Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 单行记录update锁冲突
[TiDB Usage Environment] Production Environment
[TiDB Version] 5.3.2
[Encountered Problem] Slow queries show some updates taking around 50 seconds, but only updating one row of data.
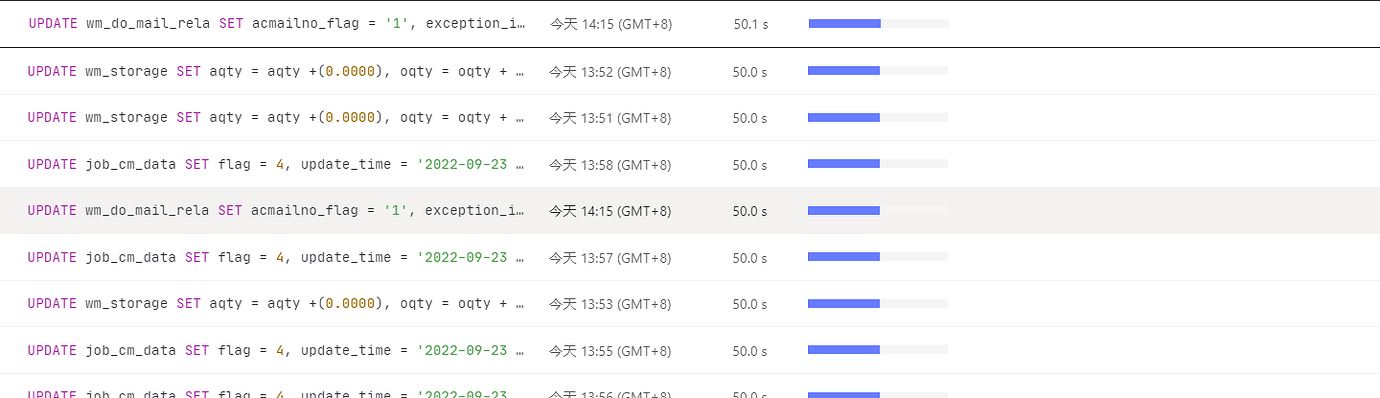

id task estRows operator info actRows execution info memory disk
Update_5 root 0 N/A 0 time:50s, loops:1, , lock_keys: {time:50s, region:1, keys:1, resolve_lock:75.1ms, lock_rpc:49.925128827s, rpc_count:50} 0 Bytes N/A
└─Point_Get_1 root 1 table:wm_do_mail_rela, index:PRIMARY(id), lock 0 time:50s, loops:1, Get:{num_rpc:1, total_time:676.3µs}, scan_detail: {total_process_keys: 1, total_process_keys_size: 44, total_keys: 1, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 10, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
[Confirmed many deadlocks]
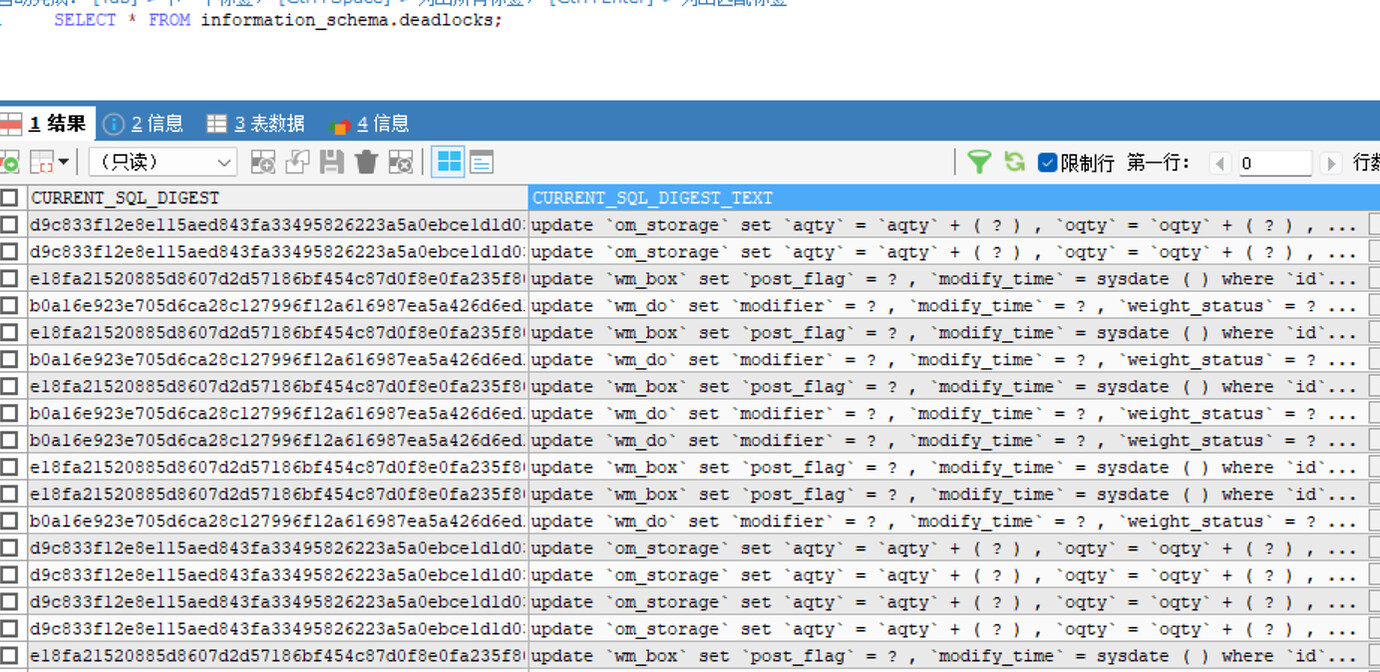
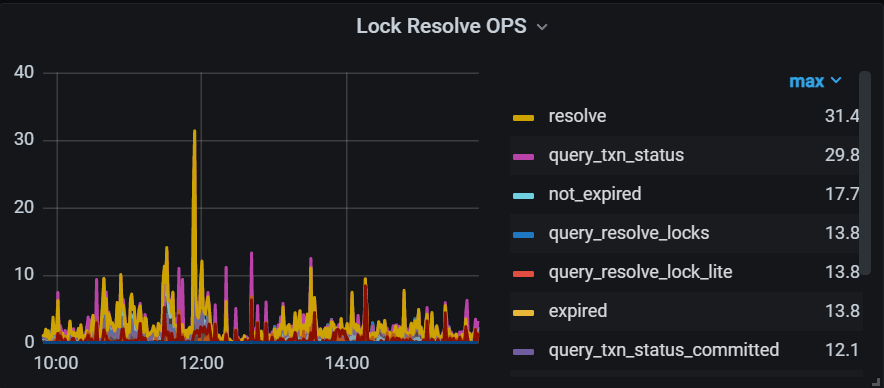
[Problem Phenomenon and Impact]
Found in the documentation that the pessimistic lock conflict unlock time is 50 seconds.
Due to business reasons, the isolation level was adjusted to RC.
However, it is not quite understandable why modifying a single row can lock each other. Is this normal? How to solve it?
Another example

id task estRows operator info actRows execution info memory disk
Update_5 root 0 N/A 0 time:50s, loops:1, , lock_keys: {time:50s, region:1, keys:1, resolve_lock:9.9ms, backoff: {time: 8.01s, type: [regionMiss]}, lock_rpc:41.967862323s, rpc_count:65} 19.0 KB N/A
