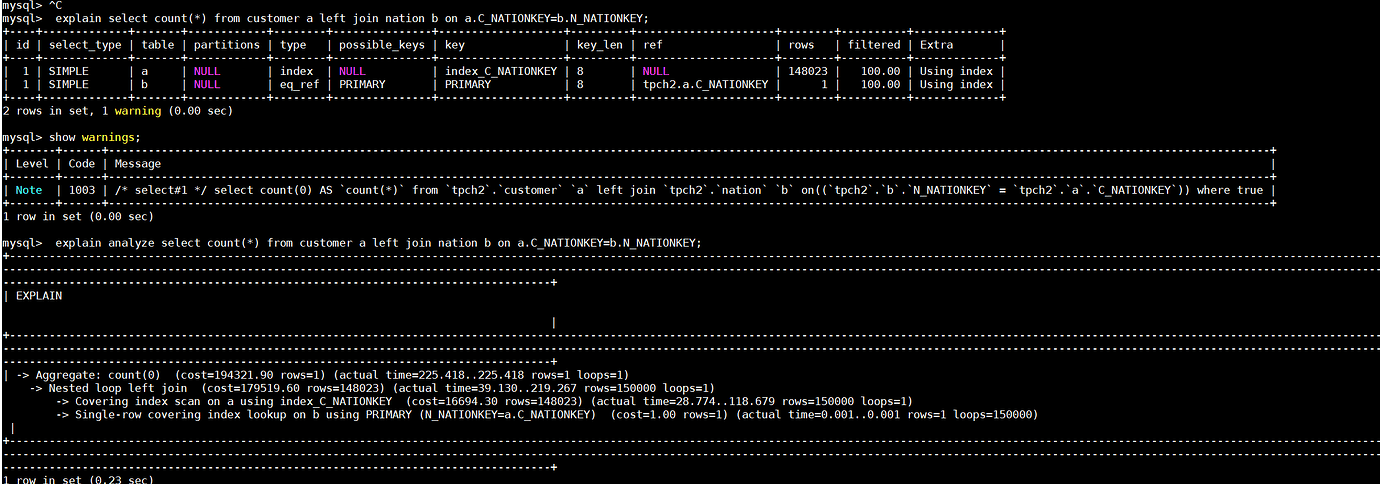
mysql> explain select count(*) from customer a left join nation b on a.C_NATIONKEY=b.N_NATIONKEY;
+-------------------------------+------------+-----------+---------------+---------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------+------------+-----------+---------------+---------------------------------------------------------------------------------+
| HashAgg_8 | 1.00 | root | | funcs:count(1)->Column#13 |
| └─HashJoin_19 | 1500000.00 | root | | left outer join, equal:[eq(tpch.customer.c_nationkey, tpch.nation.n_nationkey)] |
| ├─TableReader_24(Build) | 25.00 | root | | data:TableFullScan_23 |
| │ └─TableFullScan_23 | 25.00 | cop[tikv] | table:b | keep order:false, stats:pseudo |
| └─TableReader_22(Probe) | 1500000.00 | root | | data:TableFullScan_21 |
| └─TableFullScan_21 | 1500000.00 | cop[tikv] | table:a | keep order:false |
+-------------------------------+------------+-----------+---------------+---------------------------------------------------------------------------------+
6 rows in set (0.00 sec)
In fact, since the N_NATIONKEY of the nation table is the primary key, it should directly use the primary key of the customer for the count. I hope this can also be optimized at the logical optimization level to eliminate the association.
MySQL automatically rewrote it.
This statement was not successfully rewritten by MySQL either.
If someone else can do it, we can’t fall behind.
Fixed after version 7.2, related ISSUES:
opened 03:56AM - 25 May 23 UTC
closed 03:31AM - 26 May 23 UTC
type/enhancement
## Enhancement
Change the default value `tidb_remove_orderby_in_subquery` to … true.
It will not change the behaviors of upgrade cluster.
It just change the behaviors of new cluster after v7.2
## Example
1. create table
```
CREATE TABLE `t1` ( `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL);
```
2. explain query
**without order by plan node**
```
"TableReader 10000.00 root data:TableFullScan",
"└─TableFullScan 10000.00 cop[tikv] table:t1 keep order:false, stats:pseudo"
```
opened 05:53AM - 28 Sep 23 UTC
closed 04:42AM - 12 Oct 23 UTC
type/bug
sig/planner
severity/major
may-affects-5.3
may-affects-5.4
may-affects-6.1
may-affects-6.5
may-affects-7.1
## Bug Report
Please answer these questions before submitting your issue. Tha… nks!
### 1. Minimal reproduce step (Required)
A bug exists in TiDB v7.3 where the ORDER BY clause in a subquery is ignored in the overall query results. For example:
```sql
SELECT * FROM (
SELECT ep.exam_project_id, ep.create_time
FROM exam_project ep
ORDER BY create_time DESC
) aa
```
In this example, the subquery correctly orders the results by the create_time field in descending order. However, when used in the overall query, the ordering is lost and the results are not sorted by create_time.
The subquery order by is expected to affect the overall result order, but is incorrectly ignored. This results in incorrect query results compared to what is expected.


### 2. What did you expect to see? (Required)
The subquery order by is expected to affect the overall result order.
### 3. What did you see instead (Required)
However, when used in the overall query, the ordering is lost and the results are not sorted by create_time.
### 4. What is your TiDB version? (Required)
Release Version: v7.3.0
Edition: Community
Git Commit Hash: 40b72e7a9a4fc9670d4c5d974dd503a3c6097471
Git Branch: heads/refs/tags/v7.3.0
UTC Build Time: 2023-08-08 10:08:14
GoVersion: go1.20.7
Race Enabled: false
Check Table Before Drop: false
Store: tikv
Try upgrading to the latest 7.5.1 LTS version.
You can only write the subquery yourself;
Quickly optimize the minor version, this shouldn’t be difficult.