Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: range分区表order by 索引列limit 1 长时间未返回
Bug Report
Clearly and accurately describe the issue you found. Providing any steps to reproduce the issue can help the development team address it promptly.
[TiDB Version]
Server version: 5.7.25-TiDB-v6.1.0
[Impact of the Bug]
Order by index column does not return results for a long time
[Possible Steps to Reproduce the Issue]
Background: The table has a total of 13 billion rows, partitioned by day, with each partition having about 100 million rows.
-
Partitioned Table
Primary Key Index: PRIMARY KEY (dt,doc_id) /*T![clustered_index] NONCLUSTERED */,
PRIMARY KEY (dt,doc_id) /*T![clustered_index] NONCLUSTERED */,
KEYupdatetime(updatetime),
KEYnewdate(newdate)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![placement] PLACEMENT POLICY=storeonssd*/
PARTITION BY RANGE (UNIX_TIMESTAMP(dt))
(PARTITIONp20210601VALUES LESS THAN (1622563200),
…) -
explain
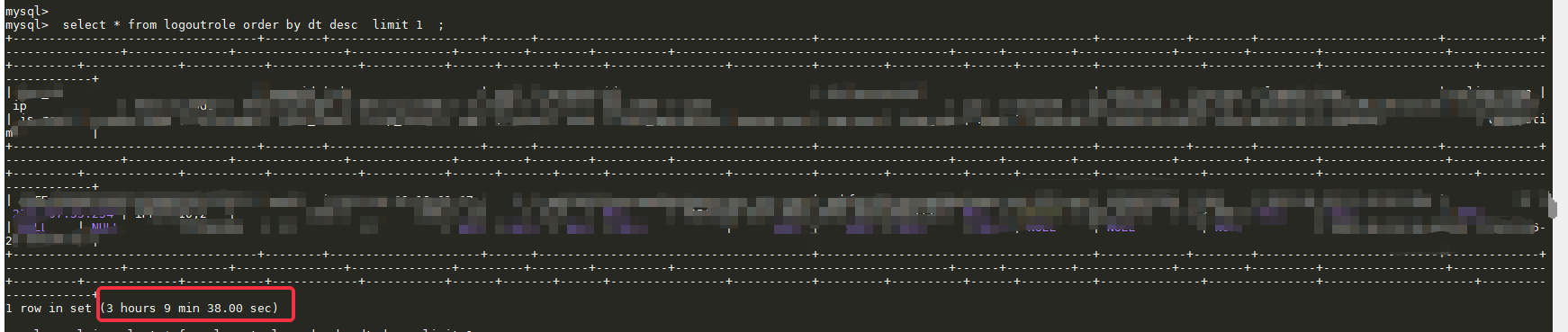
Executed SQL: select * from logoutrole order by dt desc limit 1;
-
Execution, no result returned for a long time
-
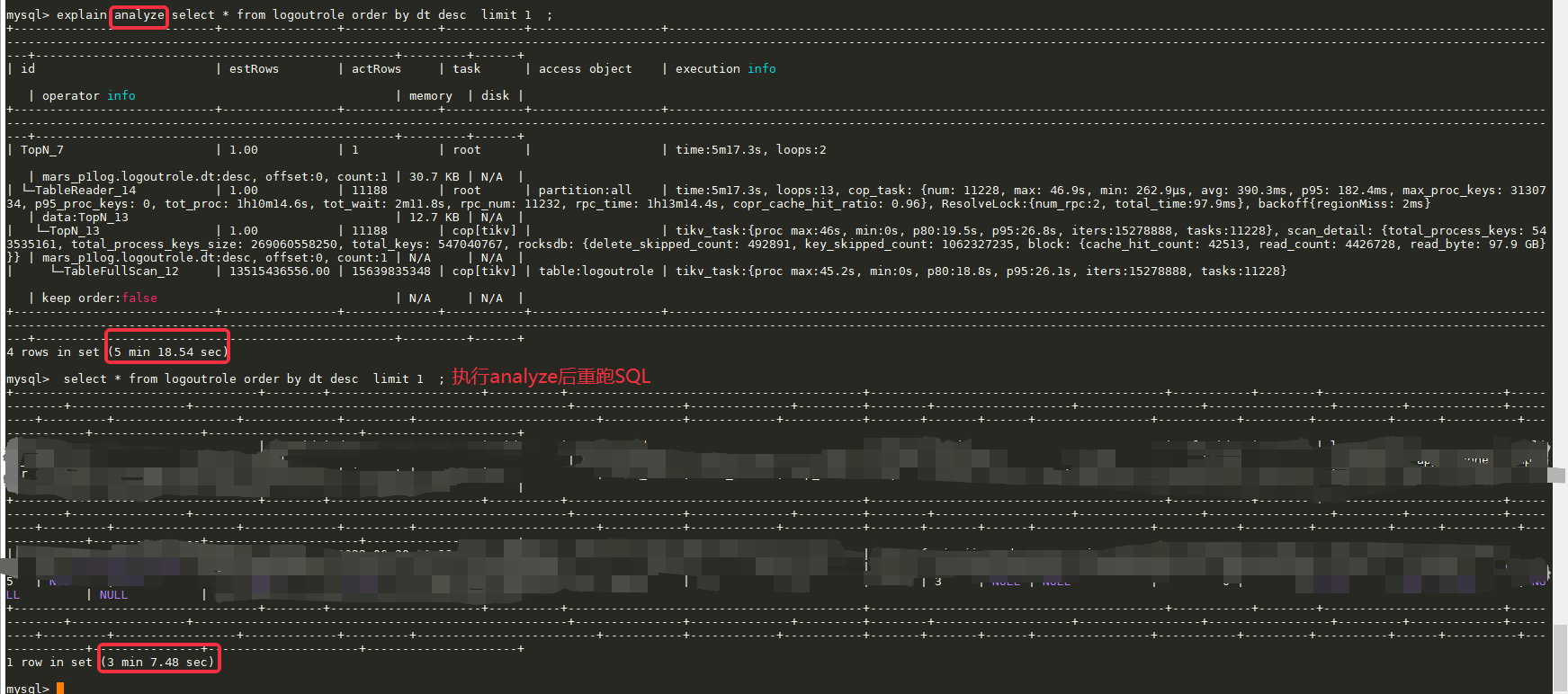
View explain plan
-
Execute explain analyze and rerun, it becomes faster
-
Using the complete primary key index order by, still no result for a long time



[Observed Unexpected Behavior]
No result returned for a long time, and the execution plan includes the TableFullScan_12 operator
[Expected Behavior]
The execution plan should not require TableFullScan and should return the query results quickly
[Related Components and Specific Versions]
tidb
v6.1.0
[Other Background Information or Screenshots]
Such as cluster topology, system and kernel version, application app information, etc.; if the issue is related to SQL, please provide the SQL statement and related table schema information; if there are critical errors in the node logs, please provide the relevant node log content or files; if some business-sensitive information is inconvenient to provide, please leave contact information, and we will communicate with you privately.


