Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Talent Plan TinyKV Project 2 笔记
Project 2 RaftKV
Part A Raft
AppendEntries RPC Interaction
When a follower receives an AppendEntries request, it will determine log consistency based on prevLogIndex and prevLogTerm. Specifically, one of the following three situations may occur:
- Index Conflict: The follower does not have a log entry with index prevLogIndex.
- Term Conflict: The follower has a log entry with index prevLogIndex, but its term does not match prevLogTerm.
- Accept: The follower has a log entry with both index and term matching prevLogIndex and prevLogTerm.
In my implementation, the follower sets the Reason, NextIndex, and ConflictTerm fields in the AppendEntries response based on different situations:
- Reason is set only when the AppendEntries request is rejected, with values corresponding to Index Conflict and Term Conflict, informing the leader of the reason for the rejection.
- NextIndex is set both when rejected and accepted, suggesting to the leader: please send me the log entry starting from NextIndex next time.
- ConflictTerm is set only in the case of Term Conflict, with its value being the term of the entry at prevLogIndex in the follower, which caused the Term Conflict due to its inconsistency with prevLogTerm.
For Index Conflict, NextIndex is set to last log index + 1, which is obvious.
For Term Conflict, starting from prevLogIndex, the follower searches backward in its log for the first log entry with term equal to ConflictTerm. Initially, NextIndex is set to prevLogIndex. During the search, NextIndex is decremented gradually. When such a log entry is found or the search reaches commit index + 1, the search stops. The value of NextIndex at this point is what the follower will send to the leader.
When the leader receives the AppendEntries response, it first determines whether it was rejected and the reason for the rejection based on the Reject and Reason fields. For Index Conflict, the leader can only accept the follower’s suggestion, using the NextIndex set by the follower for the next send. For Term Conflict, the leader first searches forward in its log for a log entry with term equal to ConflictTerm. If such a log entry is found, it continues searching until it finds the first log entry with a term not equal to ConflictTerm, setting NextIndex to the index of that log entry; if not found, it accepts the follower’s suggestion.
Questions remaining about this part include:
- The logic here is based on the MIT 6.824 Students’ Guide to Raft. I can understand the search on the follower side, but I cannot understand the search on the leader side.
- When sending log entries, the type of entries in the RPC Message is
[]*pb.Entry. What is the semantics of sending pointers in RPC? How does the receiving end of RPC reconstruct the pointer mapping? In etcd, the type of entries is[]pb.Entry. Why does tinykv choose a different type from etcd? - When sending log entries, the type of entries is a slice of
*pb.Entry, and in Go, a slice is a reference to an array. What is the semantics of sending references in RPC? How does the receiving end of RPC re-establish the reference relationship?
Part B Fault-Tolerant Key-Value Server On Top Of Raft
How tinykv handles a write request
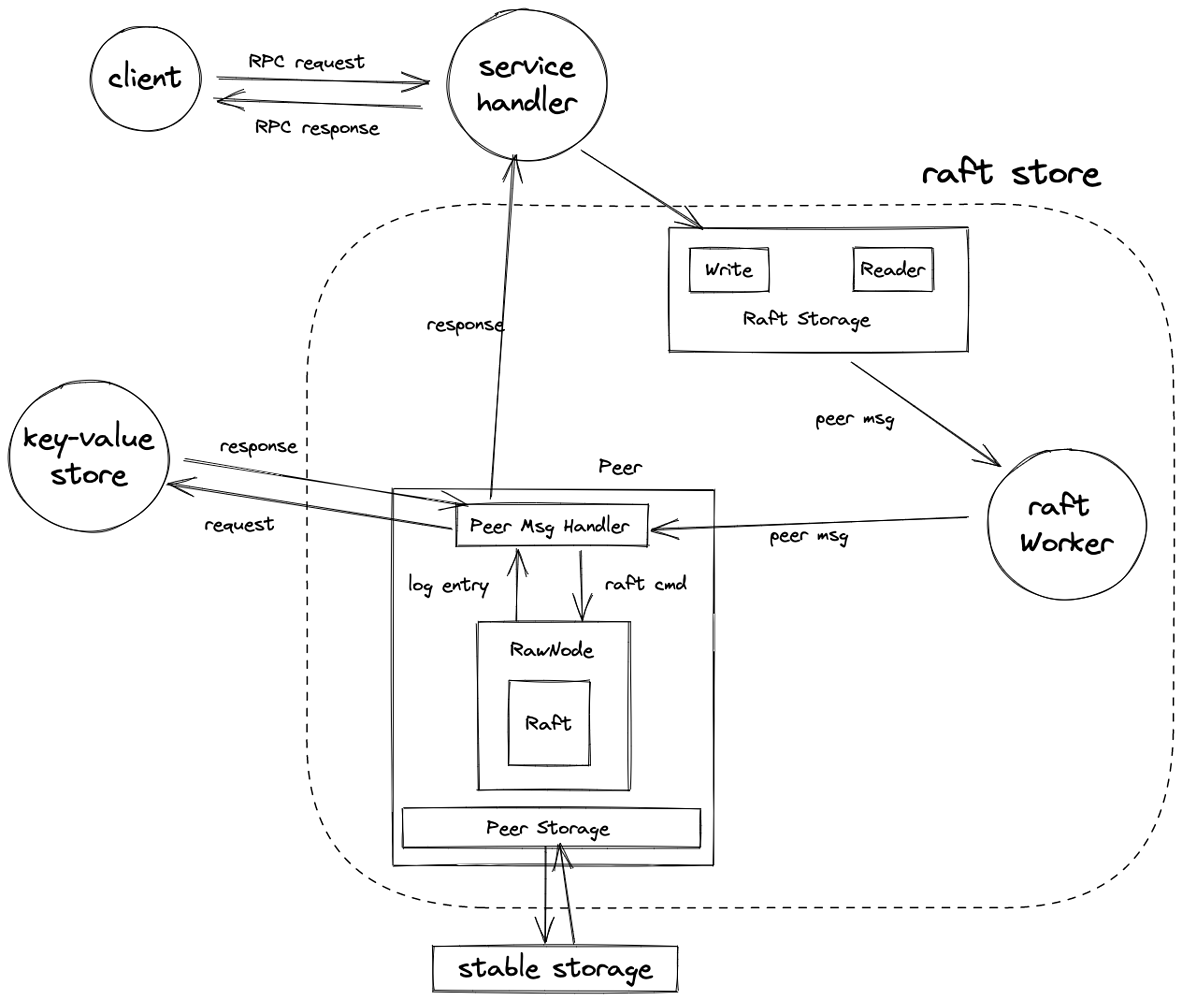
- The service handler captures the write request and interacts with the raft storage layer, calling its exposed
Writeinterface. - The raft storage packs the write request into a raft cmd, which is then wrapped into a peer msg by the router and delivered to the raft store.
