[Encountered Problem]
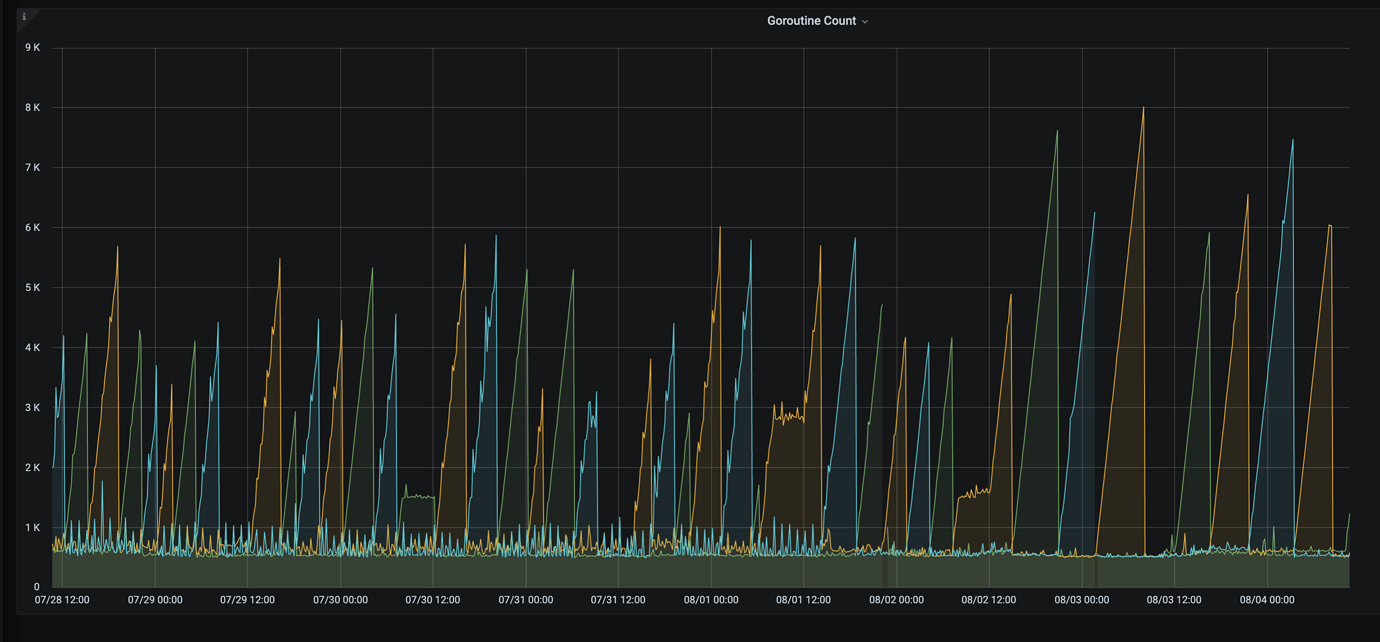
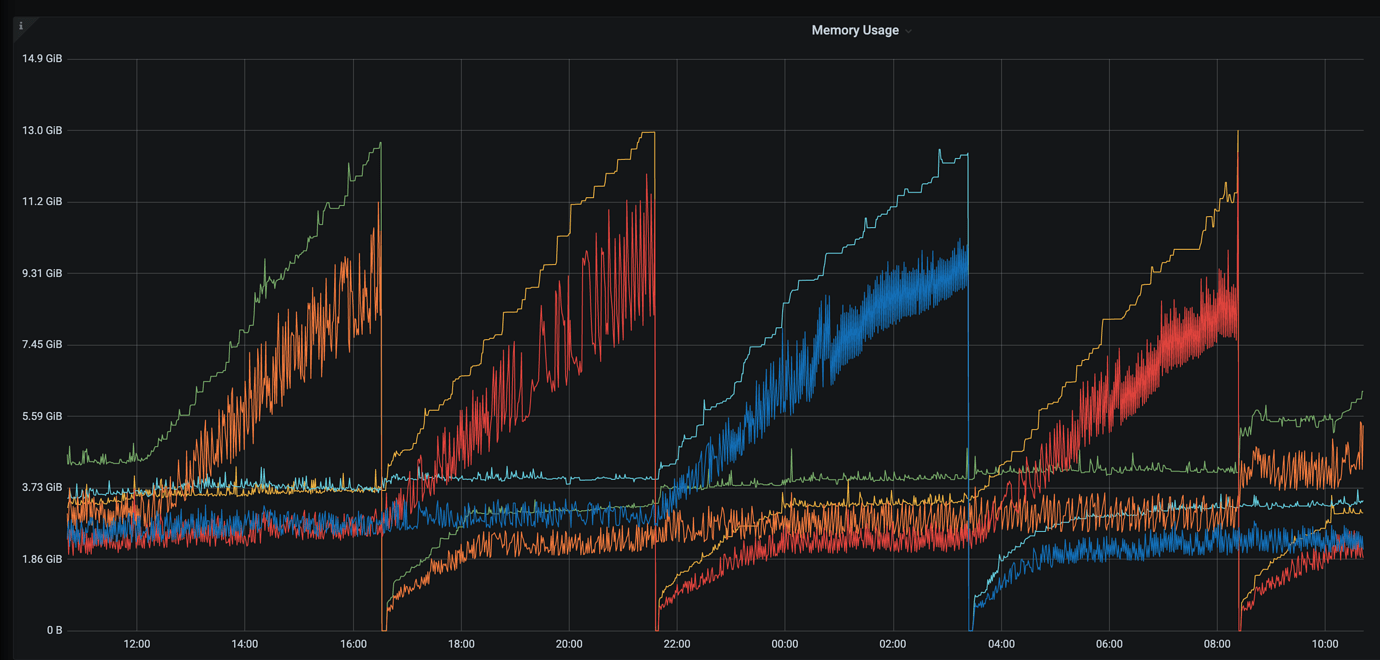
Goroutine leak, the number of goroutines will surge, and when it reaches a certain level, it will cause an OOM restart. This situation will repeatedly occur.
There are batch insert/update operations with a QPS of around 2k-3k. Can we only reduce concurrent processing? I checked the logs, and the mem_max in the Top 10 SQL is around 60-70k. I’ll check the other nodes.
There is no need to reduce concurrency. It doesn’t seem to be the issue. If the transaction is large, you can break it down into smaller ones, essentially splitting a long transaction into many small transactions, if the business logic allows it.
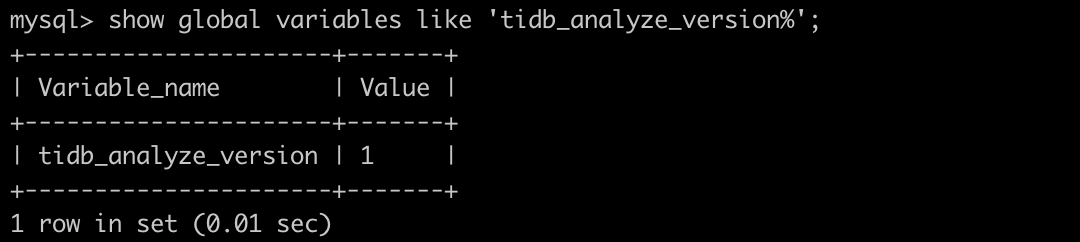
Also, does the cluster have a defined auto Analyze feature?
There is an Auto Analyze feature, but it keeps reporting errors. The error messages are similar to the following:
[2022/08/03 08:31:27.862 +00:00] [ERROR] [update.go:1085] [“[stats] auto analyze failed”] [sql=“analyze table %n.%nindex %n”] [cost_time=4.24714ms] [error=“other error: invalid data type: Failed to decode row v2 data as u64”]
I suggest turning off the Auto Analyze feature first, as it can affect both read and write operations.
After turning it off, you can check the health of the tables. For tables with poor health, you can manually analyze them during non-peak business hours.
invalid data type: Failed to decode row v2 data as u64
This error seems to be a decoding issue… It’s a bit strange.
It seems like this is the issue. I’ll go ahead and submit a feature request. The reproduction path is to change the data type of a column in an existing table, where that column previously had an index. The data type of that column in the table was changed, but the index was not updated. As a result, auto analyze keeps reporting data type conversion errors.
The feature request is to automatically update the data type of the index when modifying the column.
I tried to reproduce it on a MacBook but was not successful. Manually executing analyze table also did not result in the type error that appeared in the production environment.
tiup playground v5.2.1 --db 2 --pd 3 --kv 3
At that time, it was changed from varchar(256) null to bigint unsigned null.
Is it possible that there was an issue during the change process (such as a lost connection), causing the schema of the index file to have two different versions?
Changing the data type of a column is not done using transactions. Modifying the field type takes too long, and there might be issues midway, resulting in incomplete changes.