Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: TiDB 论文引发的 HTAP 数据库再思考
Why Reconsider?
Hello everyone, I am Afu. Previously, I shared a paper from the Greenplum team published at SIGMOD 2021 during the community Paper Reading event: “Greenplum: A Hybrid Database for Transactional and Analytical Workloads” - Paper Reading 更新 | 看看大家都在读哪些 Paper ? - TiDB 的问答社区 (see this post for details).

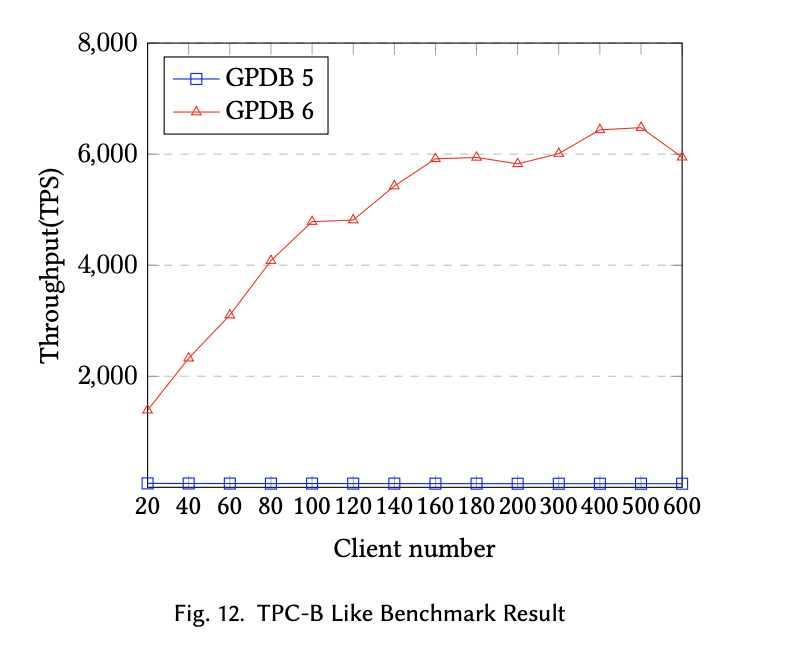
This paper addresses the high-cost computing issues in traditional analytical database products (OLAP RDBMS) like Greenplum in TP scenarios, such as “distributed lock issues,” “resource isolation issues,” and “high cost of two-phase commit,” to create an HTAP database that primarily focuses on OLAP capabilities while also accommodating OLTP scenarios. Overall, the team’s approach is to minimize the impact of analytical scenarios on transactional scenarios in a distributed environment by allocating available resources to handle some transactional processing scenarios. After a series of improvements, the performance of GPDB 6 has significantly improved in mixed transaction and update scenarios compared to GPDB 5, as shown in the comparison test charts below.
