Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: pd报etcd连接不上,CPU和内存飙升,请大佬指点原因
[TiDB Usage Environment] Production Environment
[TiDB Version] v8.1.0
[Reproduction Path] None
[Encountered Problem: Phenomenon and Impact]
-
Phenomenon
The newly built cluster (3 machines, 4c 32G) ran stably for about four days. On June 17, 2024, around 9 AM, feedback indicated application query lag. Upon checking CPU and memory, two nodes’ memory was nearly 100%. The issue was resolved after restarting the machines and modifying the TiKV memory. -
Problem
-
According to the PD logs, there were numerous etcd access errors on all three machines at 9:09 AM (similar errors also appeared on June 12, 2024, with the same symptoms).
[2024/06/17 09:09:03.365 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc001590000/10.88.0.202:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = etcdserver: leader changed”]
[2024/06/17 09:09:03.365 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc0015901e0/10.88.0.202:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = etcdserver: leader changed”]
[2024/06/17 09:09:05.082 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc001590780/10.88.0.201:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = keepalive ping failed to receive ACK within timeout”]
[2024/06/17 09:09:05.082 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc0016761e0/10.88.0.201:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = keepalive ping failed to receive ACK within timeout”] -
PD Monitoring
-
etcd Monitoring
-
Host Resources
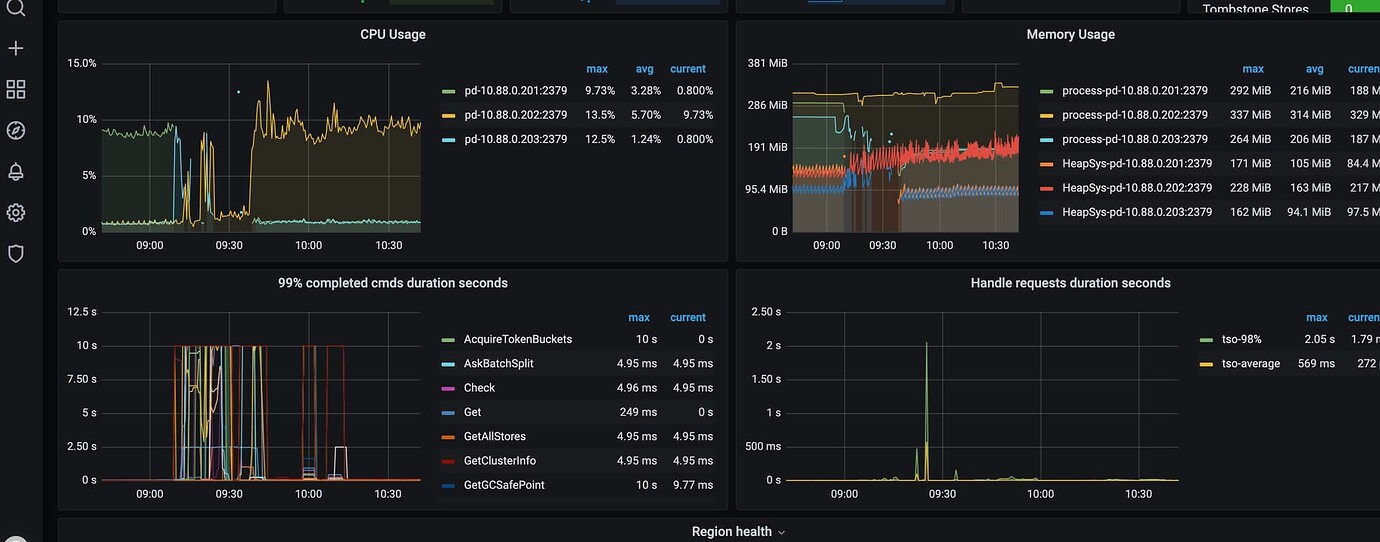
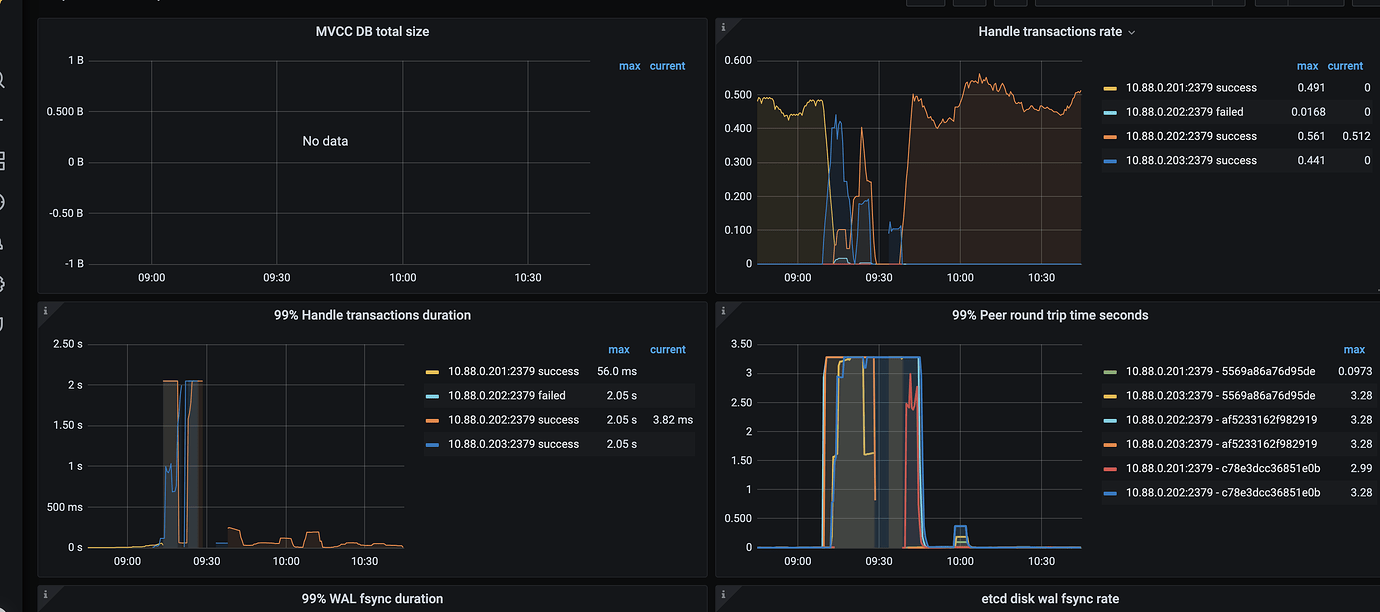
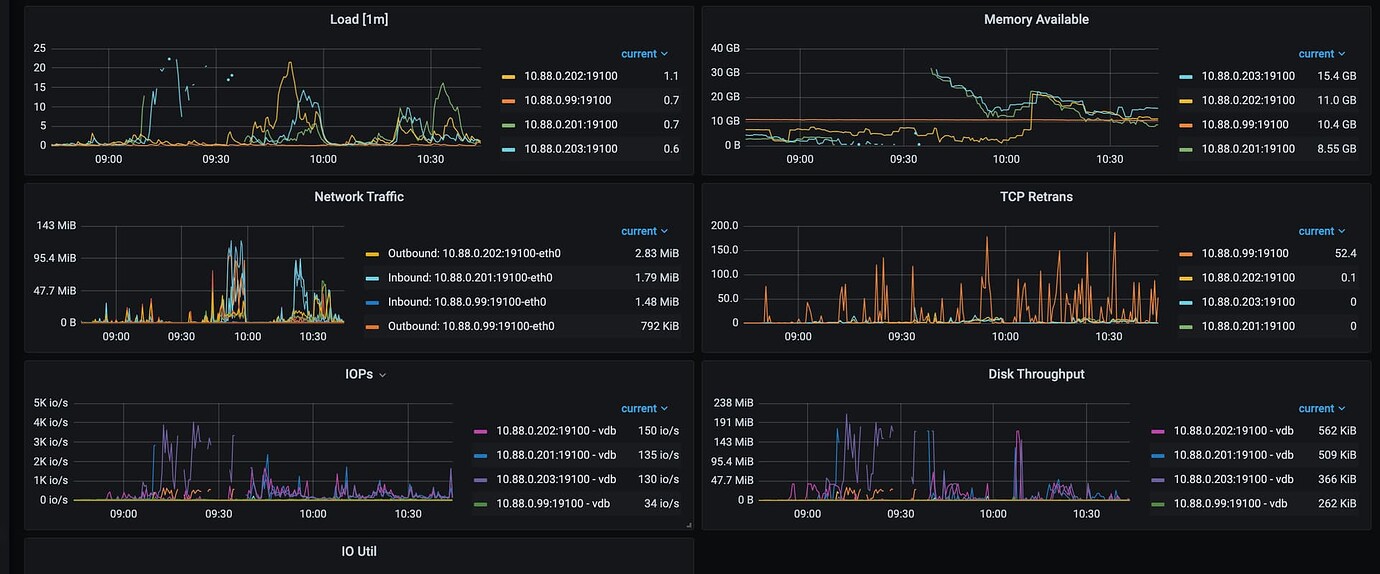
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]