└─SelectLock_7 root 0.07 for update 0 1 time:50s, loops:2 N/A N/A
└─IndexLookUp_11 root 0.07 1 time:1.26ms, loops:2, index_task: {total_time: 310.7µs, fetch_handle: 305.9µs, build: 762ns, wait: 4.04µs}, table_task: {total_time: 883.4µs, num: 1, concurrency: 5} 27.0 KB N/A
├─IndexRangeScan_8 cop[tikv] 1.00 table:wm_storage, index:PRIMARY(id), range:[166202640534311911,166202640534311911], keep order:false 1 time:301.3µs, loops:3, cop_task: {num: 1, max: 254.1µs, proc_keys: 1, rpc_num: 1, rpc_time: 237.9µs, copr_cache_hit_ratio: 0.00}, tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 1, total_process_keys_size: 44, total_keys: 1, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 8, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
└─Selection_10 cop[tikv] 0.07 ge(k3_wms.wm_storage.aqty, 0.0000), ge(k3_wms.wm_storage.iqty, 0.0000), ge(k3_wms.wm_storage.oqty, 1.0000) 1 time:554.1µs, loops:2, cop_task: {num: 1, max: 496µs, proc_keys: 1, rpc_num: 1, rpc_time: 490µs, copr_cache_hit_ratio: 0.00}, tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 1, total_process_keys_size: 282, total_keys: 1, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 9, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
└─TableRowIDScan_9 cop[tikv] 1.00 table:wm_storage, keep order:false 1 tikv_task:{time:0s, loops:1} N/A N/A