Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: sqoop导出数据过程中tikv优化问题
[TiDB Usage Environment] Production Environment
[TiDB Version] 5.7.25-TiDB-v4.0.9
[Reproduction Path] Sqoop data to TiDB
[Encountered Problem: Problem Phenomenon and Impact]
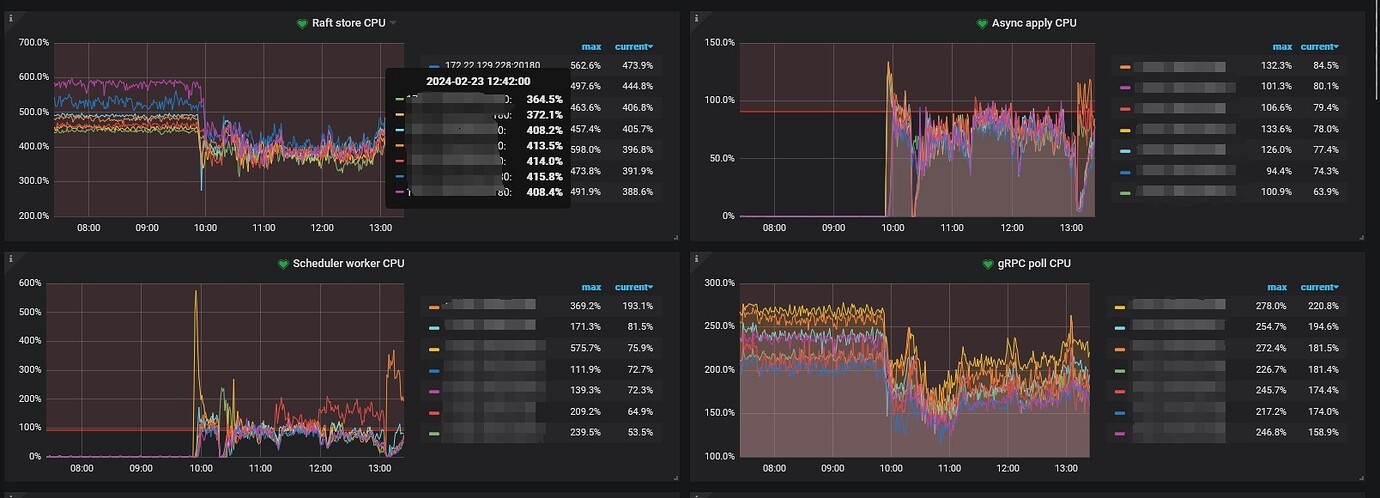
After starting the Sqoop task, the overall system CPU usage is at 50%, but according to the TiKV thread CPU monitoring, both raft store CPU and grpc poll CPU decrease. What is causing this? Or what configuration needs to be adjusted?
My understanding is that with sufficient system resources, raft store CPU and grpc poll CPU should not be affected.
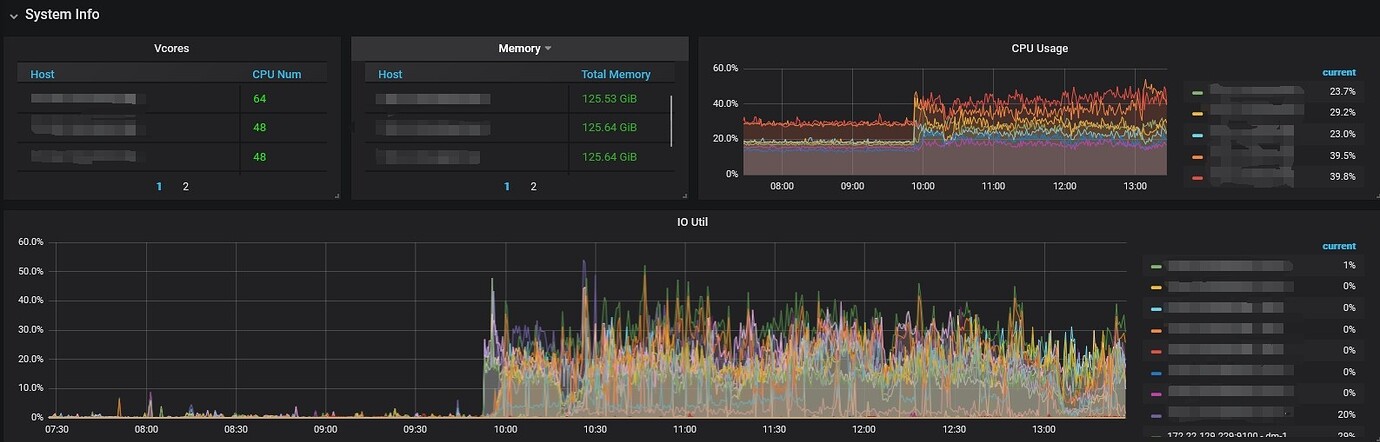
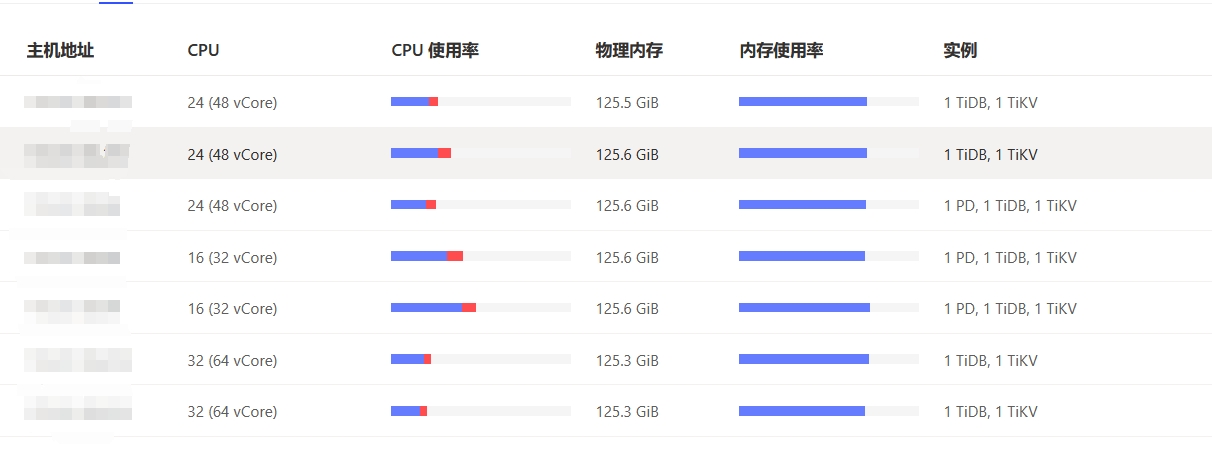
[Resource Configuration] Enter TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
Isn’t it good that the CPU usage has decreased?