- A store (i.e., tinykv server) uses a raft store to complete various tasks related to raft. The raft store contains a router and various workers, each performing its duties. Since a store contains multiple peers responsible for different regions, the router needs to find the corresponding peer based on the region id. The region id is part of the context provided by the client when sending the request.
- The raft worker in the raft store receives the peer msg passed by the router and calls the corresponding peer’s msg handler to process it.
- The peer msg handler determines that the peer msg type is a raft cmd msg, extracts the raft cmd from it, marshals it, and proposes it to the raw node in the form of byte.
- The raw node is responsible for the interaction between the raft worker and the raft module. For each received proposal, the raw node packs it into a log entry and submits it to the raft module.
- After the raft module commits this log entry, the raw node delivers it to the raft worker.
- The raft worker calls the corresponding peer’s
HandleRaftReady, unmarshals the raft cmd from the log entry, extracts the write request from it, inputs it into the state machine module (i.e., the underlying key-value store), and gets the response to the write request. - The response is returned to the service handler through a pre-set callback channel. At this point, the handling of a write request is complete.
- Throughout the process, tasks that need to interact with stable storage, such as persisting log entries, persisting raft state, restoring state, etc., are handled by peer storage.
Points worth mentioning
About Append in peer_storage.go
The comment for this function in tinykv is delete log entries that will never be committed. To understand this, we need to understand tinykv’s logic for log entry persistence.
In tinykv, when a new log entry is appended to the log, the upper layer immediately captures this information and calls the HandleRaftReady function to persist the newly appended log entry. This means that even uncommitted log entries will be persisted.
Since not all log entries will eventually be committed, these log entries need to be discarded in a timely manner (although they can also be retained, but they become garbage data). So when is “timely”? Consider the persistence of a new log entry:
- If an already persisted log entry is identical to it, you can choose to delete the old one and persist the new one, or keep the old one and abandon the persistence of the new one.
- If an already persisted uncommitted log entry conflicts with it, i.e., the index is the same but the term is different, then:
- If the new one will eventually be committed, naturally delete the old one and persist the new one.
- If the old one will eventually be committed, you can choose to keep the old one and abandon the persistence of the new one, or delete the old one and persist the new one. This is because the new log entry will not be committed (our assumption), so it will eventually be replaced by the old log entry at some point.
- If there is no old log entry with the same index as the new log entry in stable storage, directly persist the new one.
Note that the index of the new log entry must be greater than the commit index because unstable entries are determined based on stabled index + 1, and there is an invariant commit index ≤ stabled index. Therefore, the situation of replacing committed log entries will never happen.
