Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tidb 执行计划的order by limit 疑问
Version v5.3.3
I have a question.
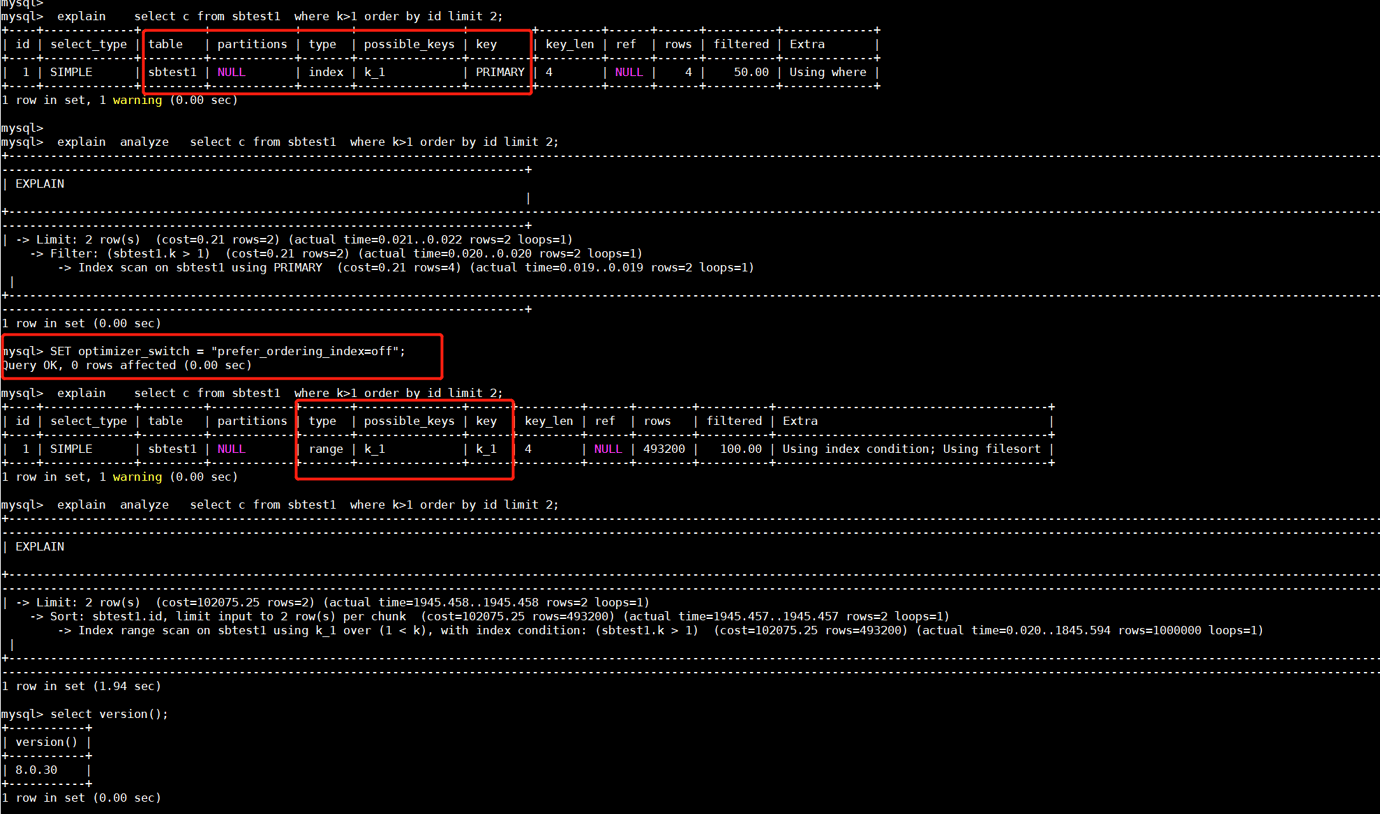
After importing table data into TiDB using sysbench, I performed the following query on the sbtest1 table: select c from sbtest1 where k>1 order by id limit 2;
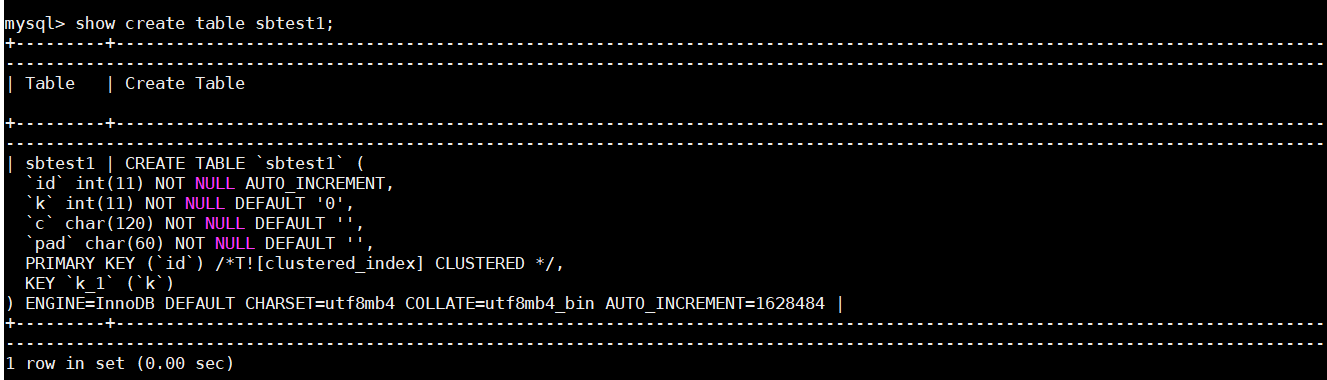
Table structure
Execution plan
mysql> explain analyze select c from sbtest1 where k>1 order by id limit 2;
+--------------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+--------------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-----------+------+
| Projection_8 | 2.00 | 2 | root | | time:1.87ms, loops:2, Concurrency:OFF | sbtest.sbtest1.c | 646 Bytes | N/A |
| └─Limit_12 | 2.00 | 2 | root | | time:1.87ms, loops:2 | offset:0, count:2 | N/A | N/A |
| └─TableReader_25 | 2.00 | 2 | root | | time:1.86ms, loops:1, cop_task: {num: 1, max: 1.81ms, proc_keys: 32, rpc_num: 1, rpc_time: 1.8ms, copr_cache_hit_ratio: 0.00} | data:Limit_24 | 2.10 KB | N/A |
| └─Limit_24 | 2.00 | 2 | cop[tikv] | | tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 32, total_process_keys_size: 7168, total_keys: 80, rocksdb: {delete_skipped_count: 5, key_skipped_count: 84, block: {cache_hit_count: 2, read_count: 0, read_byte: 0 Bytes}}} | offset:0, count:2 | N/A | N/A |
| └─Selection_23 | 2.00 | 32 | cop[tikv] | | tikv_task:{time:0s, loops:1} | gt(sbtest.sbtest1.k, 1) | N/A | N/A |
| └─TableFullScan_22 | 2.00 | 32 | cop[tikv] | table:sbtest1 | tikv_task:{time:0s, loops:1} | keep order:true | N/A | N/A |
+--------------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------+-----------+------+

Here, the reason for choosing a table full scan, I guess, is as follows:
-
Because
idis the primary key, during the full table scan, ifk>1is encountered, the value of thecfield can be directly retrieved. At this time,iditself is already ordered, so as long ask>1is encountered twice, this statement can be completed. In this case, the full table scan is not slow, but I think this is based on the assumption thatk>1can be found quickly in the full table scan.
However, there may be a situation where it takes a long time to find values that satisfyk>1in the full table scan. Does this mean that the full table scan is not the optimal solution in this case? At this time, using the index on thekfield to search might be a better solution. I wonder if this guess is correct.
Comparing MySQL’s execution plan, the default behavior of the MySQL optimizer is also similar to TiDB’s full table scan (directly scanning the entire primary key index), but by adjusting parameters, the optimizer can be made to choose the index on thekfield.
-
I don’t quite understand why the
actRowsin TiDB’s execution plan is 32. Could you please explain this?