Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 关于排序后查询结果集不稳定的问题
To improve efficiency, please provide the following information. Clear problem descriptions can be resolved faster:
[TiDB Usage Environment]
Test environment
[Overview] Scenario + Problem Overview
The following table structure and test data are provided:
DROP TABLE IF EXISTS `test1`;
CREATE TABLE `test1` (
`a` int(11) NULL DEFAULT NULL,
`b` int(11) NULL DEFAULT NULL,
`c` int(6) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin;
INSERT INTO `test1` VALUES (1, 1, 0);
INSERT INTO `test1` VALUES (2, 2, NULL);
INSERT INTO `test1` VALUES (3, 3, 0);
INSERT INTO `test1` VALUES (4, 4, 0);
INSERT INTO `test1` VALUES (5, 5, 0);
INSERT INTO `test1` VALUES (6, 6, 0);
DROP TABLE IF EXISTS `test2`;
CREATE TABLE `test2` (
`a` bigint(20) NULL DEFAULT NULL,
`b` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin;
INSERT INTO `test2` VALUES (34, 3);
INSERT INTO `test2` VALUES (53, 5);
INSERT INTO `test2` VALUES (38, 39);
INSERT INTO `test2` VALUES (22, 2);
INSERT INTO `test2` VALUES (87, 51);
INSERT INTO `test2` VALUES (45, 67);
INSERT INTO `test2` VALUES (88, 4);
INSERT INTO `test2` VALUES (567, 786);
INSERT INTO `test2` VALUES (67, 678);
INSERT INTO `test2` VALUES (234563, 65);
INSERT INTO `test2` VALUES (546, 8);
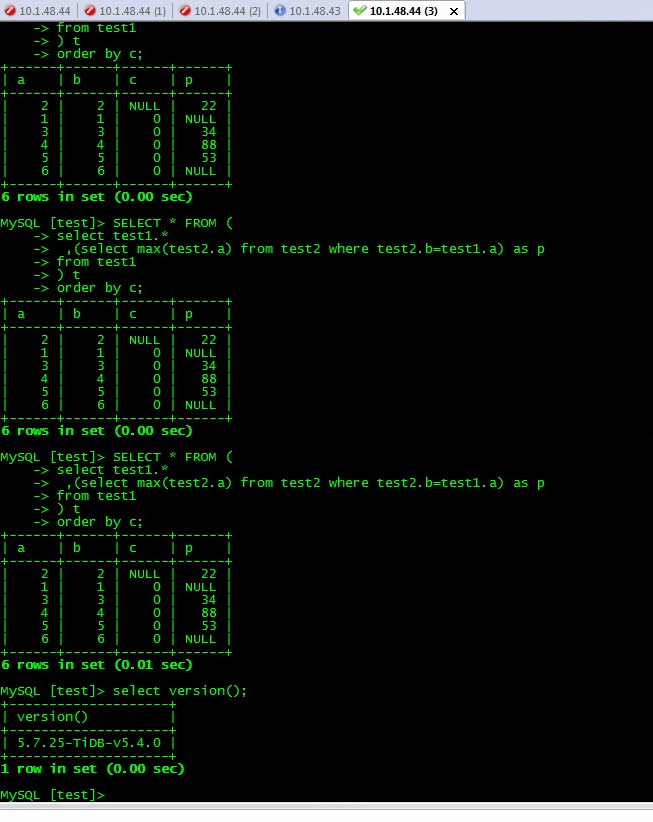
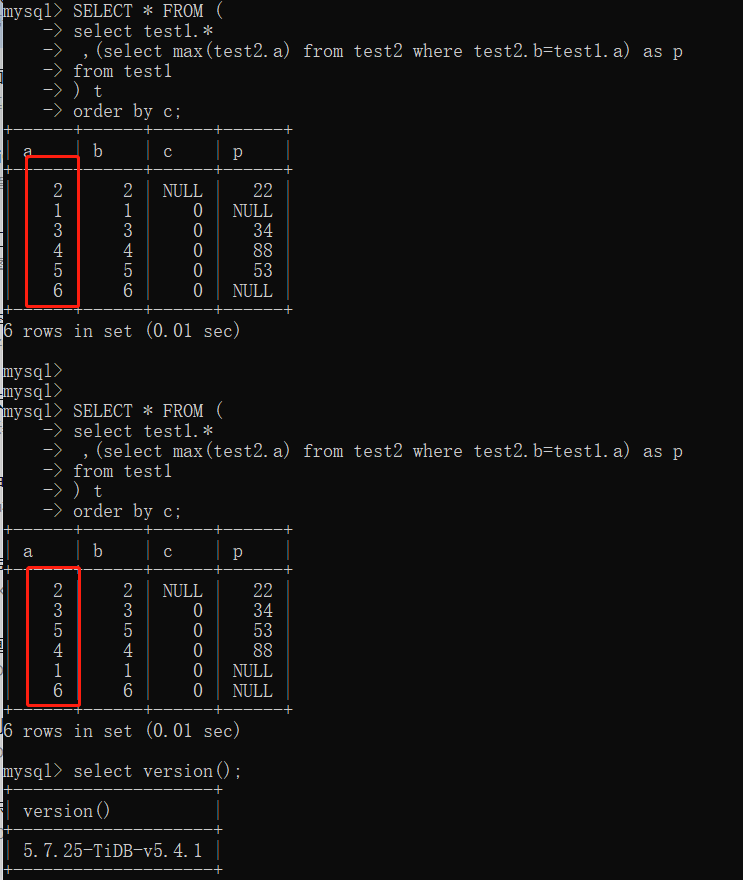
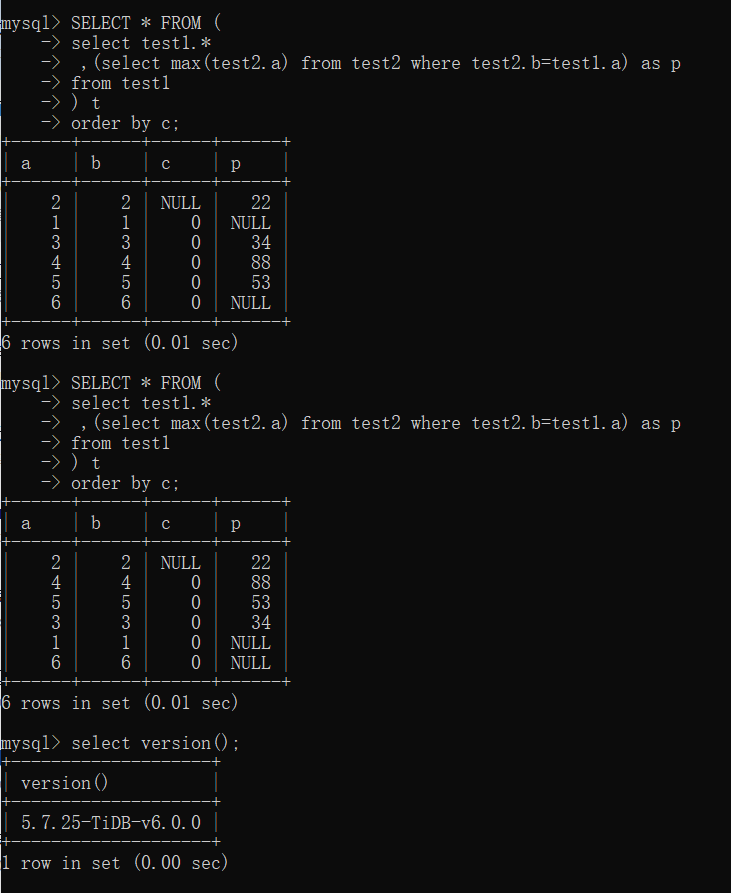
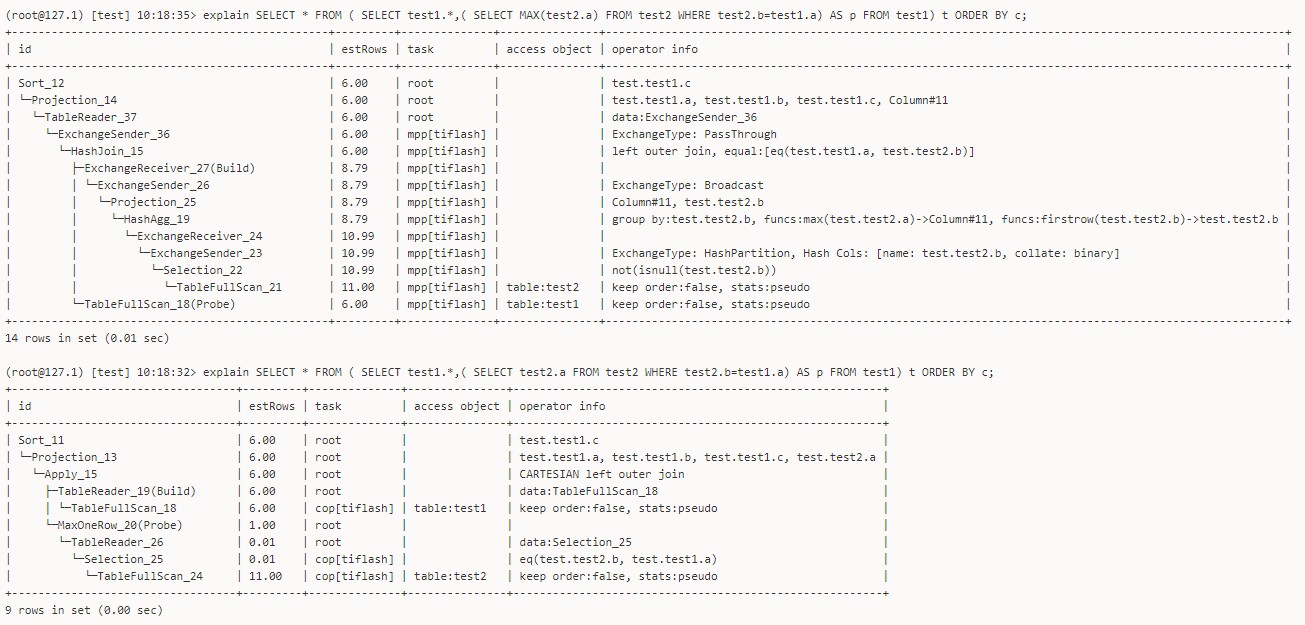
Query SQL (result order is unstable):
SELECT * FROM (
select test1.*
,(select max(test2.a) from test2 where test2.b=test1.a) as p
from test1
) t
order by c
