Application environment: Clustered TiDB system with 10 TiKVs, 6 TiDBs and 3 PDs
TiDB version: 6.1.1
Reproduction method:
Insert 1000 rows at a time from multiple server(number of 18):
INSERT INTO table_name (id, value) VALUES (?, ?), ... (?, ?);
while table created by:
CREATE TABLE table_name (id VARCHAR(64) PRIMARY KEY, value TEXT NOT NULL) SHARD_ROW_ID_BITS = 10 PRE_SPLIT_REGIONS = 10;
Each server insert 1000 rows 30 times per a second(seems like it’s too much maybe?).
id is 64-length of string and value has variant size of long string like 1000+ length.
Total size of rows is about 150000000
Problem:
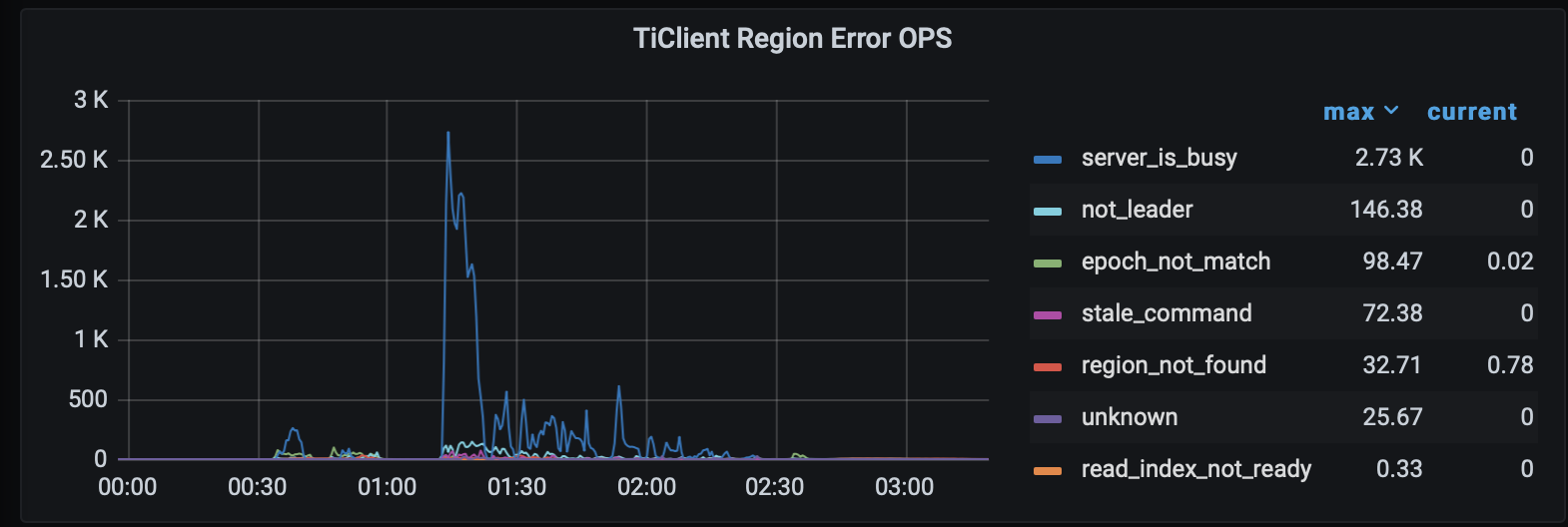
TiDB server gives lots of server_is_busy, not leader and epoch_not_match. Also shows kv failed query OPM.
Should I reduce a size of query or timing? or is there any way to utilize TiDB or query to getting better?
Resource allocation: Total storage capacity is 32TB with NVMe SSD and each of 10 nodes has 128GB of memory
Attachment:
Based on the information you provided, it seems like you are experiencing performance issues with your TiDB cluster when inserting a large amount of data. The error messages you mentioned, such as “server_is_busy”, “not leader”, and “epoch_not_match”, indicate that the cluster is at capability, because the new insertions, the region(storage unit of TiDB) will be full and need to be split into more regions and be migrated to the idle nodes to make load balance.
To improve the performance of your TiDB cluster, you can try the following steps:
- Check the TiDB log files to see if there are any errors or warnings that may indicate the cause of the performance issues.
- Check the resource usage of your TiDB cluster, including CPU, memory, and disk I/O. You can use the
top command to monitor the resource usage of each node.
- Adjust the batch size of your insert queries. You can try reducing the batch size or increasing the time interval between insert queries to reduce the load on the cluster.
- Check the configuration of your TiDB cluster, including the number of TiKVs, TiDBs, and PDs, as well as the storage capacity and memory allocation. You may need to adjust the configuration to better suit your workload.
- Consider using TiDB’s built-in tools for performance analysis and troubleshooting, such as the
EXPLAIN statement and the TiDB Dashboard.
If the above steps do not resolve the performance issues, you may need to consult with TiDB support or consider upgrading to a newer version of TiDB that may have improved performance and scalability.