Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: spark读取tidb,所有select出来的数据都在一个executor中,最后导致了oom
[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version] 6.0.0
[Reproduction Path] What operations were performed to cause the issue: Spark querying TiDB
[Encountered Issue: Problem Phenomenon and Impact]
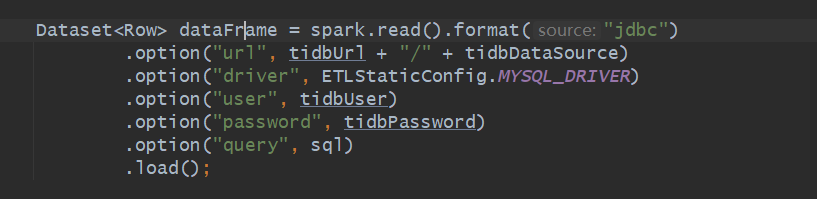
When Spark reads TiDB, all the selected data is in one executor, which eventually leads to OOM. Is this an issue with TiDB itself?
[Resource Configuration]
[Attachment: Screenshot/Logs/Monitoring]
Regarding the issue of Spark reading methods, it is recommended to use TiDB’s TiSpark to read TiDB, which will achieve a more balanced reading capability. If Spark’s JDBC reading method does not specify a partition key (RDD distribution), it will read into a single executor.
If a query returns a very large amount of data, it may cause Spark executor memory to be insufficient, triggering an OOM error. In this case, you need to optimize the query statement, refining the query conditions to the smallest range to reduce the amount of data returned.
You can refer to this for manual partitioning with JDBC: JDBC To Other Databases - Spark 3.5.1 Documentation
If the query involves a large amount of data, you can try optimizing the query conditions, such as adding indexes and using appropriate filtering conditions, to reduce the amount of data read.