Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 关于TiSpark的几种使用方式以及常见错误
Several Usage Methods
Recently, many friends have had some questions about using TiSpark. Here are some usage demos for writing to TiKV using TiSpark, recommended in order of maturity (not write efficiency). The version is TiSpark 3.0.0+Spark 3.0.X:
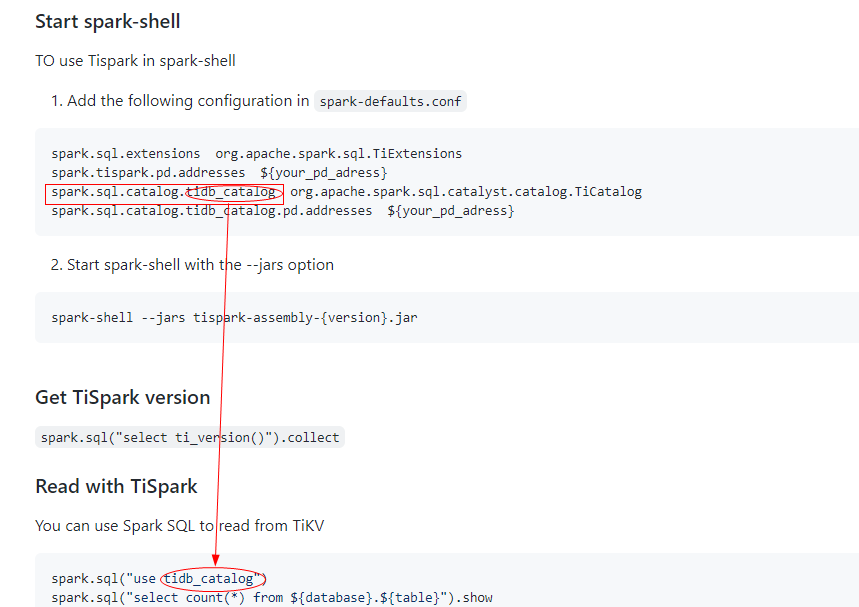
Basic Configuration:
SparkConf conf = new SparkConf()
.set("spark.sql.extensions", "org.apache.spark.sql.TiExtensions")
.set("spark.sql.catalog.tidb_catalog", "org.apache.spark.sql.catalyst.catalog.TiCatalog")
.set("spark.sql.catalog.tidb_catalog.pd.addresses", pd_addr)
.set("spark.tispark.pd.addresses", pd_addr);
Recommendation 1:
spark.sql("use "+source_db_name);
String source_sql = "select * from "+source_table_name;
spark.sql(source_sql)
.repartition(20)
.write()
.mode(SaveMode.Append)
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// replace the host and port with yours and be sure to use rewrite batch
.option("url", "jdbc:mysql://"+t_tidb_addr+":4000/"+target_db_name+"?rewriteBatchedStatements=true")
.option("useSSL", "false")
// as tested, setting to `150` is a good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE(), 150)
// database name and table name here
.option("dbtable", target_table_name)
// set isolationLevel to NONE
.option("isolationLevel", "NONE")
// TiDB user here
.option("user", t_username)
.option("password", t_password)
.save();
Recommendation 2:
Map<String, String> tiOptionMap = new HashMap<String, String>();
tiOptionMap.put("tidb.addr", tidb_addr);
tiOptionMap.put("tidb.port", "4000");
tiOptionMap.put("tidb.user", username);
tiOptionMap.put("tidb.password", password);
tiOptionMap.put("replace", "true");
tiOptionMap.put("spark.tispark.pd.addresses", pd_addr);
spark.sql(source_sql)
.write()
.format("tidb")
.options(tiOptionMap)
.option("database", target_db_name)
.option("table", target_table_name)
.mode(SaveMode.Append)
.save();
Recommendation 3:
String source_sql = "select * from "+source_db_name+"."+source_table_name;
String create_table = "create table target_"+target_table_name+" using tidb options (\
" +
"tidb.user '"+username+"',\
" +
"tidb.password '"+password+"',\
" +
"tidb.addr '"+tidb_addr+"',\
" +
"tidb.port '4000',\
" +
"database '"+target_db_name+"',\
" +
"table '"+target_table_name+"'\
" +
")";
String insert_sql = "INSERT INTO target_"+target_table_name+" "+source_sql;
Among them, Recommendation 1 and Recommendation 2 have been tested and have similar efficiency. Theoretically, Recommendation 2 is slightly faster, but it may have some compatibility issues that need to be resolved as they arise. Recommendation 3, based on current information, has a risk of type conversion errors and should be used with caution.
Common Errors
Recently, some common issues have been found in the forum, most of which are false alarms and do not affect the operation of TiSpark. Here are some examples:
- ANTLR Tool version 4.8 used for code generation does not match the current runtime version 4.7.1ANTLR Runtime version 4.8 used for parser compilation does not match the current runtime version 4.7.122/07/27
Reason: Spark 3.1.x references org.antlr:antlr4-runtime:4.8-1 during compilation, while tispark-assembly-3.1_2.12-3.0.1.jar uses tikv-client, which uses org.antlr:antlr4-runtime:4.7. Therefore, it is likely that tispark-assembly-3.1_2.12-3.0.1.jar references org.antlr:antlr4-runtime:4.7.
Impact: This is just a warning and has no clear impact on operation.
Avoidance: Use Spark 3.0.X to avoid this error. - Failed to get PD version For input string: “2379,XXX.XXX.XXX.XXX:23379,XXX.XXX.XXX.XXX:2379”
Reason: This is a bug. Whenever multiple addresses are configured while maintaining PD addresses, this warning will appear. This bug has been fixed: Fix: exception when the size of pdAddresse is > 1 by xuanyu66 · Pull Request #2473 · pingcap/tispark · GitHub
Impact: This error is only related to telemetry and does not affect the main process.
Avoidance: Disable telemetry by setting the parameterspark.tispark.telemetry.enable = false.
https://tidb.net/book/tidb-monthly/2022-06/update/tispark-3-0-0#新特性 - Database ‘test’ not Found
Reason: This mostly occurs after upgrading from Spark 2.X to Spark 3.X because Spark 3.X uses Catalog, and the schema name composition has changed when reading tables, as shown in the figure below:
Impact: Unable to correctly read the database.
Avoidance: Modify the SQL statement to use the correct method.