Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: lightning全量导入时卡住快一天,求助!!!
[TiDB Usage Environment] Production
[Encountered Problem] Dumpling downloaded 2.7T of data in full, and Lightning completed the full import of creating the database and tables. However, when executing the insert statement, it ran for more than 5 hours and stopped moving after 2022/10/24 20:05.
Lightning script:
#!/bin/bash
nohup /home/tidb/tidb-toolkit-v5.0.1-linux-amd64/bin/tidb-lightning -config tidb-lightning.toml > /home/tidb/tidb-toolkit-v5.0.1-linux-amd64/bin/tidb-lightning.log 2>&1 &
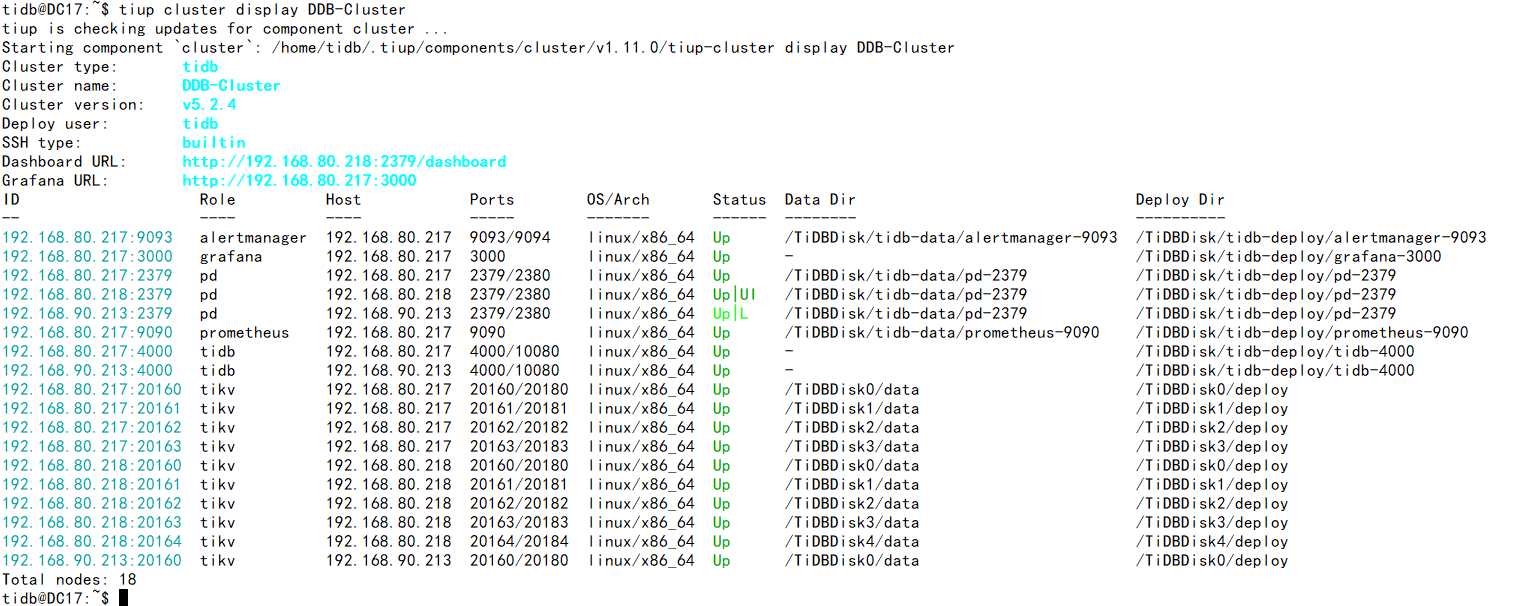
TiUP Cluster Display Information:
Download the full dump from TiDB v3.0.3 using Dumpling and import it into TiDB v5.2.4 using Lightning.
