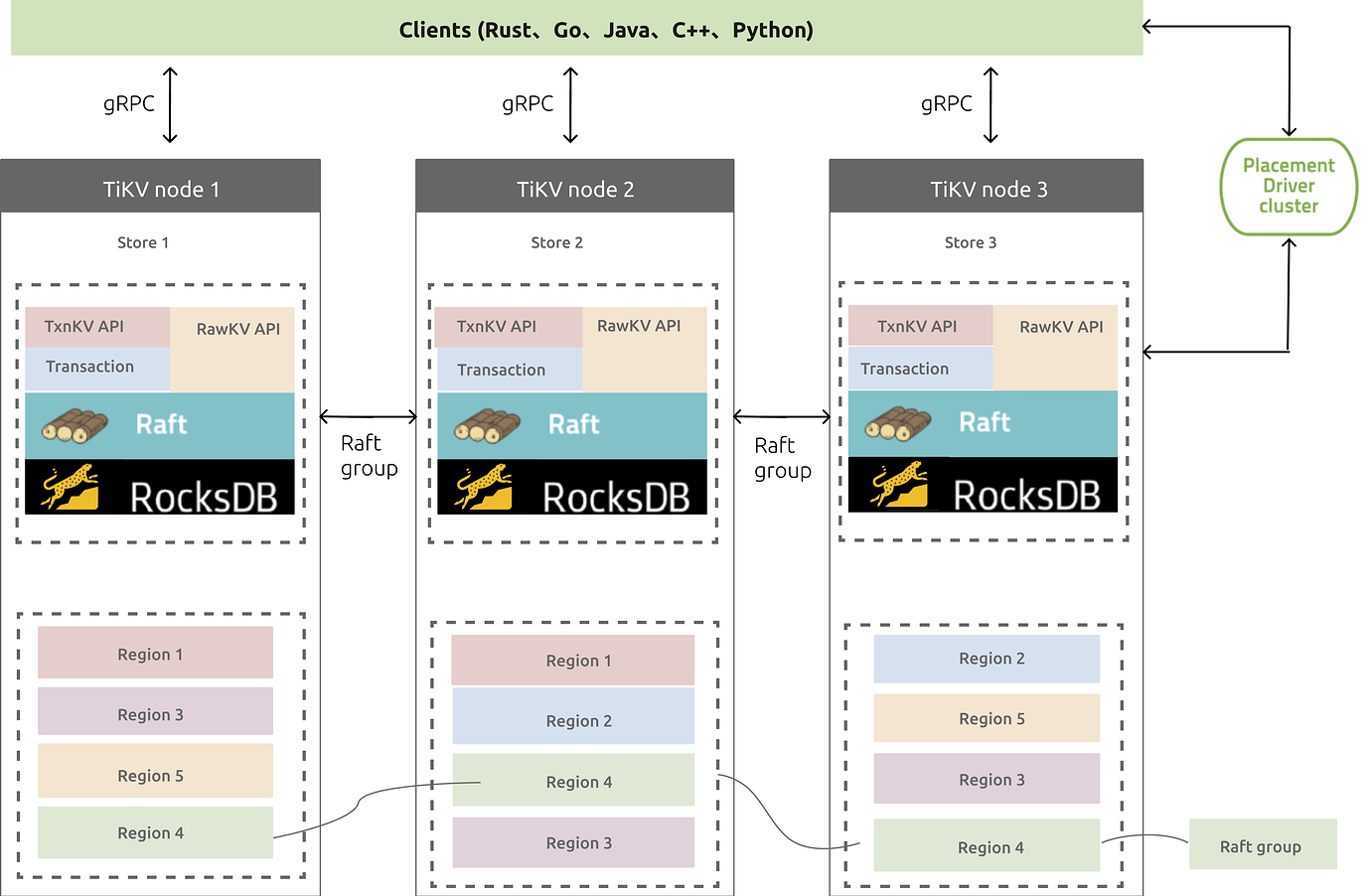
The documentation mentions that in TiDB, you can specify Regions for tables. I want to know if this functionality is also available when using TiKV alone. If not, does TiKV expose any interfaces for this? If so, I would like to know the corresponding source code location. At the TiKV Client level, can this functionality be extended? In the TiKV layer, it wouldn’t be specified at the table level but rather based on business scenarios, specifying Regions for a certain type of data within the scenario.
