Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 【SOP 系列 40 】TiDB Operator部署TiDB集群的监控与告警
I. Creating Monitoring and Alerts
1.1. Create PV Directory
[root@k8s-node2 disks]# for i in `seq 9`; do mkdir -p /home/data/pv0$i; done
[root@k8s-node2 disks]# ll /home/data/pv0
pv01/ pv02/ pv03/ pv04/ pv05/ pv06/ pv07/ pv08/ pv09/
1.2. Batch Create Local PV
[root@k8s-master monitoring]#for i in `seq 9`; do
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolume
metadata:
name: tidb-cluster-172-16-4-203-pv0${i}
spec:
capacity:
storage: 50Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage-monitoring
local:
path: /home/data/pv0${i}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node2
EOF
done
persistentvolume/tidb-cluster-172-16-4-203-pv01 created
persistentvolume/tidb-cluster-172-16-4-203-pv02 created
persistentvolume/tidb-cluster-172-16-4-203-pv03 created
persistentvolume/tidb-cluster-172-16-4-203-pv04 created
persistentvolume/tidb-cluster-172-16-4-203-pv05 created
persistentvolume/tidb-cluster-172-16-4-203-pv06 created
persistentvolume/tidb-cluster-172-16-4-203-pv07 created
persistentvolume/tidb-cluster-172-16-4-203-pv08 created
persistentvolume/tidb-cluster-172-16-4-203-pv09 created
1.3. Check PV Status
[root@k8s-master monitoring]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
tidb-cluster-172-16-4-203-pv01 50Gi RWO Delete Available local-storage-monitoring 48s
tidb-cluster-172-16-4-203-pv02 50Gi RWO Delete Available local-storage-monitoring 48s
tidb-cluster-172-16-4-203-pv03 50Gi RWO Delete Available local-storage-monitoring 47s
tidb-cluster-172-16-4-203-pv04 50Gi RWO Delete Available local-storage-monitoring 47s
tidb-cluster-172-16-4-203-pv05 50Gi RWO Delete Available local-storage-monitoring 47s
tidb-cluster-172-16-4-203-pv06 50Gi RWO Delete Available local-storage-monitoring 46s
tidb-cluster-172-16-4-203-pv07 50Gi RWO Delete Available local-storage-monitoring 46s
tidb-cluster-172-16-4-203-pv08 50Gi RWO Delete Available local-storage-monitoring 46s
tidb-cluster-172-16-4-203-pv09 50Gi RWO Delete Available local-storage-monitoring 46s
1.4. Create Monitoring Data YAML File
[root@k8s-master monitoring]# cat operator-monitoring.yaml
apiVersion: pingcap.com/v1alpha1
kind: TidbMonitor
metadata:
name: basic
spec:
clusters:
- name: mycluster
prometheus:
baseImage: prom/prometheus
version: v2.27.1
logLevel: info
reserveDays: 12
service:
type: NodePort
portName: http-prometheus
grafana:
baseImage: grafana/grafana
version: 7.5.11
logLevel: info
username: admin
password: admin
envs:
GF_AUTH_ANONYMOUS_ENABLED: "true"
GF_AUTH_ANONYMOUS_ORG_NAME: "Main Org."
