Author: Phoebe He (DevRel & Community at PingCAP)

ZTO Express (NYSE: ZTO) is one of the largest delivery companies in the world. ZTO delivered 17+ billion parcels—a 20.4% market share in 2020. Accelerated by Covid, the significantly increased loads of parcels are putting the supply chain to the test. At the same time, logistics companies are competing over speed and service, especially during peak shopping days or weeks.
Supply chain industry challenges
Higher customer satisfaction bar
With digital front-end devices like smartphones, customers need a personal page that shows order histories and tracks their parcels. On time performance (OTP) and real-time tracking becomes the key differentiating factors for choosing logistics companies.
ZTO uses 100+ information systems to fully digitize parcel tracking. They collect billions of data points to improve customer experience with real-time parcel tracking on any device at any time. The central parcel information system also monitors the overall parcel volume, and identifies the peaks and the hot regions for last mile rerouting. A delayed parcel means late fees, so accurate data monitoring is very important.
Higher operational cost
The overall cost for logistic companies includes transportation costs, inventory carrying costs, and administration costs. Big data and a secondary distribution logistic system with true real-time dashboards and instant scheduling play important roles, because they reduce all three costs.
Tens of thousands of tracks support ZTO’s delivery network. Packages are stored in the distributor center, and packages that go to similar destinations are merged and dispatched together. ZTO’ssecondary distribution logistic system predicts the route each parcel will take. While the parcel is enroute, the system captures any changes in parcel data, which enables real-time diagnostics based on fresh data. Therefore, ZTO needed to handle large amounts of data with low latency, and they built a wide table with more than 70 fields.
Exadata could not meet ZTO’s needs
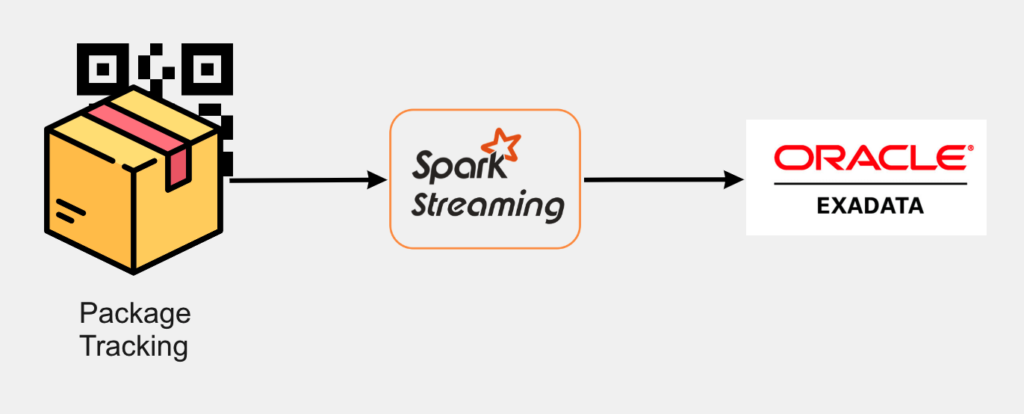
Before ZTO adopted TiDB, the data collected by the 100+ information systems was synced to thecentral parcel information system through Spark and then stored in Oracle. ZTO had API and application data services to provide external service capabilities.
As ZTO’s business workload accelerated, their IT architecture had trouble keeping pace with the exponential growth of data volume and high concurrent updates with reasonable hardware upgrading cost.
Also, their architecture couldn’t meet the requirement for real time diagnostics based on large amounts of data. These diagnostics are the foundation of monitoring and scheduling.
In summary, ZTO’s challenges were:
- Data storage. The legacy system could only store 15 days of historical data. As daily data volume increased, it was more costly to scale up. Also, business apps needed to track more than 15 days of data.
- Last minute rerouting. The former tech rack, extract-transform-load (ETL) with DataX and Sqoop, had high ingestion delay, throughput was not ideal, and query response time was low. This led to decision making based on stale data.
- Peak day performance. The system could not scale up freely year by year or on peak days.
TiDB: agile business support with a simpler structure
In 2019, ZTO chose TiDB and now has 100+ TiDB physical nodes in their production environment. These nodes are used by billing, order center, message center, and smart transshipment-related applications. The new information system provides a better customer experience, increases efficiency, and lowers operation cost.
That same year, ZTO completed 12.12 billion orders—a year-on-year increase of 42.2%, which exceeded the industry average growth rate by 16.9 percentage points. The ZTO’s business department was thrilled: “Our IT efficiency improved 300%!”
Now, ZTO knows each parcel’s status during transportation in near real time. Through the secondary distribution logistic system, the delivery fee per package was reduced by an average of 25% in Tier 1 and Tier 2 cities. With TiDB, the new information system refined management and increased operational efficiency. In the second quarter of 2020, ZTO’s cost per order dropped by 17.1% year-on-year.