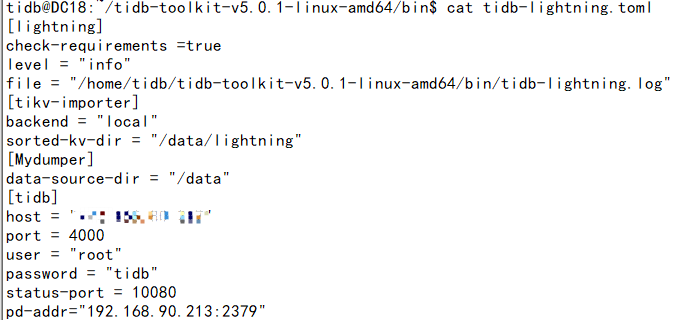
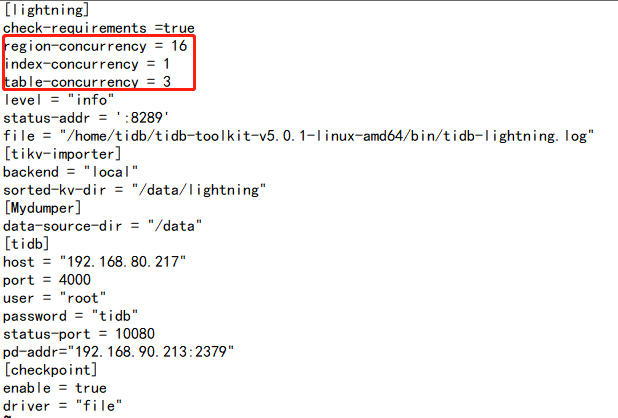
The configuration file of tidb-lightning
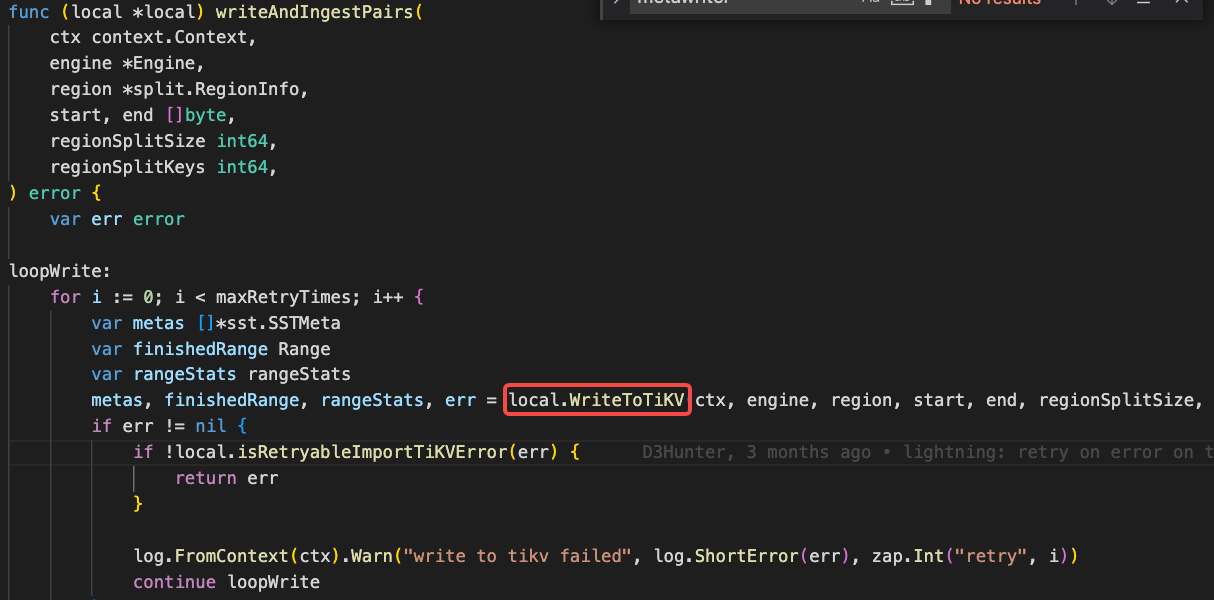
It looks like both split and scatter have been completed. The next step should be importing kv into tikv.
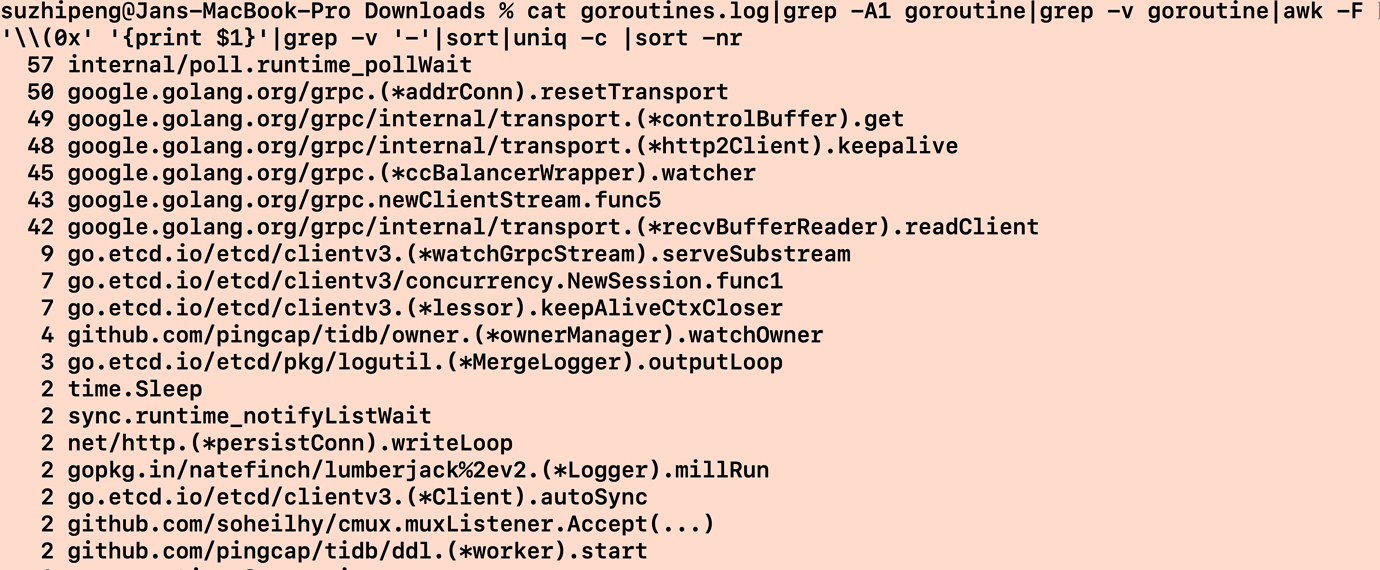
You can check the logs on the tikv side or dump the routine of lightning to see where it is stuck.
