[TiDB Version] v6.5.5
With the upgrade of the TiDB version, some concepts about clustered and non-clustered tables have become blurred during the use of the TiDB database. I have the following questions:
Regarding clustered tables:
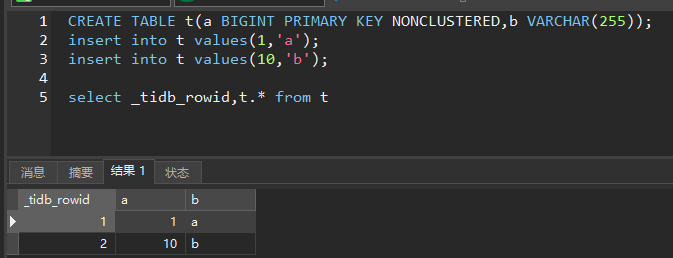
The key-value pair of a clustered table is: primary key column data (key) - row data (value)
My question 1: If the primary key of the table is not an integer or the primary key is not a single column, is the key-value pair of the clustered table still like this? Is there a creation of tidb_rowid?
My question 2: How is the key-value pair of the secondary index of the clustered table composed? If the primary key is not an integer or the primary key is not a single column, will it change?
Regarding non-clustered tables:
The key-value pair of a non-clustered table:
tidb_rowid (key) - row data (value)
Primary key column data (key) - _tidb_rowid (value)
My question is, if the primary key of this non-clustered table is an integer, is the composition of the key-value pair in the secondary index of this table optimized to the primary key value or is it still tidb_rowid? According to the composition of the table data, tidb_rowid should be more efficient, but the document https://docs.pingcap.com/zh/tidb/stable/tidb-computing#索引数据和-key-value-的映射关系 does not distinguish between the two table types.
1: If the primary key of the table is not an integer or there is more than one primary key, in higher versions it is still a key-value pair, where the key is the primary key and the value is the data, without creating tidb_rowid.
2: The second one uses _tidb_rowid.
Testing
For non-clustered tables, the key used is _tidb_rowid.
The index of a clustered table is unrelated to the rowid.
Whether it is a clustered table or a non-clustered table, the key of the index is the value of the index column, and the key value is the value of the key in the data key-value pair. For a clustered table, it is the primary key, and for a non-clustered table, it is the rowid.
The difference between clustered and non-clustered tables is that the primary key of a clustered table is part of the Key in the KV mapping, while the Key of a non-clustered table is composed of the internally assigned _tidb_rowid by TiDB. Essentially, the primary key is a unique index, and only non-clustered tables have _tidb_rowid.
When creating a table, you can explicitly specify whether it is a clustered or non-clustered table. For statements that do not explicitly specify this keyword, the default behavior is influenced by the system variable @@global.tidb_enable_clustered_index. This variable has three values:
OFF means all primary keys use non-clustered indexes by default.
ON means all primary keys use clustered indexes by default.
INT_ONLY means the behavior is controlled by the configuration item alter-primary-key. If this configuration item is set to true, all primary keys use non-clustered indexes by default; if set to false, primary keys composed of a single integer type column use clustered indexes by default, while other types of primary keys use non-clustered indexes by default.
If the primary key of the clustered table is not an integer or the primary key is not a single column, the clustered table does not create _tidb_rowid. You can try creating a clustered table with a primary key that is not an integer or not a single column, and then query _tidb_rowid to see if it reports an error; I understand that at this time its key value has become its primary key value (currently there is no specific evidence to certify this, I don’t know if any experts can prove it ).
I understand the same as above, the RowID part of the key-value pairs of the secondary index of the clustered table also becomes the primary key value.
Of course, it’s important. Clustered table data is arranged in order by the primary key, and the primary key does not have a physical index. Secondary indexes have additional physical indexes.
A clustered table is stored according to the primary key, and the secondary index points to the primary key’s key, hence it’s called a secondary index.
In a non-clustered table, data is stored as _tidb_rowid, and both the primary key and ordinary indexes point to _tidb_rowid, so it shouldn’t be called a secondary index.
Clustered tables have secondary indexes except for the primary key.
For non-clustered tables, I believe they are all secondary indexes. The primary key is just a unique non-null index, and the primary key is hidden as _tidb_rowid.