Apart from not having TiDB, it also has PD, but the scheduling support is relatively limited. It only supports:
Add a new replica
Remove a replica
Transfer a Region leader between replicas in a Raft group
They are implemented by the Raft commands AddReplica, RemoveReplica, and TransferLeader.
Reference documentation:
Additionally, whether using RawAPI or TxnAPI, after deleting a key, corresponding processing is required (refer to LSMTree characteristics). If the actual data is not reclaimed (refer to RocksDB compaction), these keys can still be accessed.
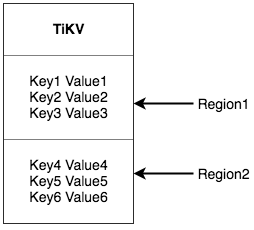
Regarding the range of keys, I want to confirm something. I see that in the source code, keys are stored using Vec, but I haven’t looked closely at how the range is specifically defined. I guess the boundary of the region range is determined by the byte length of the key, right?
You can define the scope yourself, referring to the way keys are defined in TiDB, which also follows the left-closed, right-open principle.
Refer to the following:
Hash: Hash the key and select the corresponding storage node based on the hash value.
Range: Divide keys into ranges, with a continuous segment of keys stored on a single storage node.
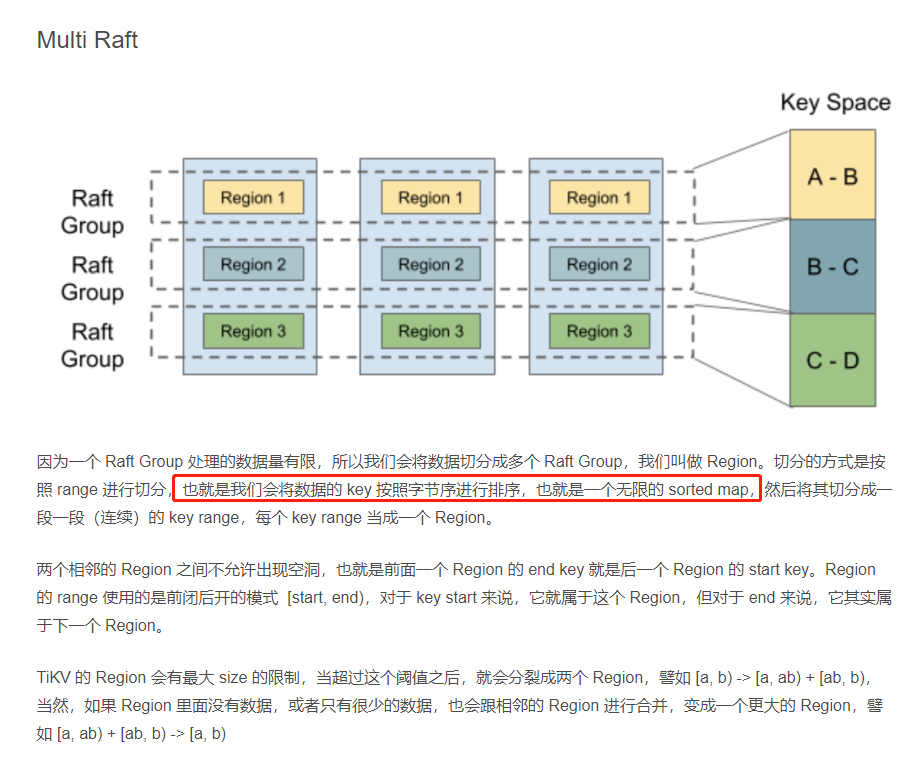
TiKV chooses the second method, dividing the entire key-value space into many segments. Each segment is a series of continuous keys, called a Region, and it tries to keep the data in each Region below a certain size, currently defaulting to 96MB in TiKV. Each Region can be described by a left-closed, right-open interval like [StartKey, EndKey).