GF_AUTH_ANONYMOUS_ORG_ROLE: "Viewer"
service:
type: NodePort
portName: http-grafana
initializer:
baseImage: pingcap/tidb-monitor-initializer
version: v6.1.0
reloader:
baseImage: pingcap/tidb-monitor-reloader
version: v1.0.1
service:
type: NodePort
portName: tcp-reloader
prometheusReloader:
baseImage: quay.io/prometheus-operator/prometheus-config-reloader
version: v0.49.0
imagePullPolicy: IfNotPresent
persistent: true
storageClassName: local-storage-monitoring
storage: 10Gi
nodeSelector: {}
annotations: {}
tolerations: []
kubePrometheusURL: http://prometheus-k8s.monitoring.svc:9090
alertmanagerURL: ""
[root@k8s-master monitoring]# kubectl apply -f operator-monitoring.yaml -ntidb
tidbmonitor.pingcap.com/basic created
[root@k8s-master monitoring]# kubectl get pod -ntidb
NAME READY STATUS RESTARTS AGE
basic-monitor-0 3/4 Running 0 9s
mycluster-discovery-58b658b88d-wnqgs 1/1 Running 1 133d
mycluster-pd-0 1/1 Running 0 3h22m
mycluster-pd-1 1/1 Running 0 64m
mycluster-pd-2 1/1 Running 0 64m
mycluster-tidb-0 2/2 Running 0 3h10m
mycluster-tidb-1 2/2 Running 2 81m
mycluster-tidb-2 2/2 Running 0 3h14m
mycluster-tikv-0 1/1 Running 0 3h14m
mycluster-tikv-1 1/1 Running 0 3h16m
mycluster-tikv-2 1/1 Running 0 64m
mycluster-tikv-3 1/1 Running 0 64m
