Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 关于热点问题的解决-SHARD_ROW_ID_BITS
[TiDB Usage Environment] Test
[TiDB Version] 5.4
[Problem Encountered] How to disperse hotspots in tables with primary keys? Non-clustered index tables can directly set the SHARD_ROW_ID_BITS parameter, but if the table itself has a primary key, it cannot be set. How to solve this?
[Reproduction Path]
mysql> CREATE TABLE t (a BIGINT PRIMARY KEY AUTO_RANDOM, b varchar(255) ) SHARD_ROW_ID_BITS = 4;
ERROR 8200 (HY000): Unsupported shard_row_id_bits for table with primary key as row id
[Problem Phenomenon and Impact]
All tables in the business have primary keys. Does this mean that hotspots cannot be resolved?
[Attachment]
AUTO_RANDOM itself is already scattered.
Thank you, everyone. If hotspots still occur after sharding, how can we resolve them?
Did you still encounter hotspots when using AUTO_RANDOM?
I mean, hypothetically, if it happens again, should we continue to break it up? If we continue to break it up, how should we do it? Because currently, there is a business considering using TiDB to replace MySQL, and I need to take some situations into account in advance.
AUTO_RANDOM itself is random. If it can still generate hotspots, the system pressure must be quite high. Consider adding more nodes.
Alright, it seems that’s the only way. At least I know what to do when a certain situation occurs. Thank you.
Another possibility is that a large number of requests frequently query a small table, forming a hotspot in a single Region. You can manually split the region or consider using the caching table feature in version 6.0 to optimize.
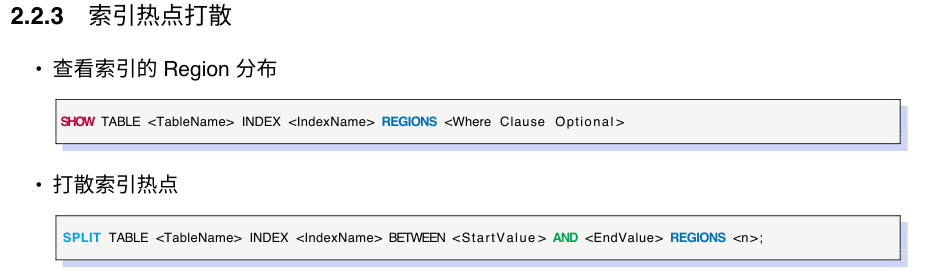
Thank you. Could you provide a document link for manually splitting regions so I can study it?
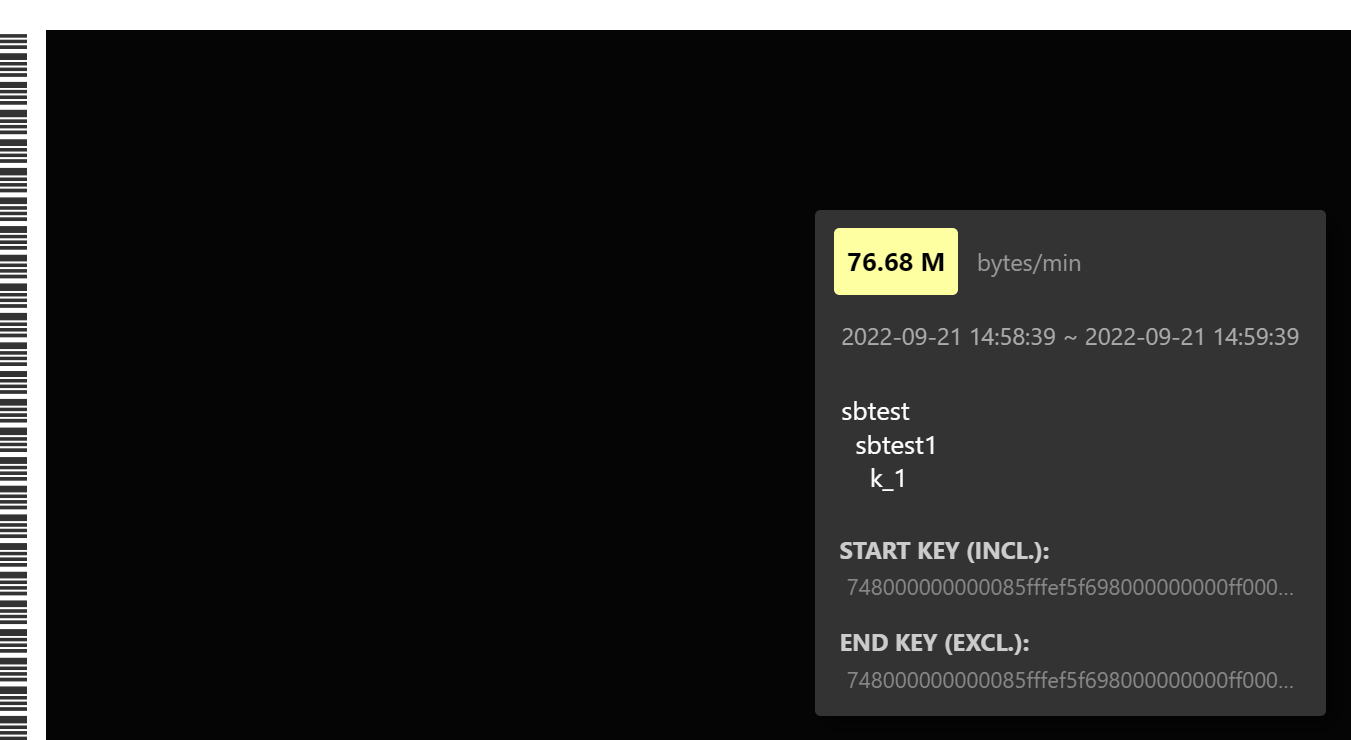
By the way, if a heatmap shows that an index has become a hotspot, what should be done? The index is a non-clustered index, for example:
The official TiDB documentation has a dedicated section on handling hotspot issues. If these methods cannot solve your problem, you might consider choosing other technologies, such as Redis.
Check out the usage of pd-ctl
By using AUTO_RANDOM, the primary key read and write operations on the table have been dispersed, so hotspots will not occur. However, if a secondary index is created in the table, high concurrency might cause the secondary index to form hotspots. You can continue to disperse the index.
If an index is created on a date field (with date precision to the day or hour), will such a secondary index easily cause hotspots under high concurrency?
Index hotspots typically occur when data is inserted into monotonically increasing fields at the same time, or when a large number of duplicate values are inserted simultaneously. Here, index hotspots refer to indexes on monotonically increasing fields or duplicate value fields.
Based on the KV mapping principle of indexes, it can be understood that:
-
The index key structure in the primary key or unique index of a non-clustered table is: TableID_IndexID_IndexColumnValue. When data is batch inserted into a monotonically increasing field at the same time, the index key will inevitably be continuous and will be written into a single Region, forming a write hotspot. Therefore, if the date field in your batch insert data is an automatically obtained value like now(), it will create a hotspot.
-
The key structure of a regular secondary index is: TableID_IndexID_IndexColumnValue_TableRowID. If a large number of duplicate values are inserted at the same time, it will also create a write hotspot.
auto_random cannot guarantee orderliness, please take note of this.