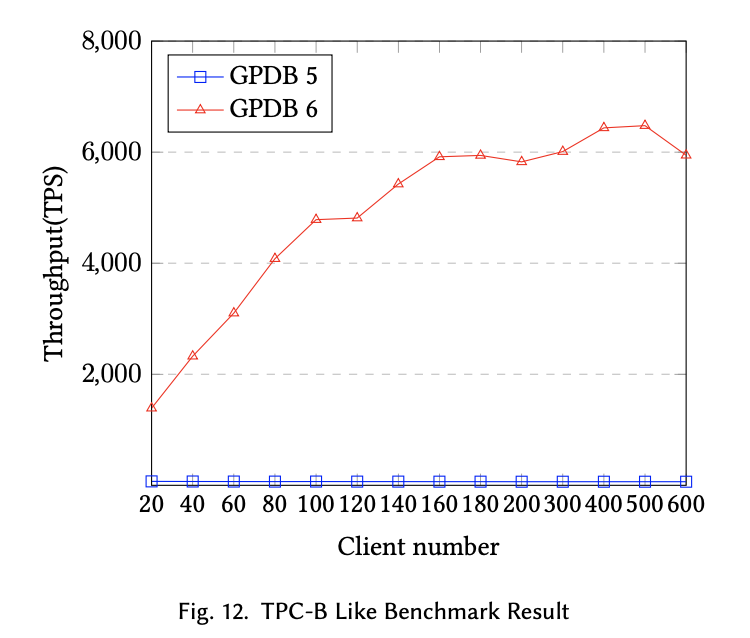
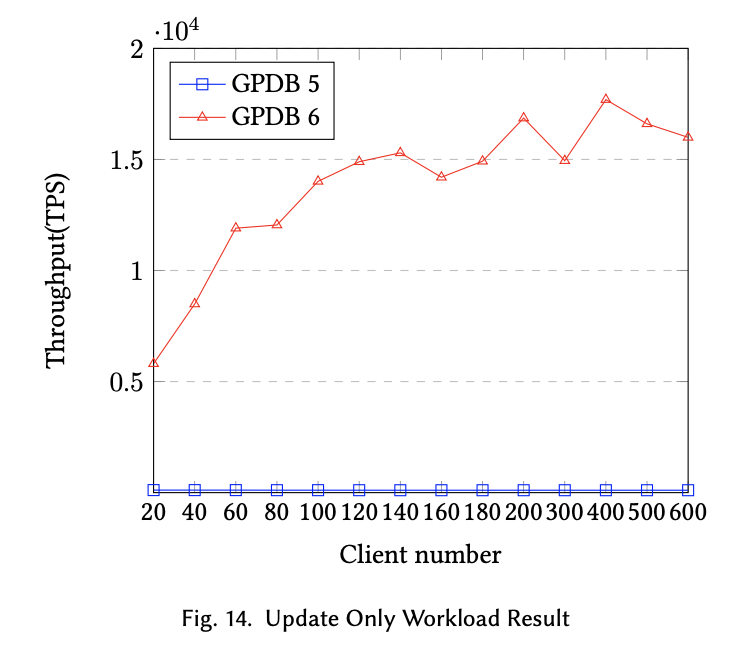
In the HTAP track,
- Besides the evolution of traditional analytical database products like Greenplum towards HTAP,
- There are also evolutions like TiDB from NewSQL’s high TP support scenarios towards HTAP,
In the same track, there are also
- TP/AP separation
- Unified TP+AP processing
Different handling schemes. There are many implementation methods, and their advantages and disadvantages are widely debated.
Shakespeare said: “There are a thousand Hamlets in a thousand people’s eyes.” I am not an opinion leader; my views may not be correct, but they can certainly resonate. Since my last sharing, I have received some feedback from friends, including that the time was too short, the content was not exciting enough, and there were no vivid examples, making the learning content seem limited. Overall, it may be due to my limited understanding of HTAP, but that’s okay; we still have time and opportunities, right? So recently, I have been carefully studying TiDB’s paper “TiDB: A Raft-based HTAP Database,” and in my spare time, I have seen different understandings of HTAP in the community. I hope to have the opportunity to share my understanding of these two different HTAP evolution methods with everyone. Whether it’s TiDB or GP, they are both excellent products, and I hope everyone enjoys using them.
My Views
If you haven’t read TiDB’s paper in detail, you can refer to the following content to catch up:
- TiDB Paper - 《A Raft-based HTAP Database》 - 道客巴巴
- Paper Interpretation 1 - [Paper Reading] TiDB: A Raft-based HTAP Database-CSDN博客
- Paper Interpretation 2 - TiDB: A Raft-based HTAP Database》论文解读-阿里云开发者社区
From my perspective, I mainly want to share from the following aspects.