FYI: TiDB Lightning 常见问题 | PingCAP 文档中心
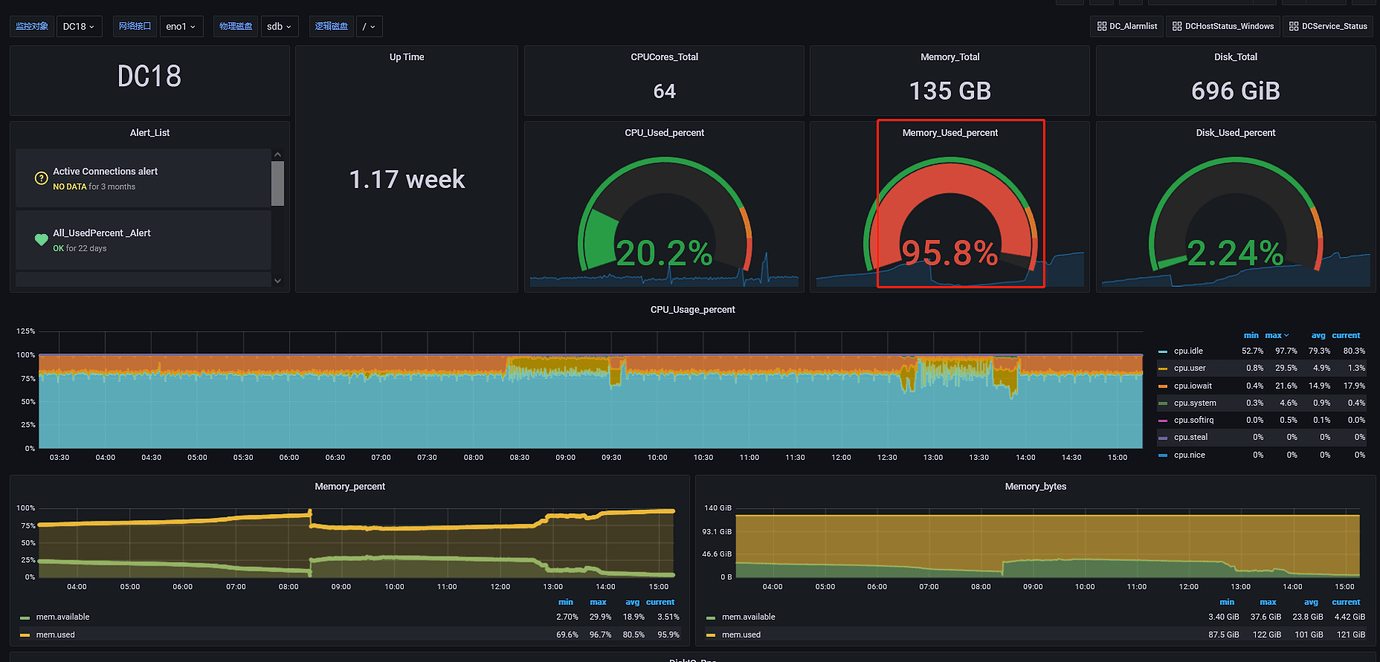
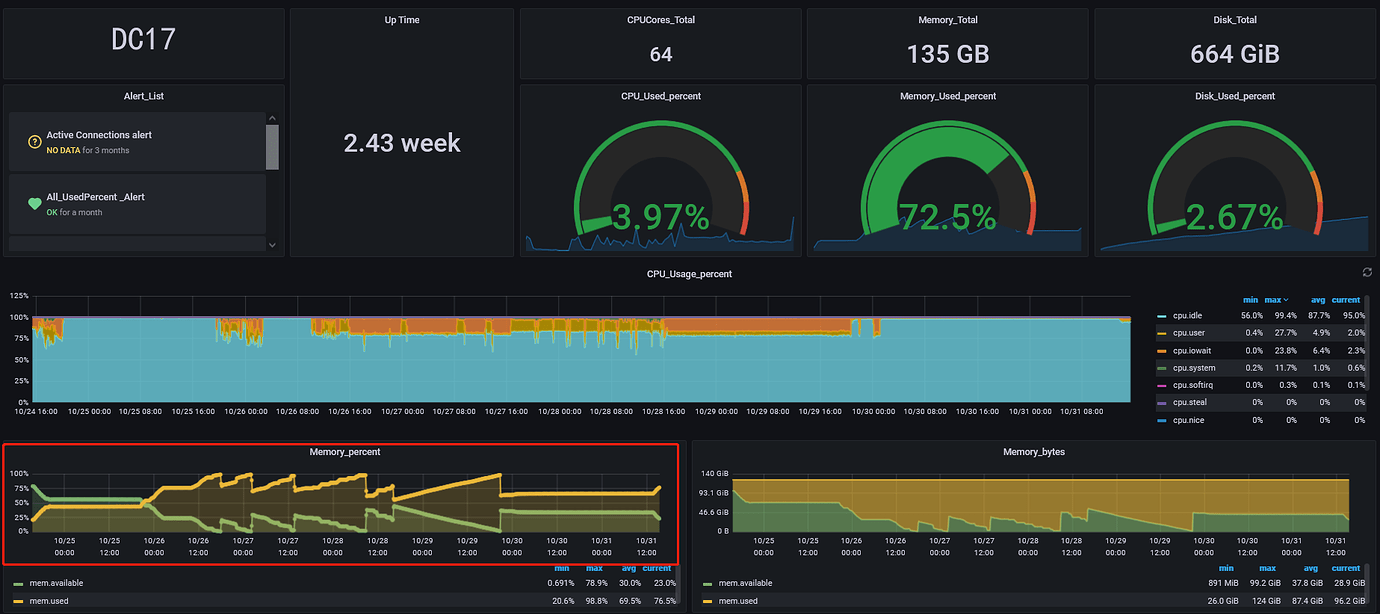
The memory usage of the server executing the lightning script during the full import is at most 79.6%, and the CPU usage is also not high.
tikv log, please take a look.
There is a warning about transmission errors in PD.
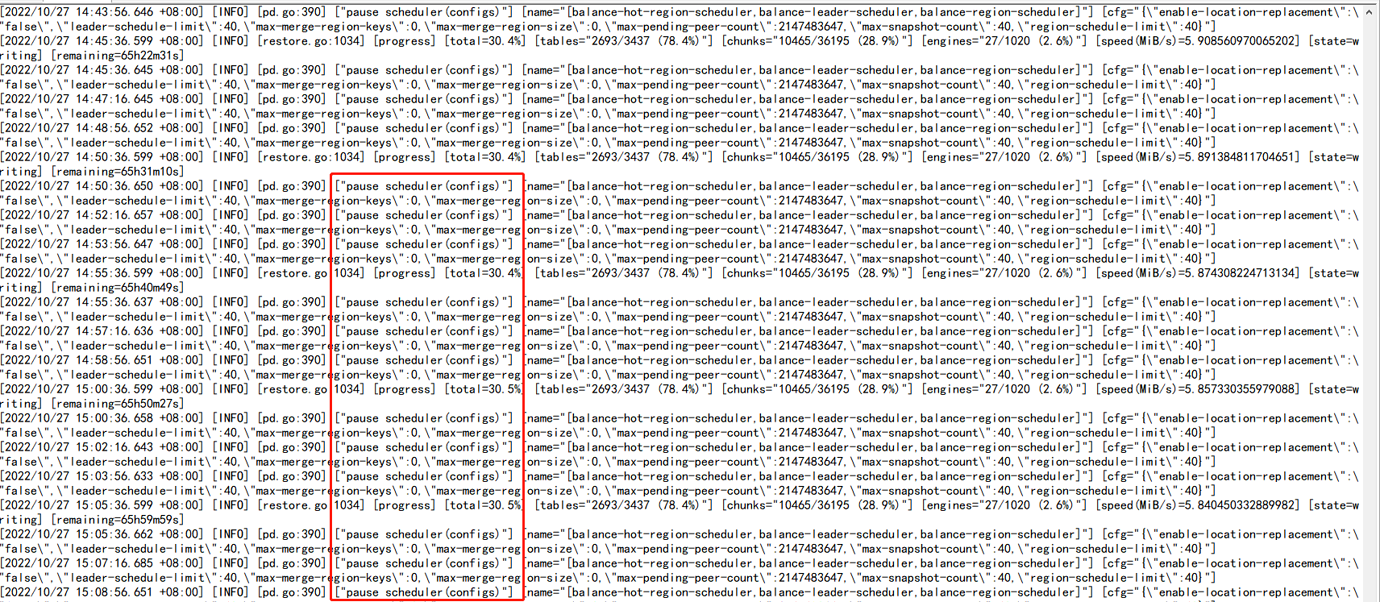
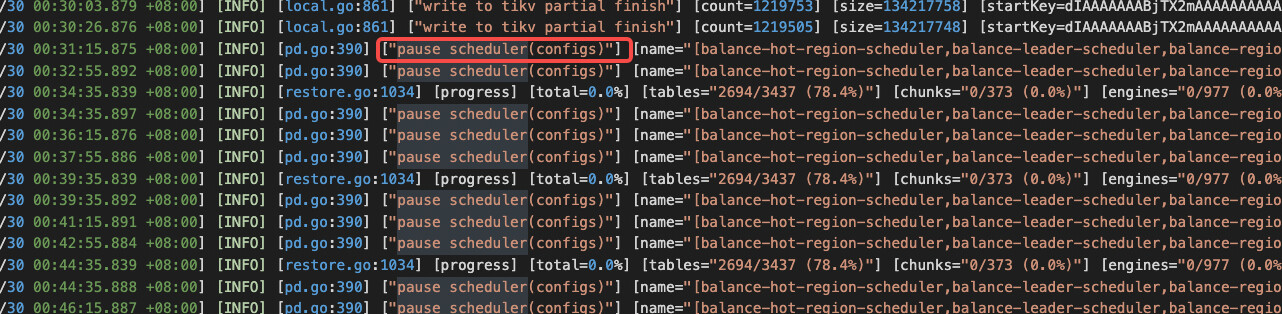
The import speed is particularly slow during lightning import, and it has been pausing scheduling operations;
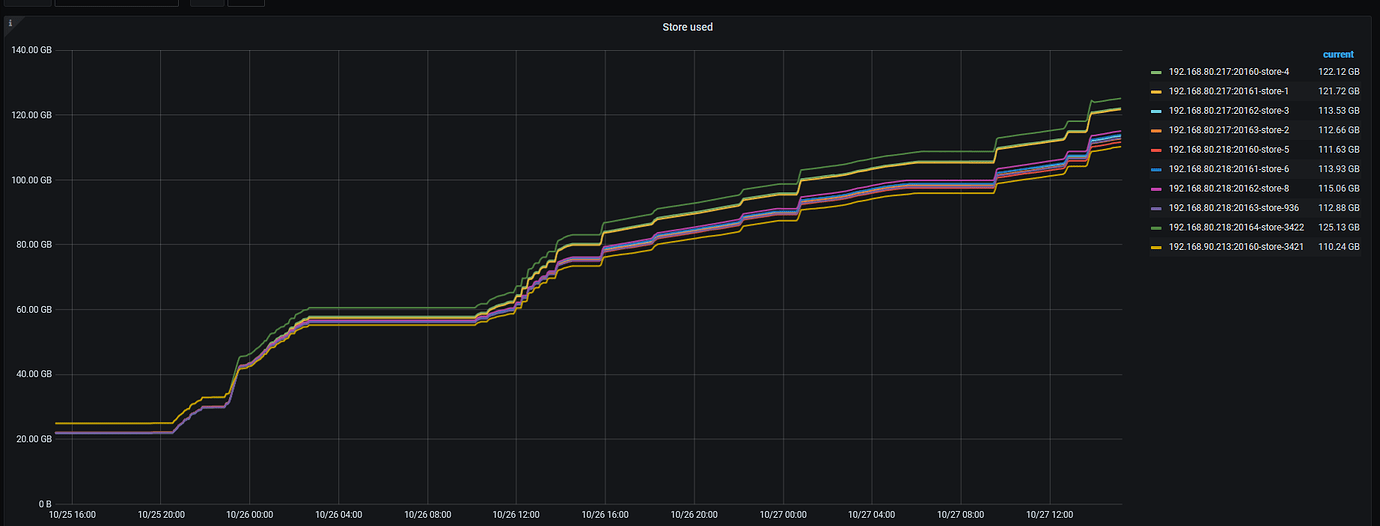
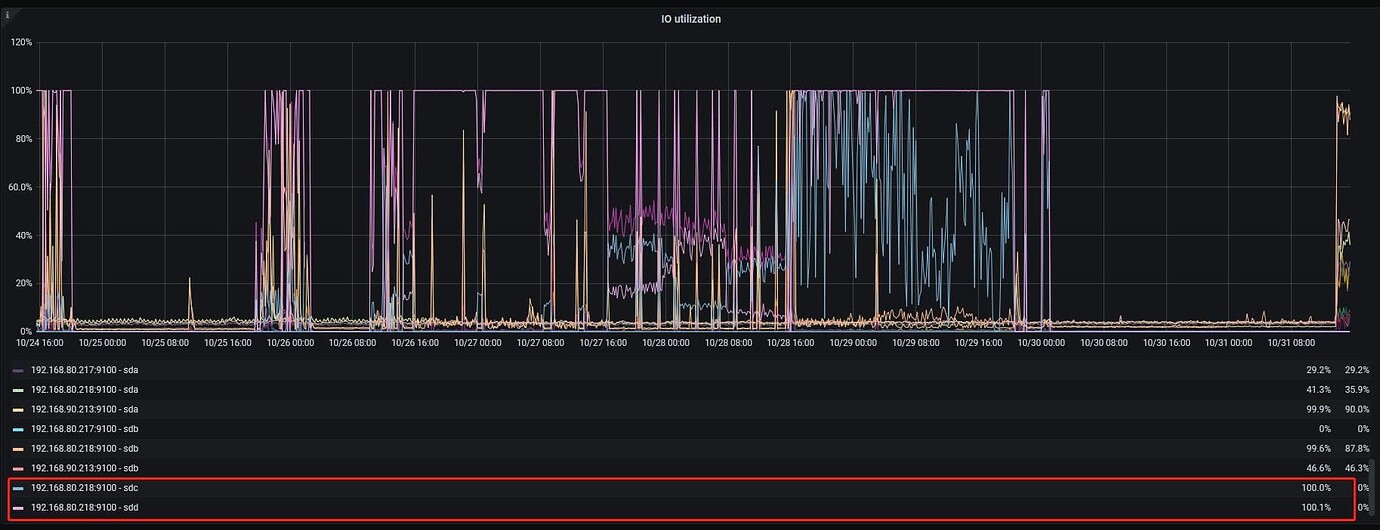
The total amount of data uploaded in two days is as follows
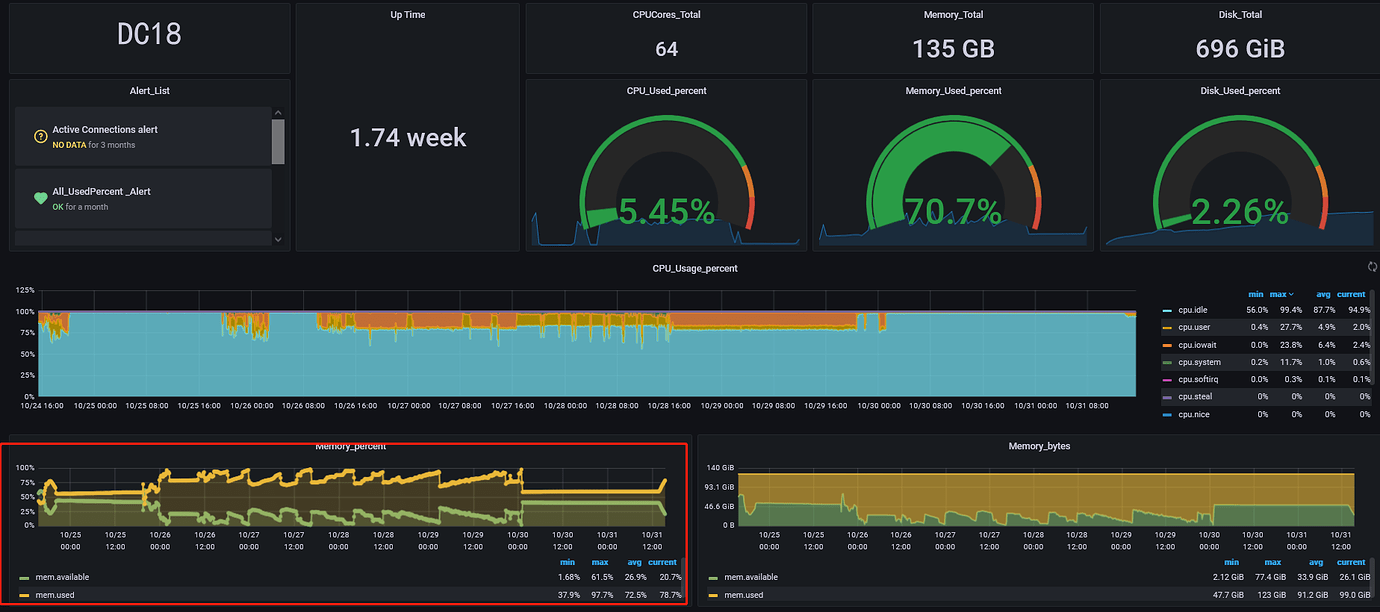
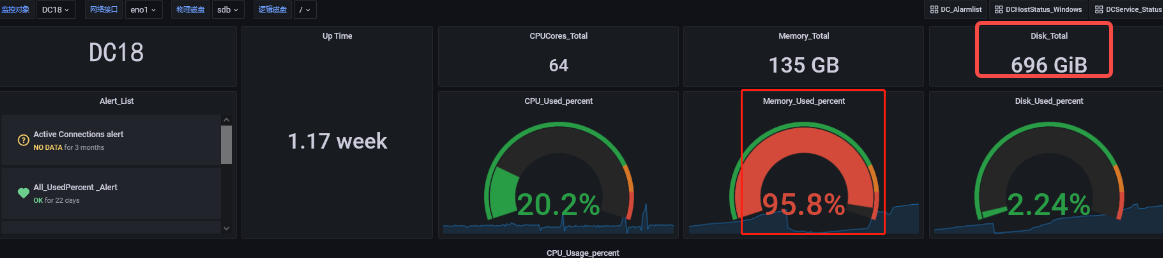