mycluster-tikv-4 1/1 Running 0 64m
mycluster-tikv-5 1/1 Running 0 64m
1.5. Check PVC Status
[root@k8s-master monitoring]# kubectl get pvc -l app.kubernetes.io/instance=basic,app.kubernetes.io/component=monitor -n tidb
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
tidbmonitor-basic-monitor-0 Bound tidb-cluster-172-16-4-203-pv07 50Gi RWO local-storage-monitoring 2m7s
1.6. Check SVC Status
[root@k8s-master monitoring]# kubectl get svc -ntidb
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
basic-grafana NodePort 10.100.15.69 <none> 3000:31886/TCP 12m
basic-monitor-reloader NodePort 10.104.226.145 <none> 9089:30305/TCP 12m
basic-prometheus NodePort 10.96.172.72 <none> 9090:30536/TCP 12m
mycluster-discovery ClusterIP 10.102.101.73 <none> 10261/TCP,10262/TCP 133d
mycluster-pd ClusterIP 10.98.161.169 <none> 2379/TCP 133d
mycluster-pd-peer ClusterIP None <none> 2380/TCP,2379/TCP 133d
mycluster-tidb NodePort 10.109.243.39 <none> 4000:30020/TCP,10080:30040/TCP 133d
mycluster-tidb-peer ClusterIP None <none> 10080/TCP 133d
mycluster-tikv-peer ClusterIP None <none> 20160/TCP 133d
1.7. Access Grafana and Prometheus Control Panel
Method 1: Access via port-forward