1. Thoughts on TiDB Architecture
In terms of architecture, TiDB was born to solve some problems encountered by single-machine databases (OLTP), so the overall design considers high concurrency and distributed scalability. Unlike Greenplum, which was born for analysis and cannot support high concurrency. So the problems faced by everyone are different, for example:
1) Different overall approaches to handling HTAP
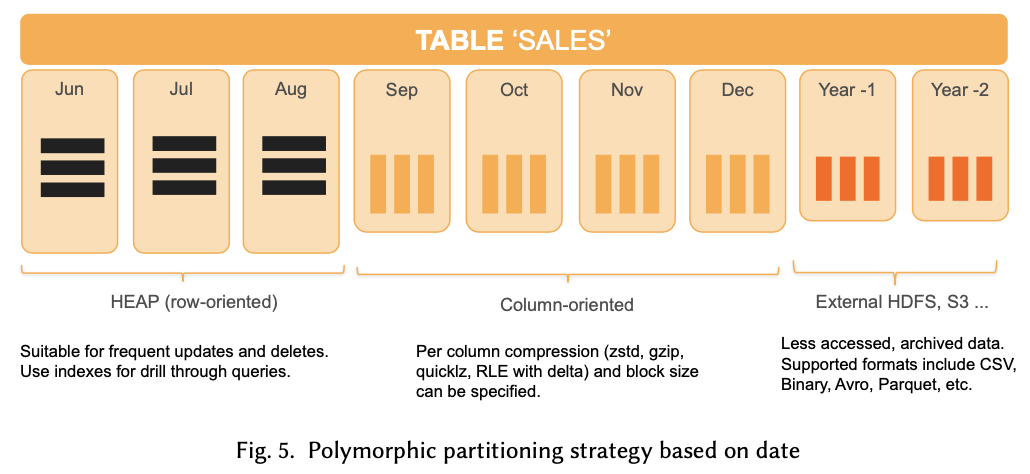
Greenplum involves modifying the current storage engine. In fact, GP considered some scenarios of frequent updates and deletions in analytical scenarios from the beginning, so it has always retained HEAP and AO tables. However, the lock mechanism and resource isolation of HEAP tables were not very friendly. The current evolution towards HTAP mainly focuses on optimizing heap tables to solve some issues with TP support. After optimization, GPDB 6 still requires users to plan ahead in database model design. For analytical scenarios, AO tables with columnar compression are more efficient, while heap tables are recommended for transactional scenarios. This also raises some issues, the main one being that the same table cannot provide the best TP and AP capabilities simultaneously (compared to AO tables). Below is a multi-partition model of a partitioned table ‘SALES’. Although multiple storage technologies are used, there is still only one storage format for the same data. Some may argue that real data is also divided by heat, with hot data using HEAP, warm data using AO, and cold data stored in HDFS. This is a processing method we often guide customers to adopt. For this data division method, the database itself has no control and requires business rule intrusion. This is something to consider when selecting a product.
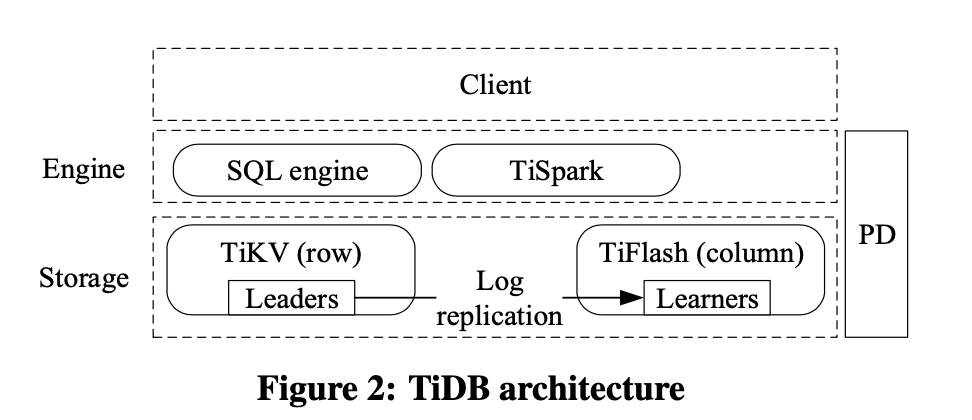
TiDB involves adding an analytical storage engine TiFlash to the original architecture. Since TiKV, based on RocksDB, has been verified over many years and can handle transactional scenarios well, the current task is to extend OLAP capabilities on a stable existing architecture. The team still adopts the same approach as TiKV, reusing the capabilities of another dark horse software in the analytical field, ClickHouse, without reinventing the wheel. CK is well-known for its performance in single-table analysis scenarios, outperforming traditional analytical engines. The advantage of this approach is evident: maintaining overall architectural integrity and stability while reusing industry-verified mature products is friendly for productization and iteration. Additionally, the architecture allows flexible addition of TiFlash. Of course, this also introduces some issues. I believe the main ones are: how to effectively handle and distribute TP and AP queries at the TiDB Server layer, and the cost of introducing an additional columnar storage data redundancy at the storage layer. Data redundancy is also a key point to consider when selecting a product.