DC18 server is tikv, and it is also the server where lightning executes the import. The memory has been very high, so I lowered the region concurrency of lightning. If I increase it, the lightning process will exit after a while;
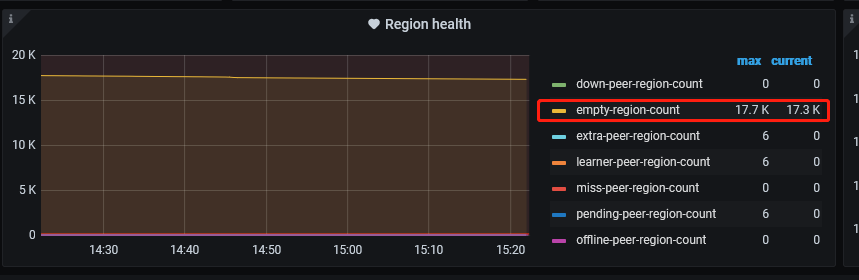
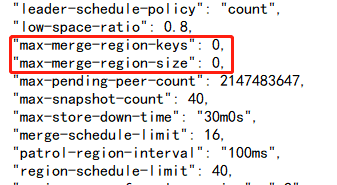
I found that there are many empty regions in the imported cluster. After adjusting max-merge-region-keys and max-merge-region-size, the lightning process will trigger pause scheduling after a while. The number of empty regions will stop decreasing. When I check the configuration again, I find that the configured parameters are cleared to 0;
 I have a few questions to consult:
I have a few questions to consult:
