Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 源码阅读疑问:tikv rollback_lock 这里,获取到了 SingleRecord 为什么要panic?
Why does the code at line 307 panic?
Can you explain the principle behind it?
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 源码阅读疑问:tikv rollback_lock 这里,获取到了 SingleRecord 为什么要panic?
Why does the code at line 307 panic?
Can you explain the principle behind it?
The function is for rollback, but the if statement checks if write.write_type is not WriteType::Rollback, which is not as expected. I only looked at this part of the code, and I don’t know about the rest.
Here’s the thing, during the rollback process, it was found that the transaction had already been committed, which definitely indicates a bug somewhere. The singleRecord might be a commit record or a rollback record.
This is the call stack found by check_txn_status.
Why does it think it needs to roll back? If it finds that it has already been committed, why panic? Can’t it just assume no rollback is needed?
When checking the transaction status, if it is found that the primary lock has timed out, it will be rolled back immediately. Regarding discovering a commit record during rollback, the reason for panicking is that the TiKV team considers this a very serious issue, indicating that there is definitely a bug somewhere that needs to be identified and resolved immediately.
I looked at the code and understood that it was a bug I caused. The data in the lock cf was not deleted, and the commit record in the write cf was written. This makes the transaction problematic.
Under normal circumstances, the deletion of data in the lock cf and the writing of the commit record in the write cf are done in the same writebatch and submitted to rocksdb together. There should not be a situation where the lock cf is not deleted, but the write cf is committed, so it should panic. It was precisely because of this panic that this bug was discovered. Kudos to the TiDB developers!
To further elaborate:
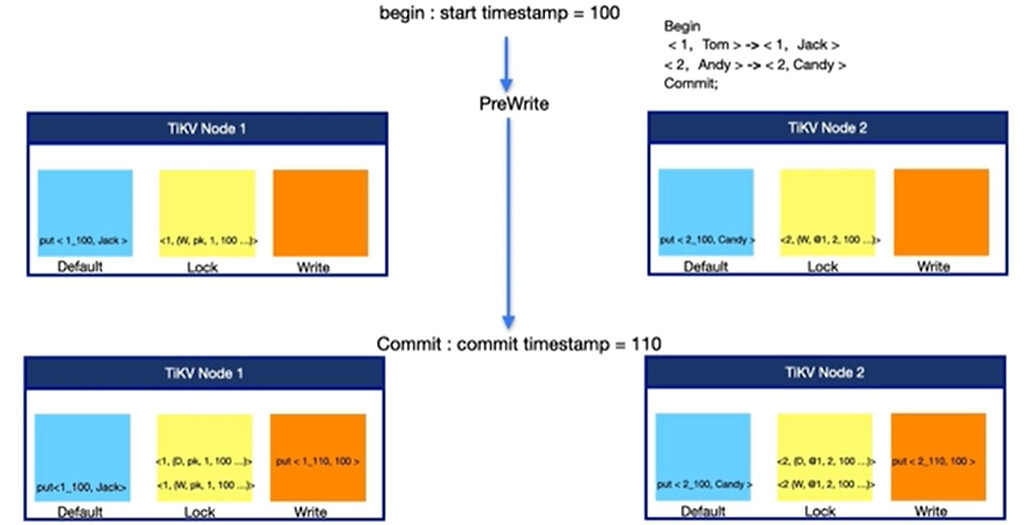
The lock_cf represents the lock. When check_txn_status scans and finds a residual lock with a TTL timeout, it attempts to rollback. Then, when scanning the write cf, it finds a commit record, indicating that the transaction has already been committed. This is abnormal.
In the diagram, the record <1,(D,pk,1,100…)> represents the deletion of the lock, and put<1_110,100> indicates that the transaction was committed at ts 110.
In my inconsistent situation, <1,(D,pk,1,100…)> disappeared, and when getting, I saw <1,(w,pk,1,100)> again.
Here’s a picture:
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.