Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
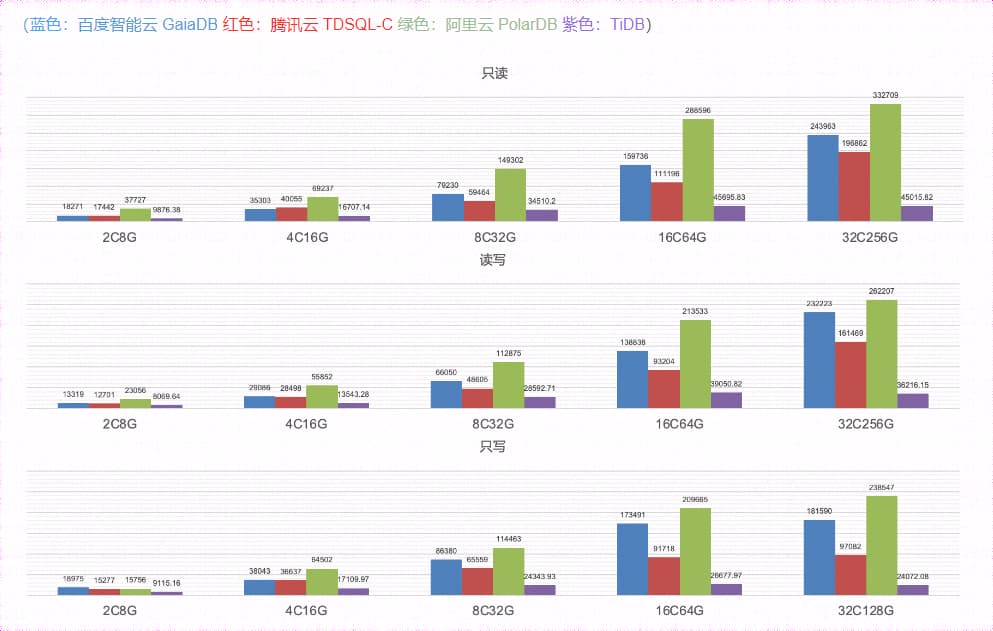
Original topic: TiDB/PolarDB/TDSQL-C/GaiaDB性能压测对比
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
I saw a database test report online, and the conclusion is that TiDB is weaker compared to the other three.
Overall performance ranking: Alibaba Cloud > Baidu Intelligent Cloud > Tencent Cloud > TiDB
Logically, TiDB should perform better in batch inserts (LSM-Tree sequential IO) and point query scenarios (PointGet).
I am a TiDB newbie, could experienced users please explain this? Thank you.
Original article link:
With this amount of data, a standalone machine will definitely run faster. The latency is very small for this amount of data, and for a distributed database like TiDB that separates storage and computation, the network latency will take up a significant portion.
Practice leads to true knowledge. I suggest trying TiDB yourself first to get more familiar with it, and then look at the reviews.
TiDB is suitable for high-concurrency OLTP scenarios. It becomes a more appropriate choice when your business encounters single-machine bottlenecks. For small data volume tests, MySQL or so-called cloud-native databases based on MySQL will definitely perform better than TiDB.
Additionally, the characteristic of LSM-Tree is fast writes and slow reads. Coupled with TiDB’s feature where the tidb-server does not cache data, PointGet must also fetch data from TiKV, so PointGet is actually not advantageous. Previously, when using sysbench for stress testing, TiDB indeed performed better than MySQL in other write scenarios besides PointGet (although the total machine resources required are higher than a single MySQL instance, considering that current MySQL setups typically involve read-write separation with multiple replicas).
Choose what suits you. There is no silver bullet in the software world.
If MySQL can solve the problem, there’s no need to use TiDB.
Also, yesterday it was DM and Otter, and today it’s TiDB and other databases? Are you on a mission?
If it’s appropriate, add me. I want to earn this money too.
Only looking at one’s own user experience. Comparisons without considering the business context are meaningless.
Distributed systems do not have an advantage when the data volume is small, right?
Simulate real business scenarios and data volumes for testing.
Testing without considering business scenarios and data volumes is meaningless.
–table_size=25000 --tables=250
The application scenarios are different, and the data volume in the test is too small. It is recommended to set the table to tens of millions, hundreds of millions, or even billions of rows for testing.
TiDB is a distributed database that can only demonstrate its value under the premise of massive storage.
There are many methods and types of data for testing databases. Selecting some segments for product analysis may have its limitations. If you want to see rankings, you can refer to the more authoritative and fair DB-Engines Ranking - popularity ranking of database management systems, which considers the technical capabilities of the product, community, public acceptance, and more.
It is very common in China that when testing a product, some points are always found to be better than others. We can either conduct the tests ourselves or choose some influential and fair platforms in the industry to look at some data comparisons.
In your business scenario, test it yourself to see which one better meets your expectations; otherwise, it doesn’t make much sense.
It depends on the business scenario; each architecture has its suitable context:
For example, if the scenario is simple and the sharding key is clear, sharding and partitioning might handle a lot of concurrency.
Another example is if my business doesn’t have much concurrency, a single machine works just fine.
Compare and see based on the scenario.