I don’t quite understand. The current setting for raftstore.store-pool-size is 8. When nothing is being done, the raft store CPU is between 500% and 600%, and the Async apply CPU is close to 0. When starting a sqoop task, the Async apply CPU rises, but the raft store CPU decreases. This makes me feel like TiKV has set an overall resource usage limit and is not fully utilizing the server’s performance.
Version 409? Recommended upgrade 
Upgraded, the charts all seem to match.
The problem background and description are not very intuitive, but I’ll try to answer your question:
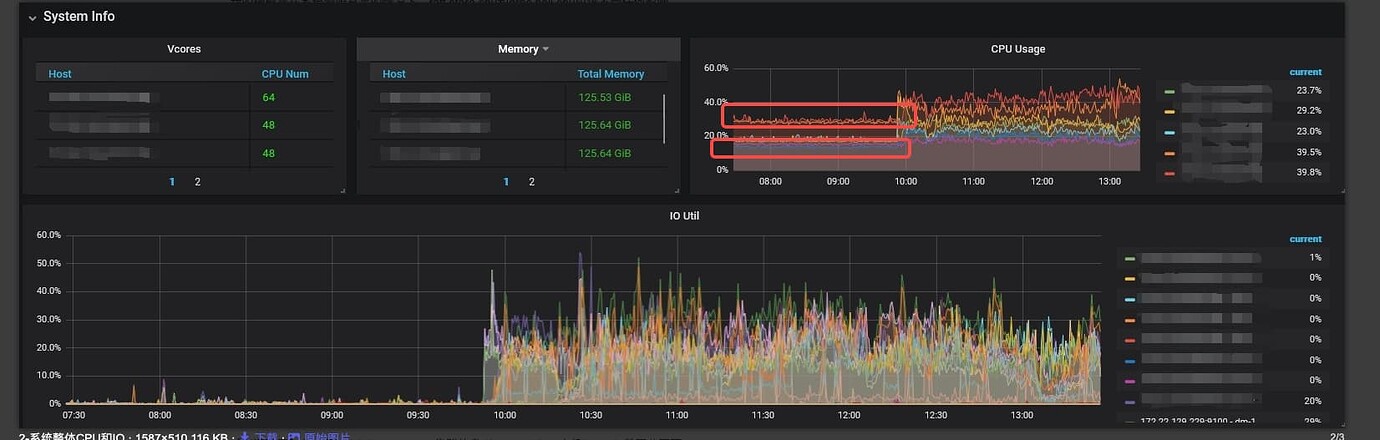
- From the dashboard, it looks like you have a mixed deployment. I’m not sure if you have set memory and CPU limits. If not, please set the limits.
- Although it is a mixed deployment, it is obvious that your CPU is unbalanced: 3 with 48 cores + 2 with 32 cores + 2 with 64 cores. This is problematic because of the barrel effect. If you have set resource limits, each physical machine will be affected by the 32-core bottleneck.
- I assume you started the Sqoop around 10 o’clock. From the graph, you can see that there was CPU usage before 10 o’clock, indicating two layers of load.
This suggests that there was already business pressure before, possibly from business A.
- Before 10 o’clock, you had raft store CPU and grpc CPU but no schedule CPU, indicating no writes. I’m not sure about your business model.
- Interestingly, after 10 o’clock, your Sqoop task should have started. At this time, you can see an increase in schedule CPU, but it was not very balanced initially. There were imbalances at 10:30 and 13:00, indicating write hotspots. You can look into materials on write hotspots for optimization.
Your current issue, as I understand it, is why the overall CPU usage has decreased, but the raft CPU and grpc CPU have also decreased. I think it might be because the Sqoop business started and occupied some resources, such as disk IO, your application server, or your network resources. This affected your previous business, causing the pressure from business A to decrease, leading to a drop in grpc CPU and raft CPU usage. 
For some issues, restarting and upgrading are the fastest solutions.