Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 网络故障集体迁移IP故障恢复过程
【TiDB Usage Environment】Test Environment
【TiDB Version】5.4.1
-
Fault Description:
In the test station, 4 virtual machines were used. Today, due to a network failure, there was a forced power outage, causing a collective crash. Two TIKV node virtual machines were directly scrapped and could not be started.
There was no backup in the test environment, so we had to recover the test data with difficulty. -
Original Virtual Machine Node Distribution
192.168.1.110 tidb-server, ti-pd Crashed and cannot start
192.168.1.111 tipd, monitoring, ti-pd Normal
192.168.1.112 tikv Crashed and cannot start
192.168.1.113 tikv Normal -
Recovery Process
-
First, rebuild the virtual machine to ensure the node server can start normally.
-
During the recovery process, it was found that due to the network failure, all node IPs were changed to the 10.1.1.0 segment, causing all tidb nodes to be in a crash state. Attempts to manually change the IP (modifying the tikv startup configuration file, modifying the tiup’s meta.yaml, etc.) resulted in abnormal startup and were not feasible. Attempts to recover through scaling failed.
-
Finally, decisively rebuilt a clean environment and started a new cluster.
-
After starting the cluster, mounted the data to be recovered tikv-20160, backed up the original (since the data was too large, 20GB, I directly mounted the cloud disk).
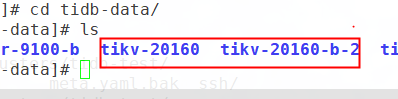
-
Expanded a TIKV, restarted the cluster, PD was in UP state, TIKV was in Disconnected state, found tikv error cluster ID mismatch.
-
Finally, due to the cluster ID mismatch, searched the documentation PD Recover 使用文档 | PingCAP 文档中心 to find the old cluster’s cluster ID and alloc-id.
-
Then attempted recovery in the new cluster’s PD Leader, found that the recovery was successful.
-
Then restarted the cluster, tiup cluster restart tidb-test, checked the tikv log, tikv started normally. The newly expanded node did not start for some reason, possibly due to empty data. Ignored it for now.
-
The test database connection was normal, data could be queried and inserted, so the test database was considered recovered.



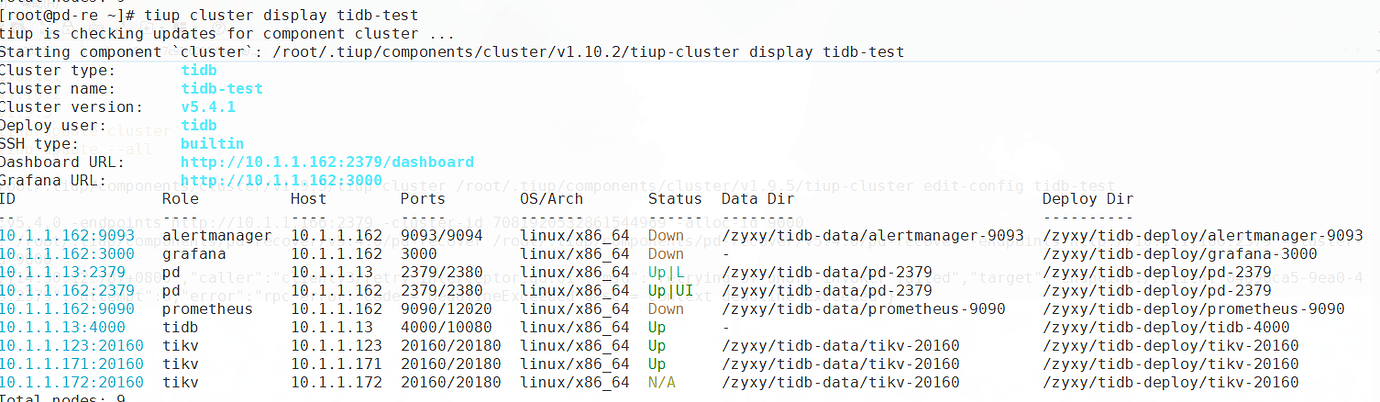
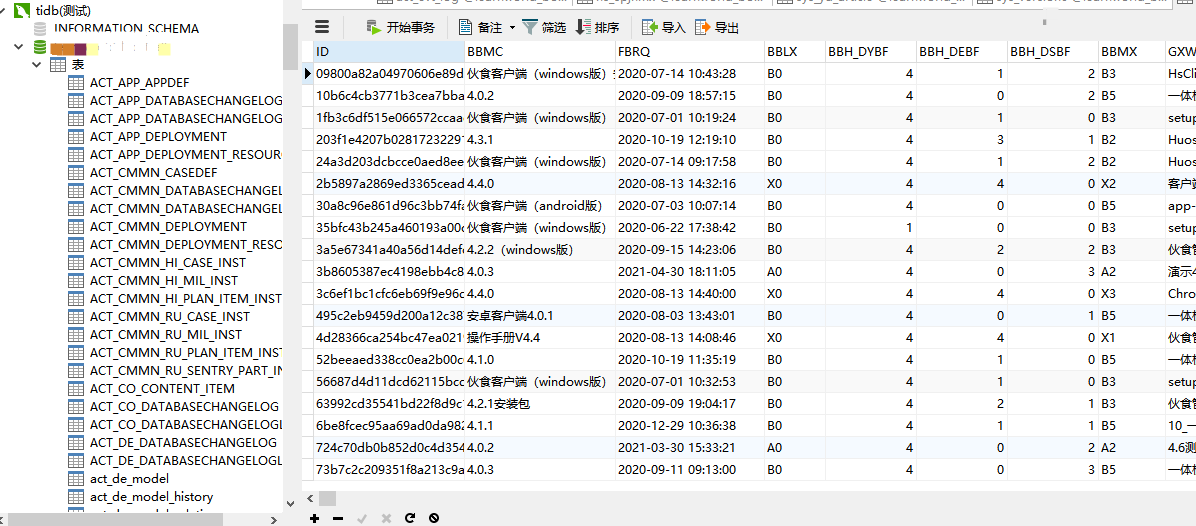
- Summary
I am still not familiar enough with some in-depth knowledge points of TiDB. Additionally, this data recovery was done in a test environment, and it is unclear if there are any hidden risks. For reference only, always back up before recovering data.