[root@k8s-master monitoring]# kubectl port-forward -n tidb svc/basic-grafana 3000:3000 &>/tmp/portforward-grafana.log &
[1] 15143
[root@k8s-master monitoring]# kubectl port-forward -n tidb svc/basic-prometheus-prometheus 9090:9090 &>/tmp/portforward-prometheus.log &
[2] 16015
Method 2: Access via nodePort
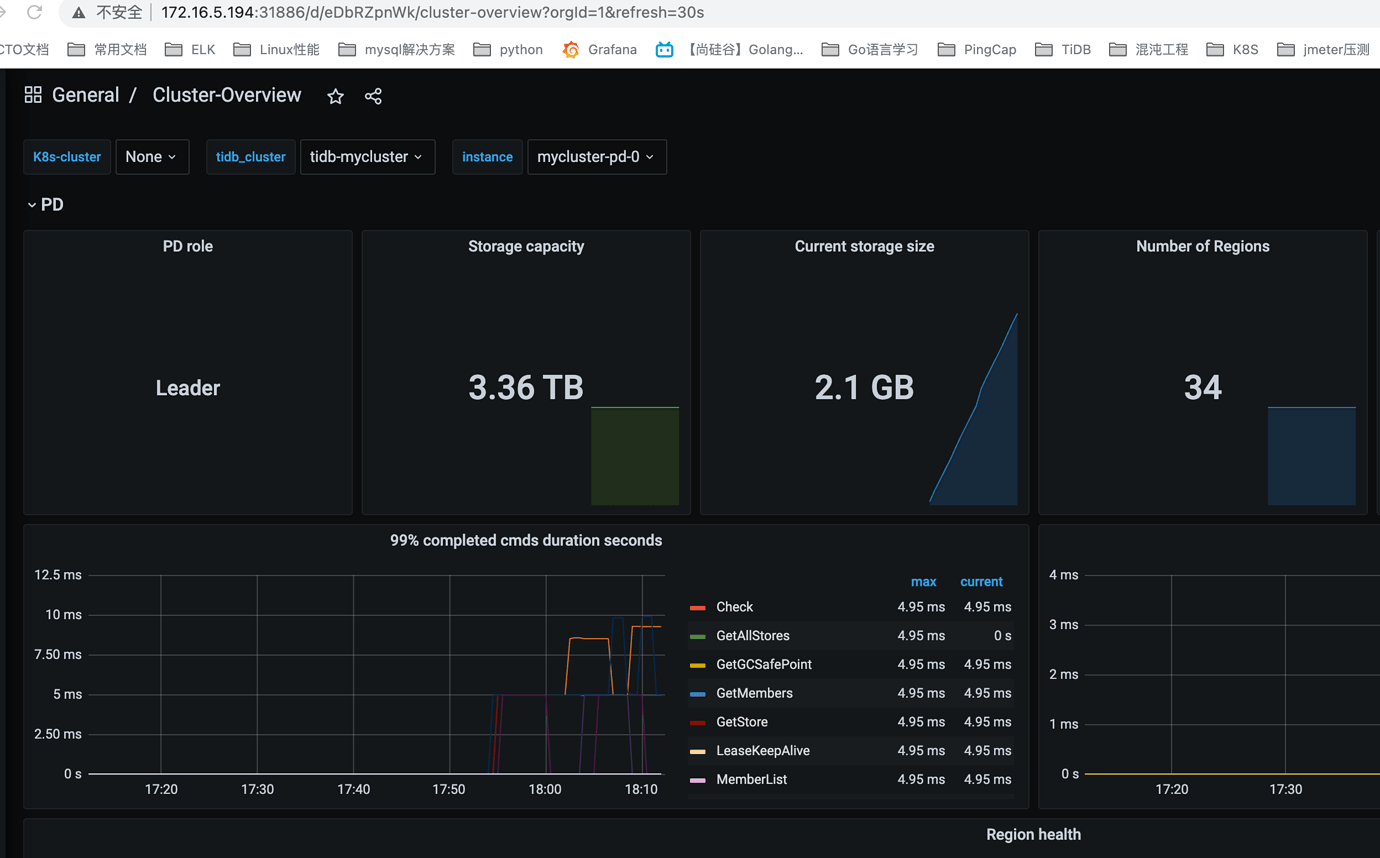
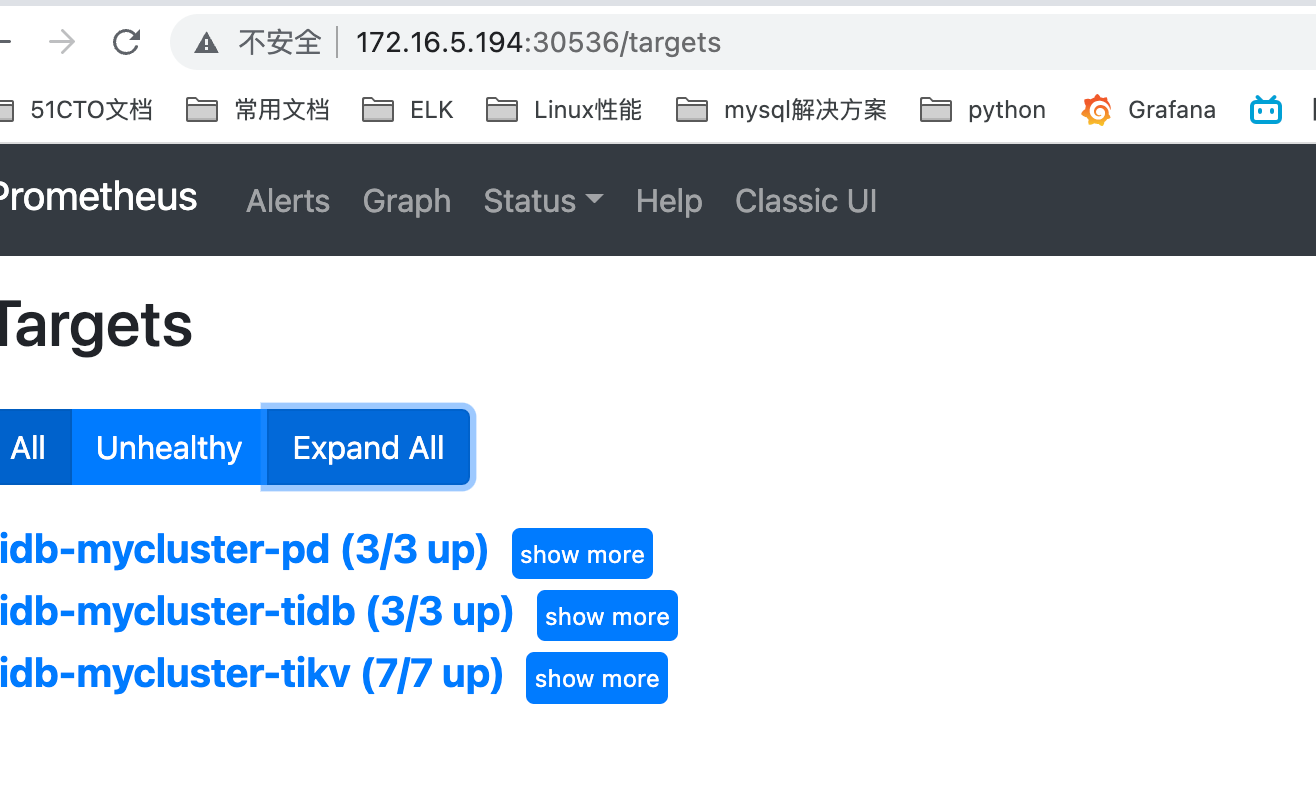
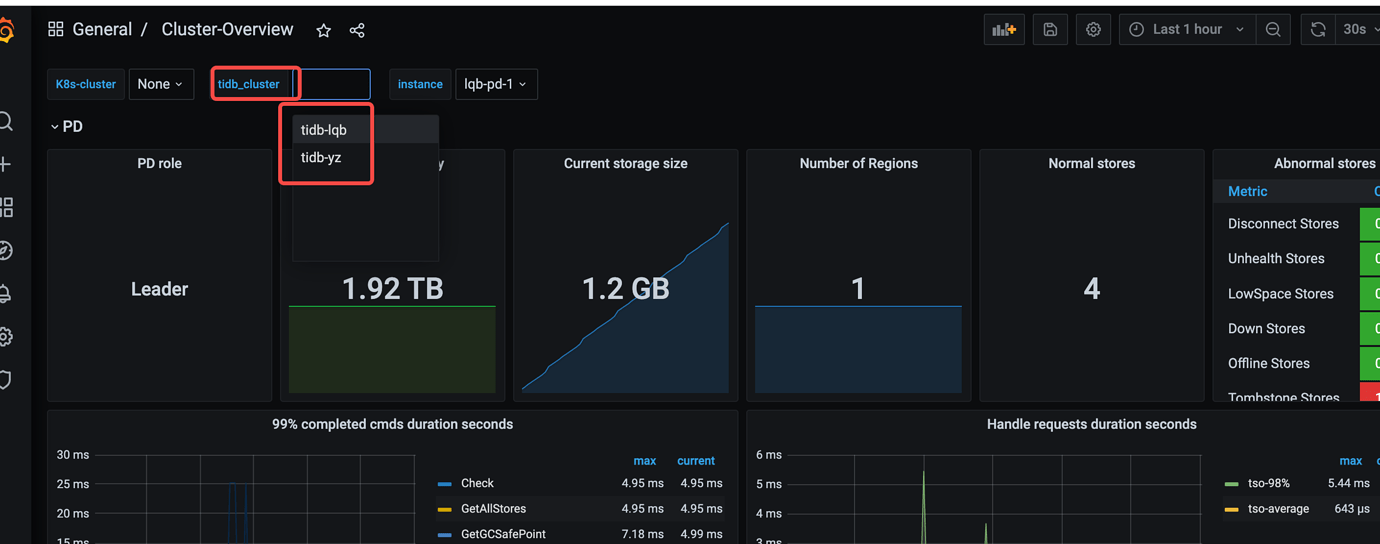
II. Enable Ingress for External Access
2.1. Install Ingress
Please refer to K8S-Ingress Controller
2.2. Enable External Exposure for Prometheus/Grafana Services in TidbMonitor
[root@k8s-master tidb]# cat ingress-monitor.yaml
apiVersion: pingcap.com/v1alpha1
kind: TidbMonitor
metadata:
name: ingress-monitor
namespace: tidb
spec:
clusters:
- name: lqb
persistent: true
storageClassName: local-storage
storage: 45G
prometheus:
baseImage: prom/prometheus
version: v2.27.1
#### Prometheus external exposure configuration via ingress
ingress:
hosts:
- prometheus.mytest.org
grafana:
baseImage: grafana/grafana
version: 7.5.11
### Grafana external exposure configuration via ingress
ingress:
hosts:
- grafana.mytest.org
initializer:
baseImage: pingcap/tidb-monitor-initializer
version: v6.1.0
reloader:
baseImage: pingcap/tidb-monitor-reloader
version: v1.0.1
