Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TIDB 对网络延迟or丢包的要求
【TiDB Usage Environment】Production Environment
【TiDB Version】V6.1.7
【Encountered Issue: Problem Phenomenon and Impact】TiDB has a storage-compute separation architecture. Network latency and packet loss can significantly impact the performance of the entire cluster. It would be helpful to have some recommended and empirical values, such as: the ping latency between the physical machines of the three modules should be within x ms, and the number of packet losses should be less than x, etc.
Reference values for experience:
Latency within a single DC should be less than 0.5ms, between two DCs in the same city should be less than 2ms, and between remote locations should be less than 5ms. The fewer packet losses, the better.
It would be best if it can be controlled to 1ms.
Still experiencing packet loss… If W megabit network is losing packets, it’s time to call it a day… 
Overall, it can be guaranteed within 1ms, but considering that TiDB is a distributed architecture, especially since PD and TiKV are implemented with RAFT, there is a concern that if one machine experiences network issues, it could affect the performance of the entire cluster.
It seems that network monitoring in this area needs to be done by having each physical machine periodically ping each other to check for delays and determine if there are any anomalies.
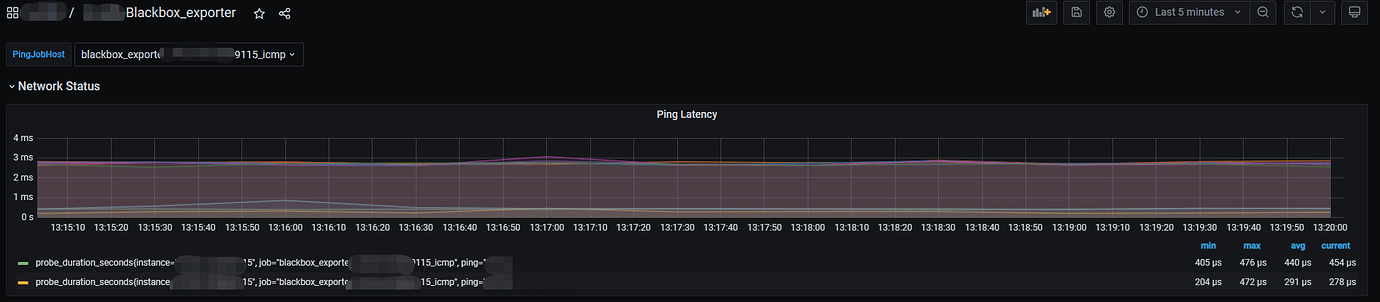
The main issue is that you don’t use Grafana; otherwise, this graph would already be available. In Grafana, there is a Blackbox_exporter. This includes the latency between any server and other servers within the cluster.
Best practice experience from the expert
Is this the server pinging others or other servers pinging this one for latency?
Typically within a few milliseconds, network packet loss can increase network bandwidth. Use 10 Gigabit Ethernet to minimize it as much as possible.
Latency within the same data center is less than 0.5ms, within the same city across multiple data centers is less than 2ms, and across different cities is less than 5ms, for reference only.
This reply is very professional 
Both.
You can select the host to ping from above.
The chart shows the latency to each machine within the cluster.
So it is mesh and bidirectional. You can observe the ping values from any host to other machines within the cluster.
My TiFlash and TiKV are not in the same subnet. You can see there is some latency.
Which monitoring metric is this in? Is it available in version v6.1.7?
First, you need to have the blackbox_exporter process running on each machine.
Then, look for it in the targets.
Once you find it, click on it to open.
Found it. With this monitoring, we can identify the network latency issue.
It should be considered in conjunction with network traffic. Using ping to measure network latency can only give a rough estimate, as ping has a relatively low priority and may not be very accurate. The best approach is to use db.ping, which operates over the TCP protocol with a higher priority and is more accurate, although it is not available on the monitoring panel. During high network traffic, ping latency might be higher, but the actual delay may not be as significant, so a comprehensive analysis is needed.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.