【TiDB Usage Environment】Production
【TiDB Version】5.0.6
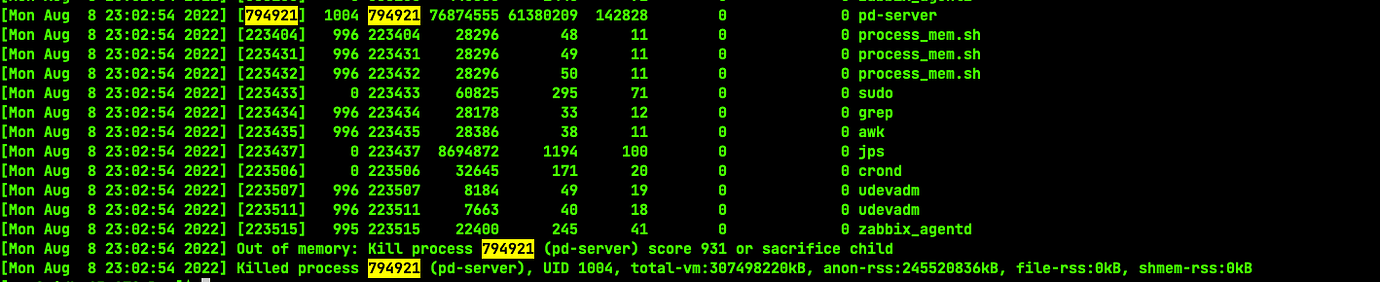
【Encountered Problem】A large number of truncate commands are stuck, causing the PD node to OOM
【Reproduction Path】What operations were performed to cause the problem
The TRUNCATE tasks in the ETL job are executing slowly, causing tasks to pile up.
【Problem Phenomenon and Impact】
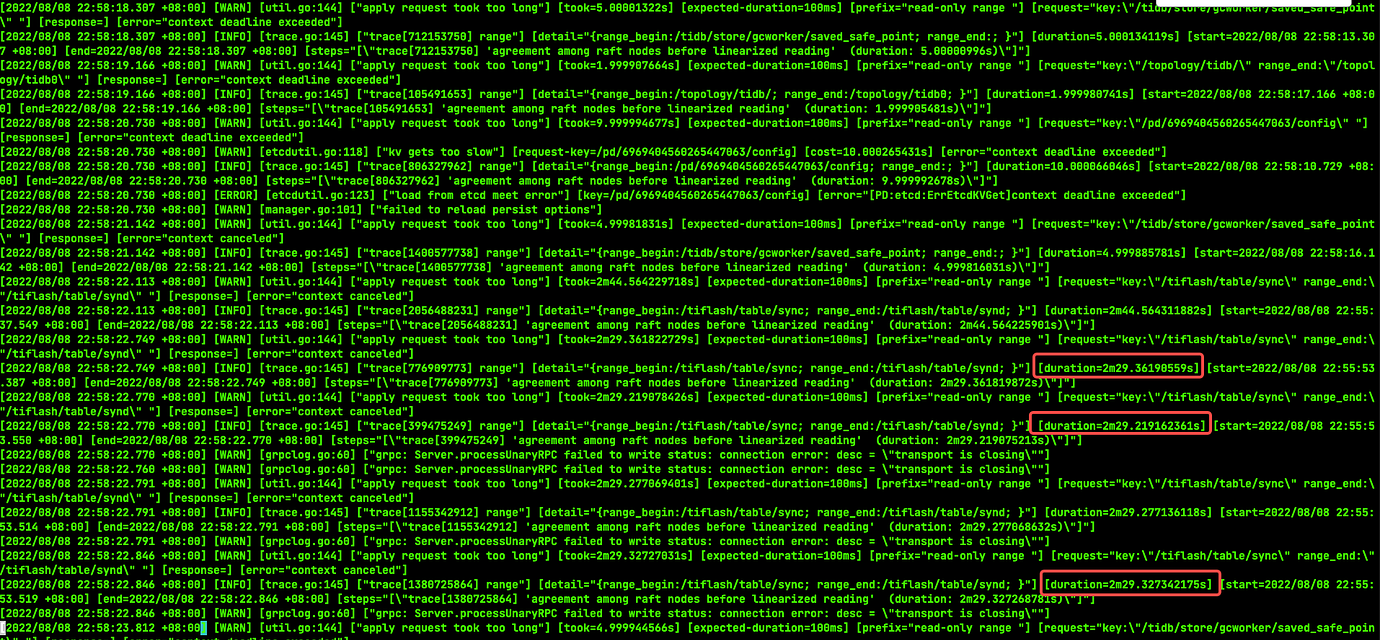
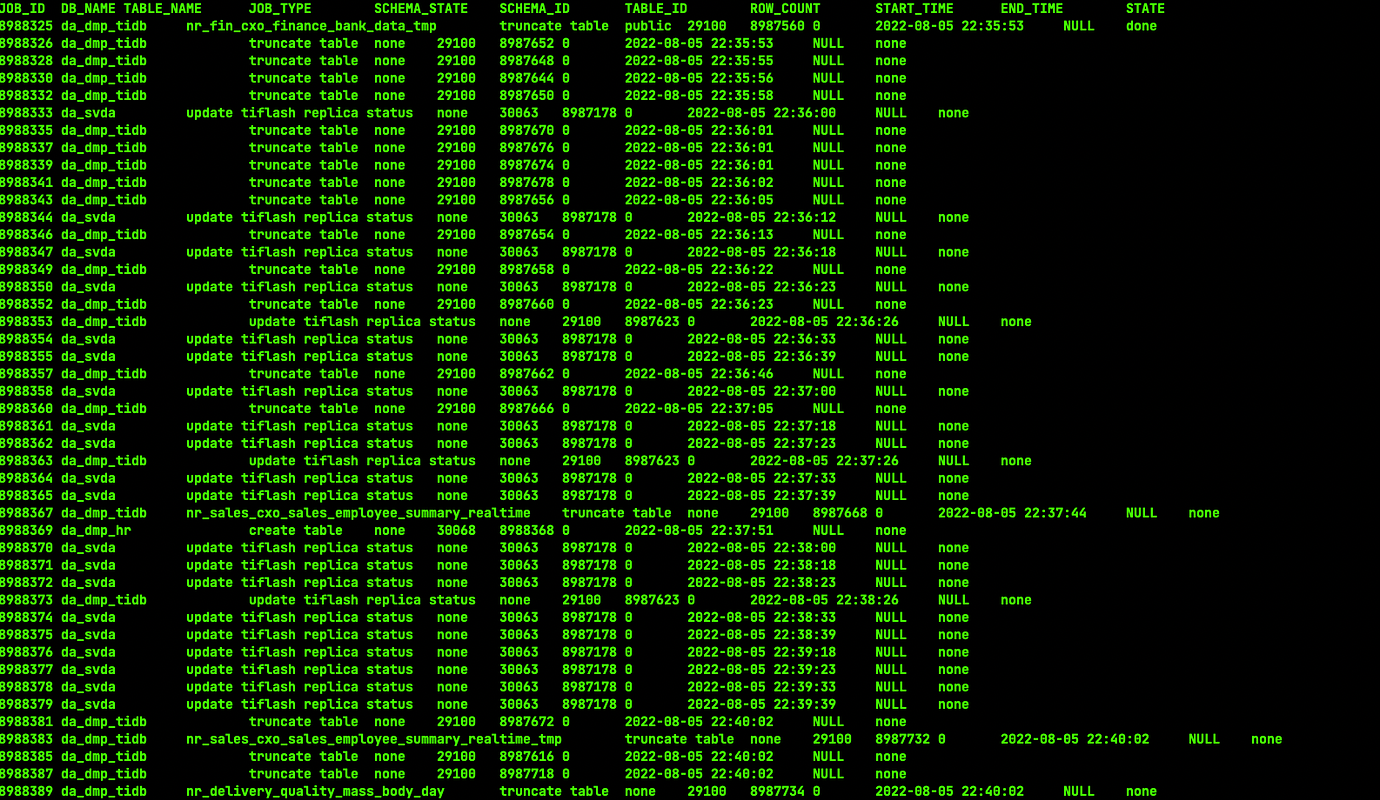
The business feedback indicates that the ETL scheduled task is stuck. The task first performs a truncate operation, then an insert operation. Running admin show ddl jobs shows hundreds of truncate and update TiFlash replica status operations.
The business layer is also being modified. Currently, it is unclear why truncate is so slow. Although it is asynchronous, it should still complete quickly. Normally, tables are processed within seconds. The slowness of truncate is causing issues with subsequent task retries.
There are over 1 million regions, and they appear to be balanced.
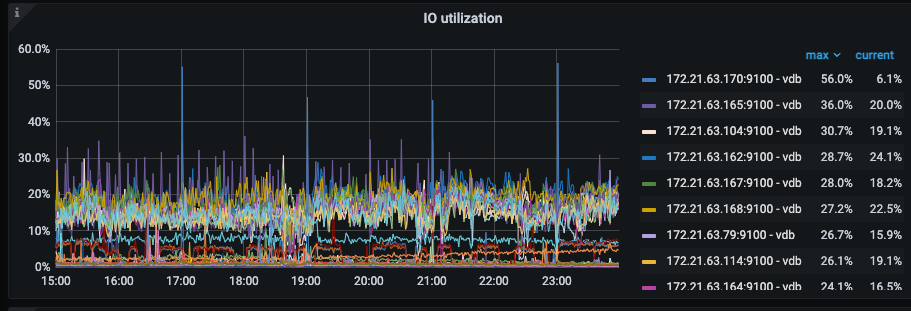
The monitoring graphs are from August 8th, 15:00 to 23:59:59. The PD nodes restarted four times between 16:00 and 23:30.
Now, I want to know why truncate is slow and why PD’s memory usage is spiking.
The tidb_gc_life_time parameter is used to control the GC (Garbage Collection) life cycle. The default value is 10m, which means that data older than 10 minutes will be cleaned up. You can adjust this parameter according to your needs.
The handling of truncate is executed by TiDB. Since it is asynchronous, it requires multiple status checks to execute successfully. To determine the speed, you need to check the status and records of each job execution.
When the number of Regions is very large, it puts a heavy burden on PD because each Region needs to report its heartbeat and some information. It is recommended to refer to the optimization plan for a large number of Regions and optimize accordingly.
Empty Regions also send heartbeats and information. It is recommended to perform quick merging.
For memory spikes, you need to manually collect data for analysis. Generating a flame graph should help identify the issue quickly.
How to check records? The admin show ddl jobs command shows the time, and many of them take 5 minutes or even 20 minutes to execute.
2 and 3. I have just taken over this cluster and also plan to work on this area.