- Will the lightning process increase the number of empty regions?
- Will an increase in empty region count affect the import speed?
- What is causing the slow import speed in the current situation? How can the import speed be increased?
There are warnings during the transmission, and errors occur when writing to KV. Can you help me check it out and how to solve this problem specifically? Dumpling downloaded 2.7T of data, and it has been transmitting for more than a week but hasn’t finished yet. Now there are errors in writing. Could you please look into the issue of the very slow import rate and the writing errors? Thank you. Compensation can be provided, as the online business is quite urgent. Seeking help.
When TiDB encounters slow SQL, it will continuously OOM (Out of Memory).
The default configuration of TiDB and the default configuration of TiKV are both intended for use on standalone machines. If you want to use a mixed configuration, you need to modify the parameters yourself. The official documentation has the details.
-
After checking, it was found that there were many empty regions in the imported cluster. After adjusting max-merge-region-keys and max-merge-region-size, the lightning process would trigger pause scheduling after a period of time. The number of empty regions would decrease and then stop. Upon checking the configuration again, it was found that the configured parameters were reset to 0.
→ Before importing with lightning local, scheduling is usually paused. Pausing scheduling helps with fast import and avoids region and leader changes caused by merge or split. As for the XXX-keys and XXX-size parameters being reset to 0, this is usually related to an abnormal exit of lightning. Because lightning local first pauses the schedule and resumes it after the import is complete. If I remember correctly, it should be reset to 0 during the import.
-
Dumpling downloaded 2.7T of data in full, and lightning completed the creation of the database and tables in full. When executing the insert statement, it ran for more than 5 hours and then stopped moving after 20:05 on 2022/10/24.
→ I see that the configuration file uses local mode, so there should be no execution of insert statements. It should be a direct import of csv–>sst–>tikv files.