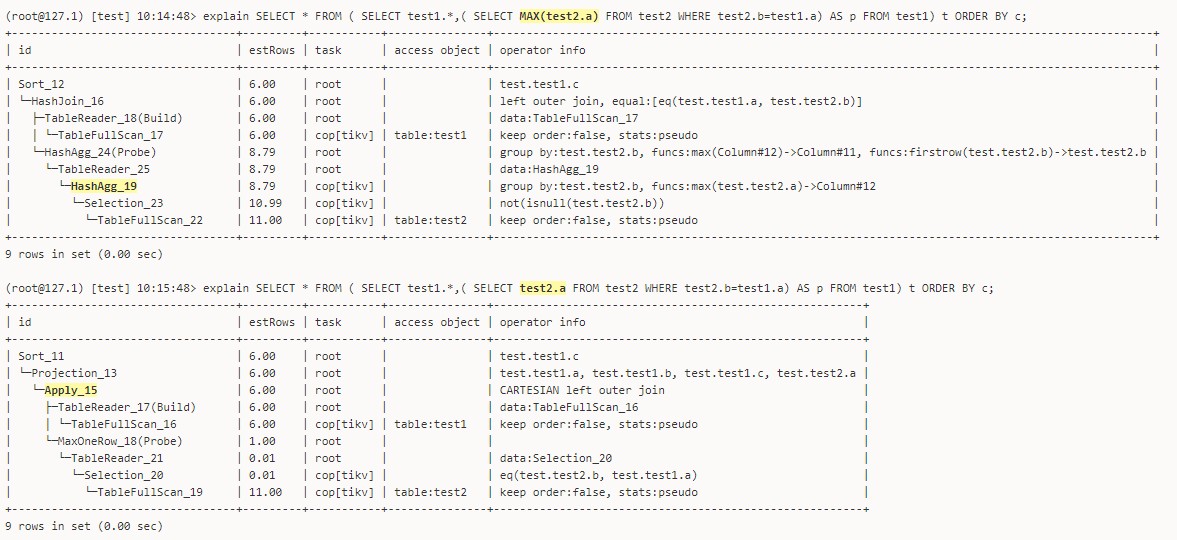
Sorting query based on the c field of test1 (with duplicate and null values) and including a subquery from test2, the result set order is unstable.
However, if the subquery is removed, the result set order is stable. Further investigation found that removing the max function in the subquery also stabilizes the order.
The above script can reproduce this issue.
[Problem]
- Why does using a function in the subquery cause the result set to be unstable?
- For single table queries, if the sorting field has duplicate values, what rule determines the final output order?
[Business Impact]
Unstable query results
[TiDB Version]
5.2.2
If the question is about performance optimization or fault troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output results for upload.