prometheusReloader:
baseImage: quay.io/prometheus-operator/prometheus-config-reloader
version: v0.49.0
2.3. Apply the Configuration
[root@k8s-master tidb]# kubectl apply -f ingress-monitor.yaml
tidbmonitor.pingcap.com/ingress-monitor created
[root@k8s-master tidb]# kubectl get svc,pod -ntidb
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/access-dashboard NodePort 10.98.67.190 <none> 10262:30836/TCP 15d
service/ingress-monitor-grafana ClusterIP 10.105.79.132 <none> 3000/TCP 29s
service/ingress-monitor-monitor-reloader ClusterIP 10.109.154.169 <none> 9089/TCP 29s
service/ingress-monitor-prometheus ClusterIP 10.105.80.91 <none> 9090/TCP 29s
service/lqb-discovery ClusterIP 10.98.145.163 <none> 10261/TCP,10262/TCP 135m
service/lqb-pd ClusterIP 10.97.247.56 <none> 2379/TCP 135m
service/lqb-pd-peer ClusterIP None <none> 2380/TCP,2379/TCP 135m
service/lqb-tidb NodePort 10.97.69.112 <none> 4000:30022/TCP,10080:30042/TCP 135m
service/lqb-tidb-peer ClusterIP None <none> 10080/TCP 135m
service/lqb-tikv-peer ClusterIP None <none> 20160/TCP 135m
service/monitor-grafana NodePort 10.108.176.207 <none> 3000:31805/TCP 80m
service/monitor-monitor-reloader ClusterIP 10.109.183.102 <none> 9089/TCP 80m
service/monitor-prometheus NodePort 10.107.252.241 <none> 9090:30398/TCP 80m
