Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 慢查询 大文本字段longtext查询问题
[TiDB Usage Environment] Testing
[TiDB Version] V7.1.2
[Reproduction Path]
Table T TS_DOCKPF_RECORD Data Volume: 5581 rows Table T1 TS_DOCKPF Data Volume: 22 rows
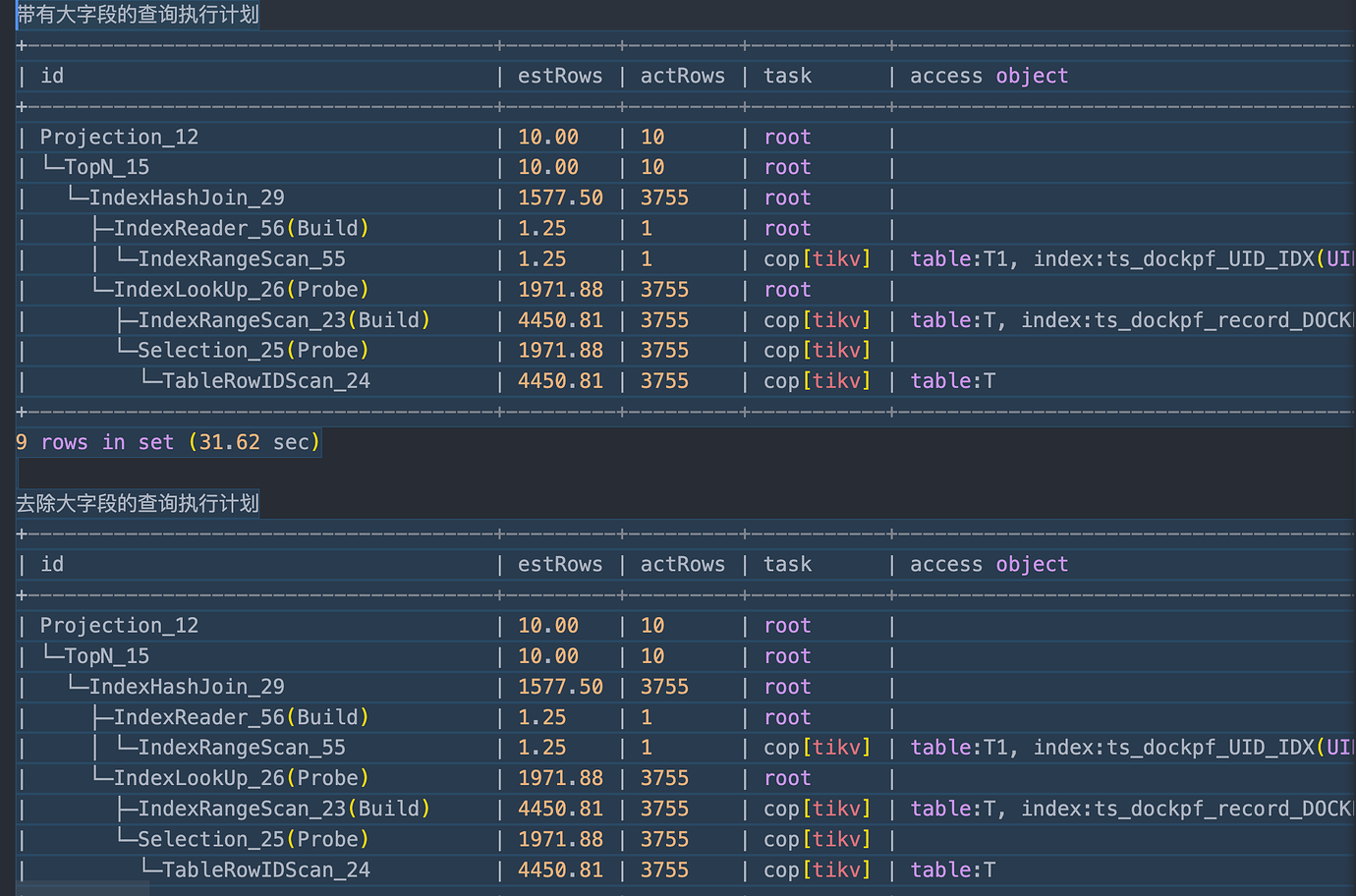
In table T, the fields RECORD_REQ and RECORD_RES are of longtext type. The content stored in these two fields for each row is approximately 180kb.
Executing the following SQL:
EXPLAIN ANALYZE SELECT
T.DOCKPF_ID AS “fkByDockpfId.rid”,
T.BUS_TYPE AS busType,
T.RECORD_UID AS recordUid,
T.RECORD_REQ AS recordReq,
** T.RECORD_RES AS recordRes,**
T.DOCK_CONTENT AS dockContent,
T.RECORD_STATE AS recordState,
T.RECORD_TIME AS recordTime,
T.RID AS rid,
T.IF_DELETE AS ifDelete
FROM
TS_DOCKPF_RECORD T
LEFT JOIN TS_DOCKPF T1 ON T1.RID = T.DOCKPF_ID
WHERE
T1.UID = ‘78AA82AA0C01474C88238161234567890’
AND T.BUS_TYPE = 31
AND T.RECORD_STATE = 0
AND T.IF_DELETE = 0
ORDER BY
T.MODIFY_TIME ASC,
T.RID ASC
LIMIT
10;
Execution time: 30s+
If the two large fields are removed from the query result fields, the SQL is as follows:
EXPLAIN ANALYZE SELECT
T.DOCKPF_ID AS “fkByDockpfId.rid”,
T.BUS_TYPE AS busType,
T.RECORD_UID AS recordUid,
T.DOCK_CONTENT AS dockContent,
T.RECORD_STATE AS recordState,
T.RECORD_TIME AS recordTime,
T.RID AS rid,
T.IF_DELETE AS ifDelete
FROM
TS_DOCKPF_RECORD T
LEFT JOIN TS_DOCKPF T1 ON T1.RID = T.DOCKPF_ID
WHERE
T1.UID = ‘78AA82AA0C01474C88238161234567890’
AND T.BUS_TYPE = 31
AND T.RECORD_STATE = 0
AND T.IF_DELETE = 0
ORDER BY
T.MODIFY_TIME ASC,
T.RID ASC
LIMIT
10;
Execution time: 30ms
Execution plans for both queries
bbb.sql (27.2 KB)
For the long execution time of such large field queries, could the experts please advise on how to optimize?