With TiDB, the supported data storage period extended from 15 days to 45 days. In a 2021 national survey on parcel delivery, ZTO kept a high on-time performance (OTP) rate of 80 ~ 90% and, for the first time, became one of the top three OTP performers. During the “single’s day” event in 2021, ZTO handled 300 million parcels, which was about 8.6 times their regular parcel load, and delivered over 100 million parcels in a single day. Many people living in Tier 1 cities placed their order before they went to sleep and got their parcel before they had their breakfast the next day.”
A simpler structure at scale
Because TiDB is MySQL-compatible, it fits in ZTO’s current architecture and solves all the challenges stated previously. TiDB supports multiple application systems with real-time write. TiSpark also helped ZTO to achieve a real-time dashboard, with fast and accurate data queries that are based on multiple data sources’ aggregation. TiSpark also provides a standard API for applications to easily query.
With TiDB, the new system supports:
- Full path tracking with auto scalability based on the workload size. This provides more accurate delivery times and a solid baseline for scheduling and monitoring.
- High concurrent updates that reflect the most current package data. The system was able to do this even during a peak day with 70,000 transactions per second (TPS) of write/update operations in TiDB and 300 MB/s write in the column store TiFlash.
- Real-time diagnostics based on large amounts of data, wide tables, and multidimensional query analytics with fast scan with column store, fast group by, and strong consistency.
- Overall insight freshness based on high concurrent queries of the latest data with strongly-consistent distributed transactions and secondary indexes.
- TiSpark support for ZTO’s online minute-level data analytics. This guaranteed IT service run steadily on ZTO’s sales promotion days.
Unboxing the simpler structure
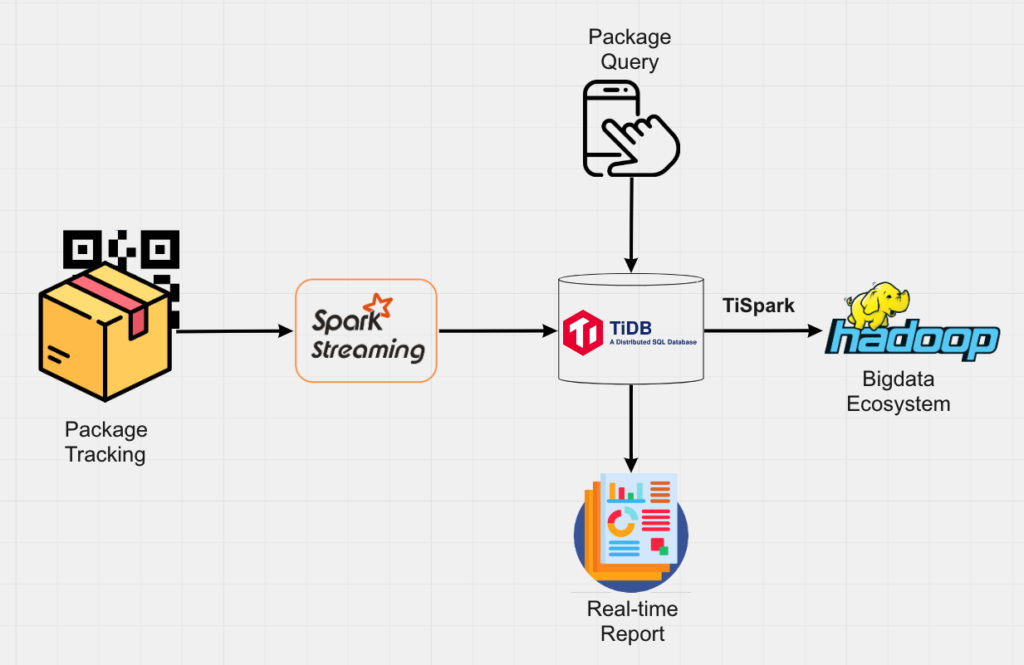
In this architecture, Spark streams aggregates online and offline data sources and writes them to TiDB. For example, Spark joins the package state transition events with offline dimension data about the packages.
The result is written to TiDB in real-time. TiDB can process data aggregations of 300 million rows of data to Hive.
TiDB relies on the row store to support the high concurrent user-facing package inquiries and relies on the column store to support the real-time report which involves aggregation on multiple dimensions.
TiDB’s TiSpark component bridges the real-time layer (TiDB) and Hadoop ecosystem. Periodically, the data in TiDB is archived to Hadoop Distributed File System (HDFS) or Amazon S3 for heavyweight offline analysis.
Summary
With TiDB, ZTO’s new full-path digitization system pays for itself. It provides a better customer experience with a longer period of parcel historical information, great on time performance (OTP), increased efficiency through the scheduling and route optimization, as well as reduced operation and delivery costs.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!