In summary, as long as there is a new log entry that needs to be persisted, we delete the old log entry with the same index (if it exists) and then persist the new one. This logic translates to code implementation as: for each new log entry, use the Set operation to replace the old log entry with the same index (if it exists), thus resolving the conflict. For all old log entries with indexes after the last new entry’s index (if any), delete them.
About WriteBatch and crash consistency
In SaveReadyState, a write batch is used to record all write operations, which are then wrapped into a txn and written to badger DB.
Txn gives us a guarantee of crash consistency. First, let’s explain what crash consistency is. For a series of quantities with constraints between them, if these constraints are correct before the crash, they should also be correct after recovery.
For example, there is an invariant applied index ≤ commit index. Suppose a non-stale snapshot has just been installed, then both applied index and commit index should be updated to snapshot index. Now suppose our code first updates the applied index and then updates the commit index. If there is no guarantee of crash consistency from txn, and the machine crashes after updating and persisting the applied index but before updating and persisting the commit index, then after recovery, there will be applied index > commit index, violating the invariant constraint, and consistency is broken.
Therefore, when writing code related to persistence, for quantities with constraints between them, a write batch must be used. And always consider “if the code crashes here, what problems might occur? Will it break consistency?”
About executing raft cmd
HandleRaftReady extracts raft cmd from each committed log entry and executes them. Note the following points:
- For no-op entries, their data is empty, so no raft cmd can be extracted, and there is no need to execute them. However, they still affect the applied index, so special handling is required.
- Each server needs to execute raft cmd, but in my implementation, only the leader stores the proposal. Therefore, the behavior after executing raft cmd needs to be distinguished between the leader and non-leader.
- For snap requests, a new txn needs to be started. Note that snap requests correspond to the
Readerinterface of the Storage layer, which returns a snapshot of the key-value store for reading. Since it is a snapshot, it needs to be placed in a txn to use the isolation feature provided by txn. This txn is then closed by the service handler after the read operation is completed. Another point to note is that this txn is bound to the raft cmd (which may contain many requests), not to a single snap request. In fact, a raft cmd corresponding to aReadercall will only contain one snap request, so txn can be bound to the raft cmd.
Regarding commit and apply, there are several scenarios worth noting:
- If a log entry is committed, it will eventually be committed by all servers. Consider a log entry that is committed, and the old leader crashes or is partitioned. The newly elected leader must be a server that has already appended this log entry. This is determined by raft’s Leader Completeness Safety. In other words, the leaders of two adjacent terms must be in the same majority in the previous term. When the new leader calls
becomeLeader, it appends a no-op entry and tries to commit it. If this no-op entry is committed, all previous log entries (including those committed by the previous leader) will also be committed. - If a client sends a sequence of Put and Get operations for the same key to the cluster, raft ensures that the Get operation can get the expected, correct result. This is guaranteed by linearizability. Suppose after applying the Put operation and replying to the client, the old leader crashes. According to the previous point, this Put operation will definitely be committed and eventually applied by all servers. Even if the new leader receives the Get request before applying the Put operation, since log entries are executed sequentially, the Put operation must have been executed when applying the Get request.
- If the old leader crashes after applying a request but before replying to the client, the client may resend the same request, causing raft to apply the same request twice. If this request is a Delete operation for a key, such behavior is obviously incorrect. The solution given by the raft paper is: the client maintains an incrementing counter and attaches the current value of this counter when sending requests. The server maintains and persists the value of the counter attached to the last request, determining whether the current request has been processed. If it has, the server can choose to ignore the request (if it is a write request) or reply again (if it is a read request). Note that only the counter value of the last request needs to be maintained because the resent request must be adjacent to the last repeated request (in terms of counter value).
- For committed log entries, each server can execute them independently, but only the leader is responsible for replying to the client. However, the old leader may reply to the client because it is partitioned, causing a new leader to be elected in the cluster. The old leader is unaware of the new leader’s existence and replies to the client; the new leader also replies to the client according to its responsibility. If it is a Get request, the values obtained from the two replies may be inconsistent, which is obviously incorrect. The raft authors provide two solutions in the paper and code (LogCabin):
- Before replying to the Get request, let the old leader step down through a round of heartbeat interaction.
- Design a step-down thread that checks the last communication time with each peer on the leader every tick (updating this time during each RPC interaction). If the last communication time with the majority of peers exceeds an election timeout, let the leader step down.
