Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Offline的Store节点无法下线
[TiDB Usage Environment] Production Environment
[TiDB Version]
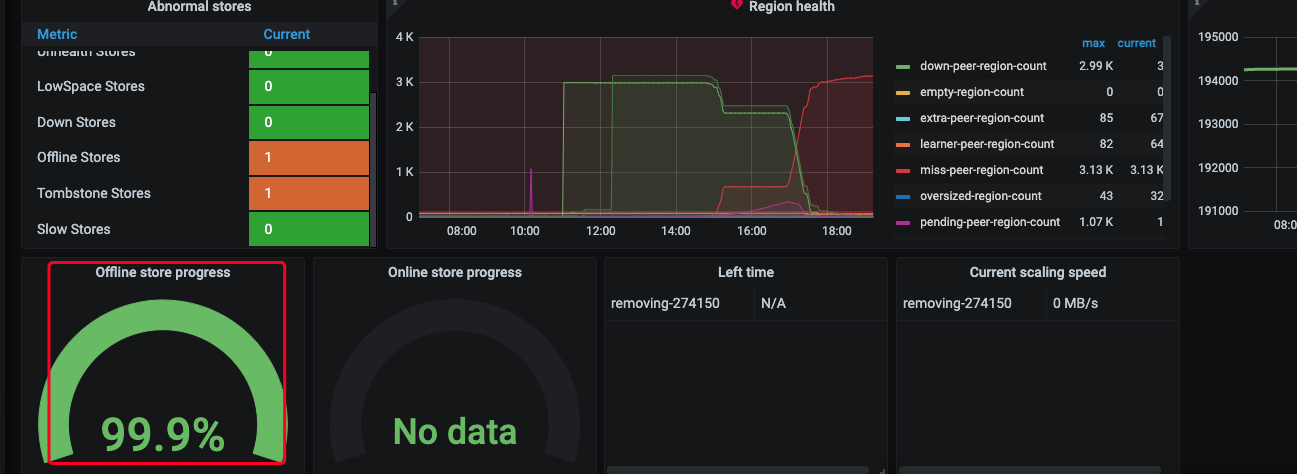
[Reproduction Path] After the machine went offline, the Store became Offline. Using pd-ctl operator add remove-peer to delete all peers on the store, three peers could not be deleted and were stuck at “cannot build operator for region which is in joint state.” This caused the statefulset pod to be unable to rejoin the cluster.
[Encountered Problem: Symptoms and Impact]
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]
The offline progress is stuck at 99.99%