2.4. Add Hosts Resolution and Access Externally (via ${node_ip}:${NodePort})
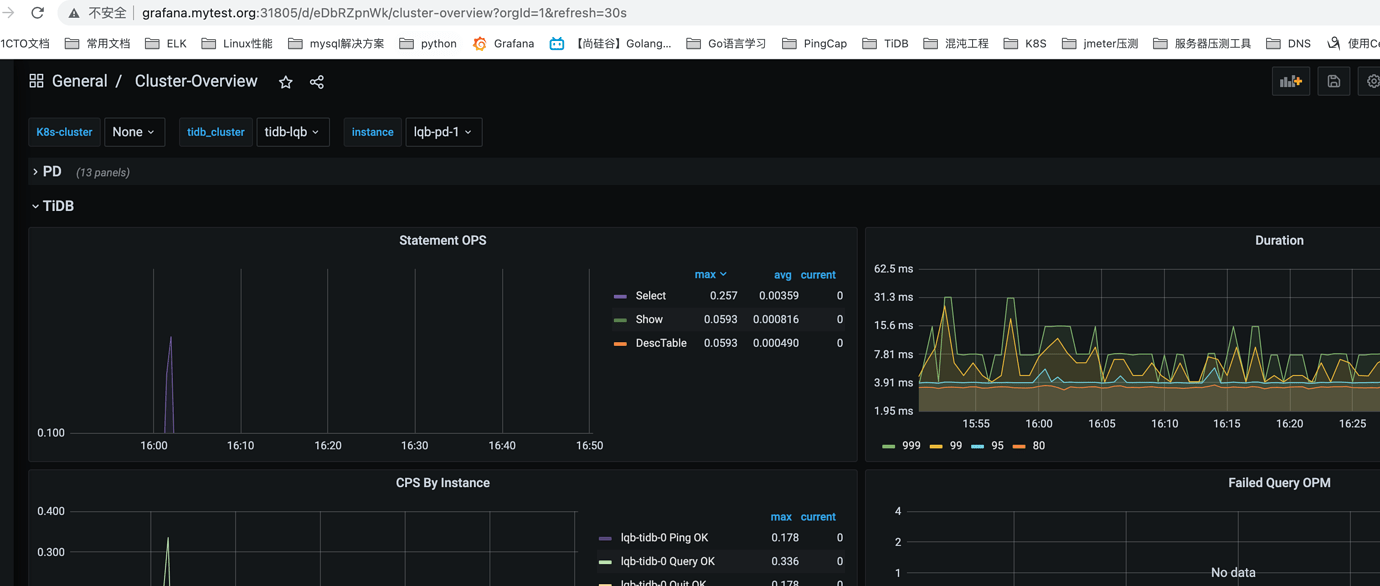
III. Multi-Cluster Monitoring
3.1. Configure Multi-Cluster Monitoring by Modifying YAML File
[root@k8s-master tidb]# cat monitor.yaml
apiVersion: pingcap.com/v1alpha1
kind: TidbMonitor
metadata:
name: monitor
namespace: tidb
spec:
### Configuration for multi-cluster monitoring, key fields are namespace and cluster name
clusters:
- name: lqb
namespace: tidb
- name: yz
namespace: tidb
clusterScoped: true
persistent: true
storageClassName: local-storage
storage: 45G
prometheus:
baseImage: prom/prometheus
version: v2.27.1
service:
type: NodePort
grafana:
baseImage: grafana/grafana
version: 7.5.11
service:
type: NodePort
initializer:
baseImage: pingcap/tidb-monitor-initializer
version: v6.1.0
reloader:
baseImage: pingcap/tidb-monitor-reloader
version: v1.0.1
prometheusReloader:
baseImage: quay.io/prometheus-operator/prometheus-config-reloader
version: v0.49.0
imagePullPolicy: IfNotPresent
3.2. Apply the Configuration
[root@k8s-master tidb]# kubectl apply -f monitor.yaml
tidbmonitor.pingcap.com/monitor configured
[root@k8s-master tidb]#kubectl describe tidbmonitor/monitor -ntidb