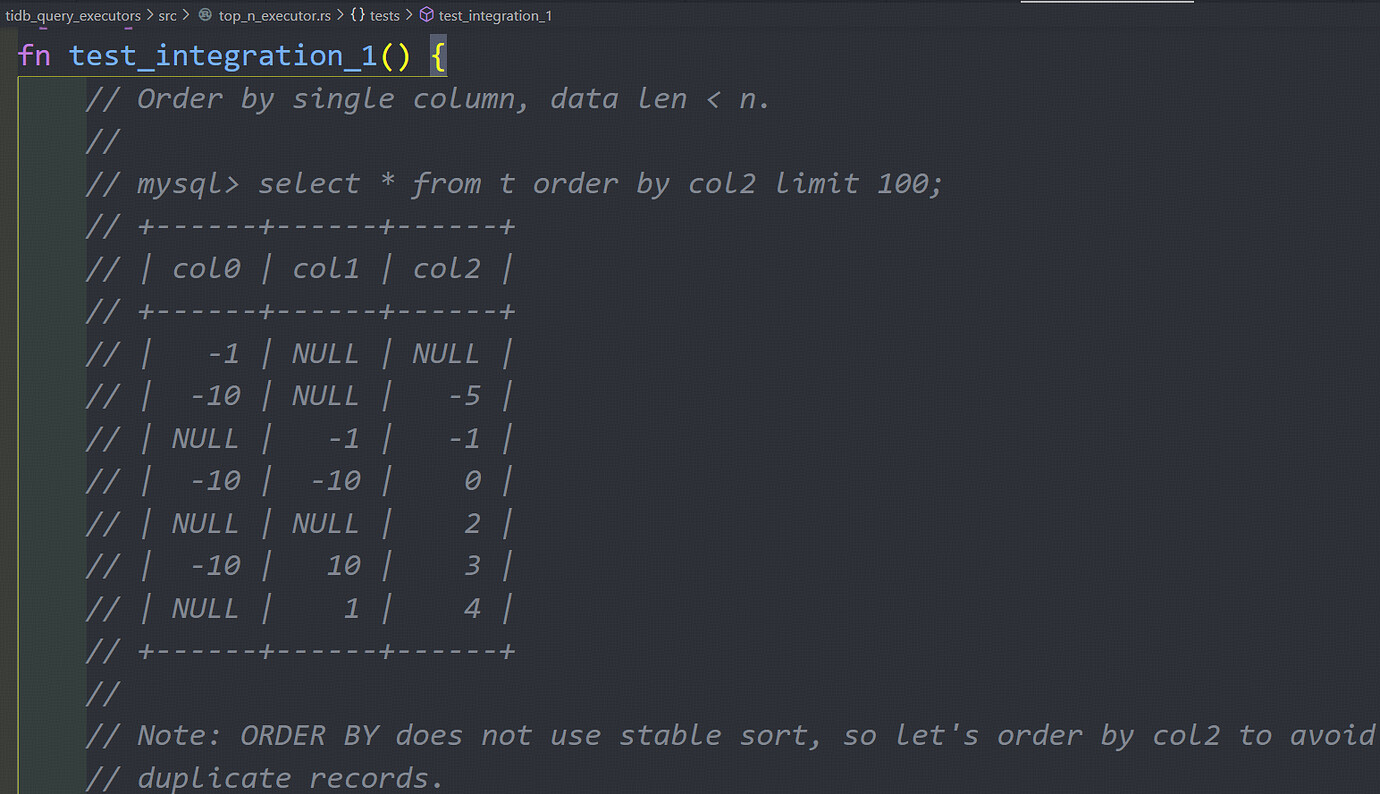
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: order by + limit分页查询结果数据重复不符合预期
【TiDB Usage Environment】Production Environment / Testing / Poc
【TiDB Version】5.7.25-TiDB-v7.5.0, 8.0.11-TiDB-v7.5.0
【Reproduction Path】Operations performed that led to the issue
Created a test table and inserted data
CREATE TABLE test(idbigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',create_timedatetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT 'Record creation timestamp',update_timedatetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT 'Record update timestamp',task_idbigint(20) unsigned NOT NULL DEFAULT '0' COMMENT 'Task ID',user_idbigint(20) unsigned NOT NULL DEFAULT '0' COMMENT 'C-end user ID',statustinyint(2) unsigned NOT NULL DEFAULT '0' COMMENT 'Task status 0: unknown, 1: pending push, 2: push completed, 3: push failed, 4: canceled',reason varchar(64) NOT NULL DEFAULT '' COMMENT 'Failure reason', PRIMARY KEY (id) /*T![clustered_index] CLUSTERED */, KEY idx_task (task_id), KEY idx_status (status), UNIQUE KEY uk_task_user (task_id, user_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin AUTO_INCREMENT = 635227 COMMENT = ‘Send task details table’
INSERT INTO imt_coupon_test_db.test (id,create_time,update_time,task_id,user_id,status,reason) VALUES
(593431,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:02.950’,71,1,2,‘’),
(593432,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.030’,71,2452000,2,‘’),
(593433,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.165’,71,3178014,2,‘’),
(593434,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.274’,71,488021,2,‘’),
(593435,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.313’,71,2628001,2,‘’),
(593436,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.356’,71,2452002,2,‘’),
(593437,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.402’,71,2452003,2,‘’),
(593438,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.444’,71,2452004,2,‘’),
(593439,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.483’,71,2452005,2,‘’),
(593440,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.526’,71,2452006,2,‘’);
INSERT INTO imt_coupon_test_db.test (id,create_time,update_time,task_id,user_id,status,reason) VALUES
(593441,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.565’,71,3178015,2,‘’),
(593442,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.607’,71,2452001,2,‘’),
(593443,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.647’,71,3178016,2,‘’),
(593444,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.741’,71,3178018,2,‘’),
(593445,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.782’,71,3238000,2,‘’),
(593446,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.823’,71,3238001,2,‘’),
(593447,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.867’,71,3240003,2,‘’),
(593448,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.923’,71,3240004,2,‘’),
(593449,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.968’,71,108026,2,‘’),
(593450,‘2024-06-04 15:10:20.288’,‘2024-06-04 15:15:03.990’,71,2,3,‘Insufficient stock’);
【Encountered Issue: Problem Phenomenon and Impact】
Duplicate data appears in pagination queries,
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】
GitHub issue: https://github.com/pingcap/tidb/issues/53818