In summary: Different architectures lead to different handling approaches. Comparing them, can we say which is better? I can’t say; it’s up to everyone to judge. I personally believe that different business pain points lead to different product selections. No product can excel in both TP and AP; it depends on which aspect you prioritize more.
2) Different replica handling methods
The following points are detailed discussions under the overall framework. For example, let’s talk about replica handling methods.
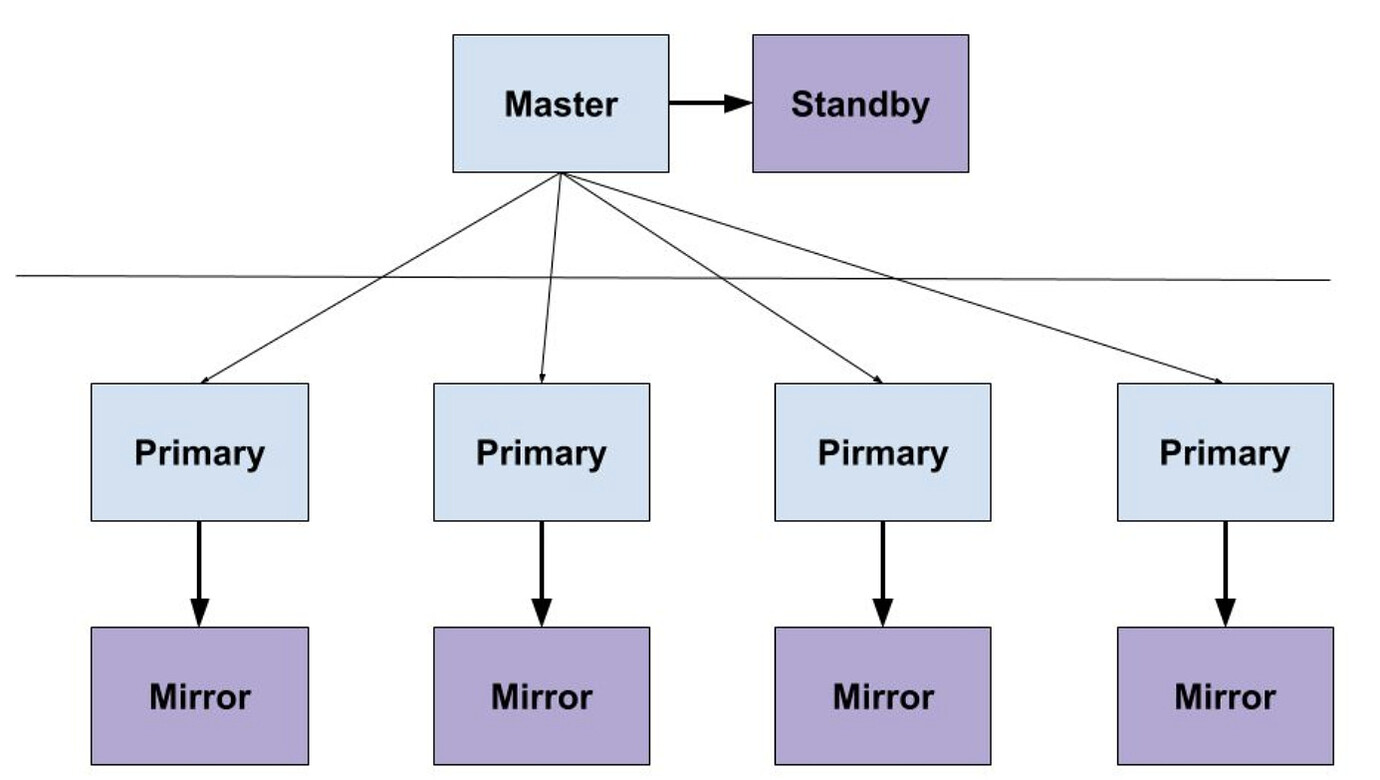
GP uses the most basic WAL log-based synchronization method from PostgreSQL, writing logs to a mirror node to form a Mirror data. Mirror data is hot standby and cannot provide read-only capability. This means all read and write requests can only be handled on the primary replica, which is quite stressful. Therefore, in the HTAP process, the current focus is on reducing lock contention and downgrading two-phase commit to one-phase commit to reduce TP transaction costs. In future versions, WAL log synchronization interfaces will be released, allowing multi-replica implementation. This way, read requests can be split to another cluster (with application read-write separation).
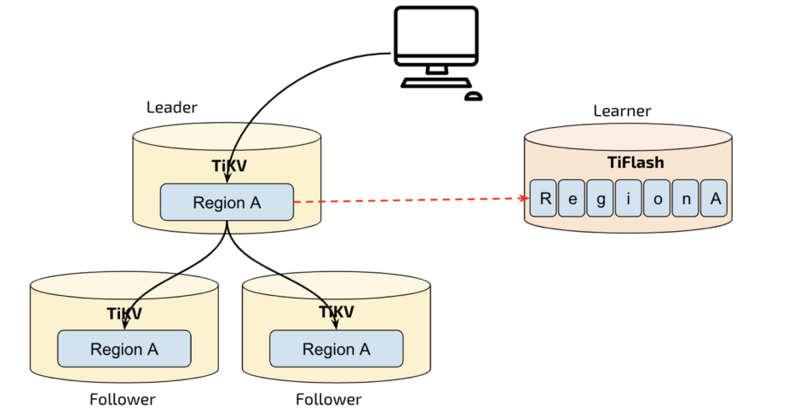
TiDB uses the Raft consensus protocol, requiring at least 3 replicas to reach consensus. TiDB’s overall architecture allows flexible read-write separation and easy multi-center deployment and disaster recovery, making it more HTAP-friendly. To support analytical scenarios, adding TiFlash means 4 replicas, as TiFlash can only join as a Learner. Additionally, the columnar engine introduces data synchronization and row-column conversion costs, which are addressed in the paper. You can read the details in the paper.
In summary: Different architectures lead to different replica handling methods. They follow different paths and don’t need forced comparisons. Just understand their different starting points.
3) Different SQL processing methods
In this aspect, GP has nothing much to discuss. A SQL query from the Master node has only one storage path for a table. Simply put, the table is queried as it is built.
However, TiDB is interesting. With TiFlash enabled, a SQL query from TiDB first determines the best path, whether TiKV or TiFlash. This introduces an uncertainty: if the cost estimation is incorrect, the query may take the wrong path, reducing efficiency. For example, an analytical query might go to TiKV, affecting existing TP business. This concern is common, especially in critical business scenarios. No one wants this to happen.
From TiDB’s perspective, the advantage is that TiDB is doing it, not some unknown company. TiDB’s community openness and participation are well-recognized. This means that with extensive experience and production validation, the probability of errors is much lower, and issues are resolved faster. There are many ways to intervene in errors, such as adding HINTs and fuse parameters to minimize the impact on overall business.
HTAP in Everyone’s Eyes
Finally, I want to thank everyone for patiently reading my post and views. My views may be limited by my knowledge and somewhat one-sided.
For those interested in HTAP or TiDB, stay tuned for future shares. Let’s discuss our views on HTAP together.