Then, through data scanning, you can find some answers:
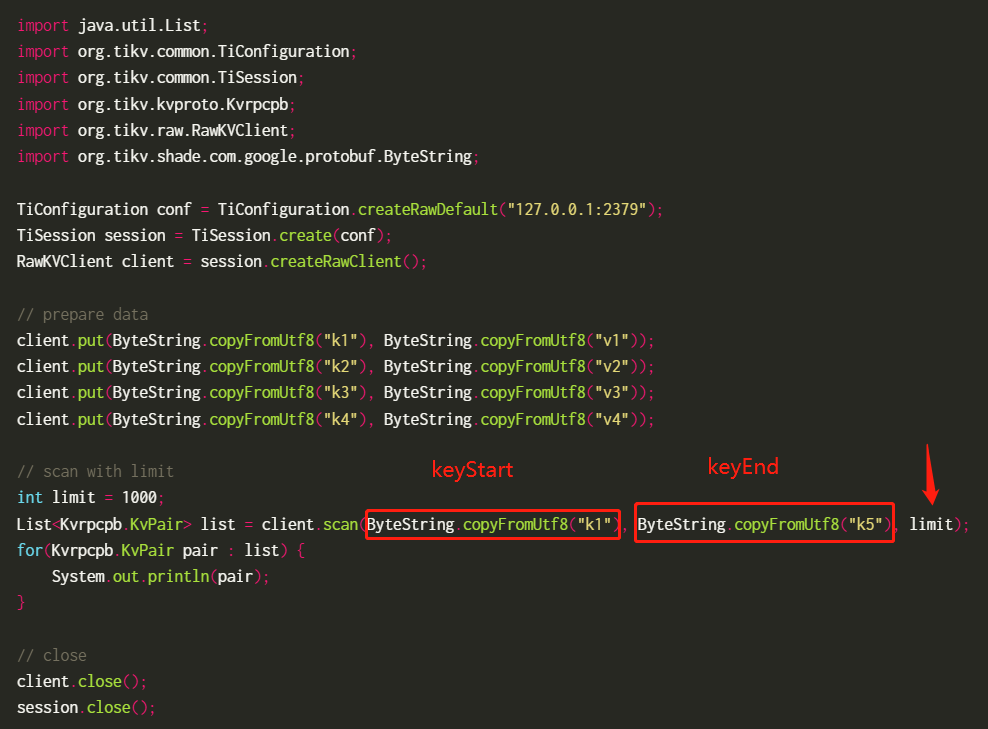
I tried the API, and by default, it should set the range boundaries based on the byte length of the key. However, you mentioned that the range can be defined by oneself. Is this something that can be done at the client level? I didn’t see any place in the client’s API where the region range can be specified, only the region size is configurable.
If you want to adjust the boundary mode, you need deep customization, which means you have to modify it yourself (I understand that at the business level, you only need to consider the number of replicas and the location of the written data, and you don’t even need to worry about which Region the data is in. In fact, you can read it from PD).
The boundary model is a collaborative solution handled by both TiKV and PD to meet scheduling capabilities.
I have a general understanding, but my core question is about specifying regions for data in TiKV. This is a bit off-topic, haha, but it’s still informative. Do you have any knowledge about specifying regions?
For example, for this monthly partitioned table, if you require the data from the last 2 months to be stored in hot storage, you can place PARTITION p7 on the SSD partition to achieve hot and cold separation, and move PARTITION p6 back to the HDD.