Questions remaining about this part include:
If it is a Get request, the values obtained from the two replies may be inconsistent. Does this situation really occur? Since raft executes log entries sequentially, different leaders executing the same Get request must have executed previous write requests in the same order, so the state machine’s state must be consistent when executing this Get request. Why does the raft paper say it may be inconsistent?- After executing the raft cmd, the corresponding proposal needs to be found. If a stale proposal is found during this process, inform the client that the proposal has expired; if a proposal with the same index and term as the current log entry is found, reply to the client. For stale proposals, my understanding is: if the proposal’s index is less than the log entry’s index, or the proposal’s term is less than the log entry’s term, consider the proposal stale. Is this judgment correct? On the other hand, how should other cases of index and term be handled?
Log Compaction & Snapshotting
Log Compaction
Every tick, the leader compares the applied index with the storage first index to check if it exceeds a preset threshold. If it does, it sends a CompactLogRequest to the raft layer, which is captured by the raft worker after being committed. The raft worker notifies the raftLogGCTaskHandler to asynchronously perform log compaction. Meanwhile, the truncated state and other states are immediately updated and persisted.
Questions remaining about this part include:
- Why does log compaction need to wait for the raft layer to commit before doing it, instead of being done independently by a single machine?
- If the machine crashes during the persistence of the truncated state, but the asynchronously executed gc task has been successfully executed and persisted before this, then during recovery, the obtained truncated state is actually stale. Does tinykv have this problem?
Log Replication and Snapshotting
A typical scenario is: when a new node is added to the cluster, after a round of heartbeat interaction, the leader finds that the node’s state lags behind its own state, so it tries to send the missing logs to the node. Due to log compaction, these logs may have been partially or completely discarded, so the leader abandons sending the logs and sends a snapshot instead. (In fact, whether to send a snapshot is determined by whether prevLogTerm can be obtained)
Why can a snapshot replace these missing logs? This requires us to understand the typical structure of a fault-tolerant server composed of raft + log replicated state machine. Such a server usually contains a raft module and a state machine module. When a client request reaches the server, it is first converted into a raft cmd, then marshaled and packed into a log entry, which is replicated by the raft module. After the raft module commits this log entry, the raft cmd is unmarshaled from it, the request is parsed from it, and finally input into the state machine module. After executing the request, the state machine’s state is updated (if it is a write request). The state of the state machine is what the fault-tolerant server truly cares about. In a fault-tolerant key-value server, the state machine is the underlying key-value store, and its state is composed of all its key-value pairs.
When a cluster is running normally, different nodes achieve state machine state consistency by executing a series of identical log entries in the same order. However, in the “typical scenario” mentioned above, due to the missing log entries, the newly added node cannot achieve synchronization by executing log entries. But note that our only goal is state machine state consistency, so the leader writes its state machine state into a snapshot and sends it to the newly added node; the newly added node installs this snapshot, directly updating the state machine’s state and skipping the step of executing log entries.
In summary, log replication and snapshotting are two different means of synchronizing the state machine state on different servers. A log entry usually involves access to a limited number of key-value pairs, while a snapshot, being a snapshot of the current state machine state, contains many key-value pairs, occupying a lot of network bandwidth when sent and a lot of I/O resources when generated and installed. Therefore, log replication is usually used for state machine state synchronization, and snapshotting is only used when necessary.
Sending and Receiving Snapshot Process
- When about to send logs to a follower, the leader finds that it cannot obtain the prevLogTerm corresponding to prevLogIndex - 1 by comparing prevLogIndex - 1 with lastIncludedIndex. Therefore, it tries to send a snapshot instead.
- By calling the Snapshot interface of the storage layer (the Snapshot interface of peer storage), raft notifies the storage layer to start generating a snapshot. During the generation, calls to the Snapshot interface will return a specific error, informing the raft layer.
- A snapshot is essentially a file, and each snapshot file corresponds to a unique snap key. The snap key is composed of region id, snapshot index, and snapshot term, so it can uniquely specify a file path. During the generation of the snapshot, the state machine’s state is gradually written into this snapshot file. (In fact, a snapshot corresponds to multiple files, but this is simplified for explanation)
- After successfully generating a snapshot, the leader captures the snapshot returned by the Snapshot interface in the raft layer, packs it into a raft msg, and prepares to send it to the corresponding follower.
- The peer msg handler captures the raft msg to be sent in the
HandleRaftReadyfunction and delivers it to the transport. In the final stage of preparation for sending, there is aWriteDatafunction, which behaves as follows:- If the raft msg does not contain a snapshot, it is delivered to
RaftClient.Sendfor sending; - If the raft msg contains a snapshot, it is intercepted by the
SendSnapshotSockfunction, which schedules asendSnapTaskto asynchronously send the snapshot.
- If the raft msg does not contain a snapshot, it is delivered to
- The task of sending the snapshot is completed by the
snapRunner.sendSnapfunction. This function first creates a tiny client, then uses it as a proxy to establish a streaming long connection with the tinykv server where the follower is located and initiates a Snapshot request. The snapshot is divided into snapshot metadata