Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 使用explain analyze连续多次执行同一条sql执行时间差距很大
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] 5.7
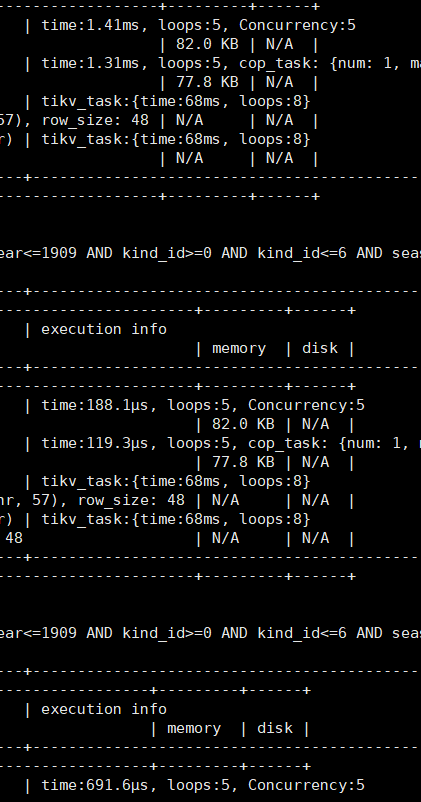
[Encountered Problem] As mentioned, executing the same SQL multiple times consecutively on a single TiDB (with the same execution plan) results in significantly varying execution times (sometimes 10ms, sometimes 100-200μs), with a few executions having smaller differences. I want to optimize the query plan, but such large differences in execution times make it difficult to evaluate the effectiveness of my optimizations… I wonder if it’s due to caching? Is there any way to achieve more stable execution times (with minimal differences when executing the same SQL multiple times)?
[Reproduction Path] Execute the same SQL multiple times consecutively after running analyze table
[Problem Phenomenon and Impact]
[Attachment]
Please provide the version information of each component, such as cdc/tikv, which can be obtained by executing cdc version/tikv-server --version.
It should be that the first execution generates more disk reads. You can check the execution information of the slow SQL records in the dashboard.
Sorry, it’s 5.3.0, I made a typo while typing.
Is there a way to make TiDB not use the cache, or to always read from the disk each time?
Try using SQL_CACHE and SQL_NO_CACHE to see if the request results are cached in TiKV (RocksDB) BlockCache. For one-time large data queries, such as count(*) queries, it is recommended to use SQL_NO_CACHE to avoid evicting hot data from the BlockCache.
The best way is to use caching~
Check the difference between the execution plan (explain sql) and the actual execution result (explain analyze sql), and then make some adjustments.
Using cache is much faster; disks are very slow. Also, what type of disk is it?
What is the complete query statement? If the output result can be fully accommodated in memory, theoretically only the first time will involve disk read.
I want to ask, I always use the same SQL, but the parameters are different each time. Each time it goes to the KV store to fetch data, right? It won’t fetch data from the KV store just because it’s the same SQL but with different conditions (e.g., time conditions: the first time is from 2021-01-01 to 2021-01-01 23:59:59, the second time is from 2021-01-02 to 2021-01-02 23:59:59. So each time it fetches data from the KV store).