Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 加节点测试
[TiDB Usage Environment] Poc
[TiDB Version] v7.5.0
Current cluster information is as follows:
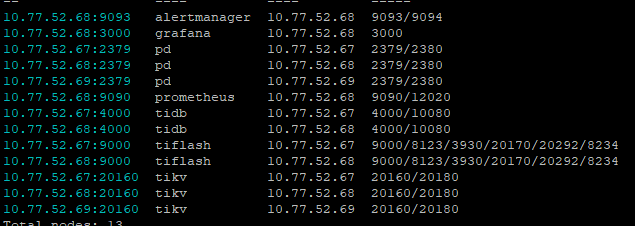
Hardware configuration:
Three virtual machines, 32C 64G 500G shared storage (mixed SSD and HDD)
Requirement:
Now I want to test the write capability of TiDB after adding nodes. Plan to add 4 more nodes (4 virtual machines with the same configuration).
Question: Does the entire cluster configuration need to be readjusted? Should all 4 nodes be given to TiKV? How should TiKV expansion be performed?
Generally, the bottleneck is with the KV nodes, you can provide KV
If all storage is shared physical hard drives for all TiKV nodes, then adding more nodes is meaningless.
You can add 1-2 machines first to see the effect.
You can add the required roles to your cluster using the tiup tool.
The storage of each TiKV node is isolated and shared with other virtual machines.
If the configuration file is already set up, you can use just two commands:
tiup cluster check tidb-scale-out.yaml --cluster --user root -p
tiup cluster scale-out tidb-scale-out.yaml --user root -p
Do the environments of the two newly added virtual machines need to be configured? For example, SSH passwordless configuration.
If you are testing writes, just add TiKV. Additionally, plan the table structure to distribute it as evenly as possible across TiKV nodes.
Okay, first apply for 2 machines to expand as KV nodes and see the effect. The table has enabled region uniform distribution.
Can a single machine add nodes for testing?
Sure, just change the port number in the deployment template to avoid conflicts.
It is recommended to configure the POC testing environment according to the production environment configuration requirements, so as to test the real performance. Reference: TiDB 软件和硬件环境建议配置 | PingCAP 文档中心
We couldn’t meet the official recommended requirements. We are all using virtual machines, so we will add more nodes later to share the pressure.
Additionally, you need to use labels to adjust the data position, and the IO capability of shared storage is shared. Once the IO capability reaches its peak, adding more becomes meaningless.
You can directly write the template and then expand it.