-
From the profile, I didn’t see any useful information, but the screenshot shows tcp connection reset by peer, indicating some issues with the TCP connection. However, the extent to which this affects import performance is uncertain. It’s best to collect a graph that shows execution time consumption to see which function is stuck.
curl http://{TiDBIP}:10080/debug/zip?seconds=60 --output debug.zip
Speaking of slow imports:
- Is there any abnormal point in lightning.log?
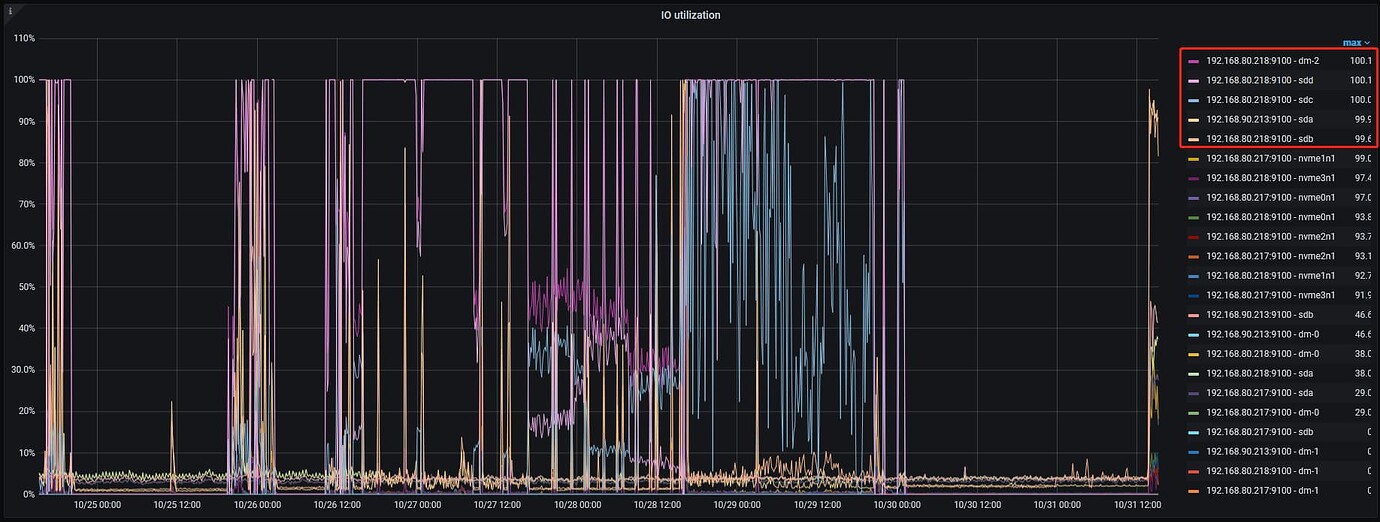
- Have you checked the disk load situation?
- From the CPU idle, it seems that not much performance was utilized during the local translation from csv to sst. Have you checked the performance of the downstream TiKV?
Please upload a copy of lightning’s own log first. 
btw: Under normal circumstances, it should be a bit slower than this speed → TiDB Lightning 导入模式 | PingCAP 归档文档站
Go check his chat history in the group. He deployed 4 TiKV and 1 TiDB on one machine without changing the configuration. The TiKVs are competing for memory among themselves. OOM kills the one with the largest memory usage. Then systemctl restarts the killed TiKV. That’s his problem.
So you can see from his graph that it keeps restarting and OOMing within a few hours due to insufficient memory. A single TiKV cache by default occupies 40% of the total memory. If he starts 2 instances, it will OOM, let alone starting 4 instances.
-
This pause operation keeps repeating, and the reason is currently unclear. After starting Lightning, did you manually modify the scheduler or enable the scheduler?
-
Oh, we need to solve the OOM issue.
-
Shouldn’t Lightning and Dumpling be placed in the same directory?
→ No need, Dumpling and Lightning are not operating simultaneously, right? As long as they are not operating at the same time, there won’t be IO resource contention, but it’s best if both are on SSDs. However, the main issue now seems to be that after data is written to TiKV, it can’t handle the OOM. You can analyze TiKV memory consumption besides blockcache, and check the TiKV-details panel (is it because IO is maxed out and all data is held in memory? etc.)
-
It’s not recommended to split them, right? Have you already imported 600GB of data? Or almost none? Splitting into different directories is meaningless.
I think the current issues are:
- Identify the root cause of memory consumption to prevent TiKV OOM, and ensure continuous data import (even if it’s slow);
- Find a way to solve the TiKV IO saturation issue. If you can’t change the disk, find a way to reduce concurrency;
- If some data has already been imported, Lightning has a checkpoint mechanism to support resuming from breakpoints. Try to reuse it to save time, and focus on solving the TiKV side issues first.